Файлы и файловые системы
Важным шагом в развитии именно информационных систем явился переход к использованию централизованных систем управления файлами. С точки зрения прикладной программы, файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Правила именования файлов, способ доступа„к данным, хранящимся в файле, и структура этих данных зависят от конкретной системы управления файлами и, возможно, от типа файла. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в соответствующие адреса во внешней памяти и обеспечение доступа к данным.
Конкретные модели файлов, используемые в системе управления файлами, мы рассмотрим далее, когда перейдем к физическим способам организации баз данных, а на этом этапе нам достаточно знать, что пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций:
создать файл (требуемого типа и размера);
открыть ранее созданный файл;
прочитать из файла некоторую запись (текущую, следующую, предыдущую, первую, последнюю);
записать в файл на место текущей записи новую, добавить новую запись в конец файла.
В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким. Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала, система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы, а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуации характеризовалась как зависимость программ от данных. Для информационных систем характерным является наличие большого числа различных пользователей (программ), каждый из которых имеет свои специфические алгоритмы обработки информации, хранящейся в одних и тех же файлах.
Изменение структуры файла, которое было
Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Это было первым существенным недостатком файловых систем, который явился толчком к созданию новых систем хранения и управления информацией.
Далее, поскольку файловые системы являются общим хранилищем файлов, принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю. В большинстве современных систем управления файлами применяется подход к защите файлов, впервые реализованный в ОС UNIX. В этой ОС каждому зарегистрированному пользователю соответствует пара целочисленных идентификаторов; идентификатор группы, к которой относится этот пользователь, и его собственный идентификатор в группе. При каждом файле хранится полный идентификатор пользователя, который создал этот файл, и фиксируется, какие действия с файлом может производить его создатель, какие действия с файлом доступны для других пользователей той же группы и что могут делать с файлом пользователи других групп. Администрирование режимом доступа к файлу в основном выполняется его создателем-владельцем. Для множества файлов, отражающих информационную модель одной предметной области, такой децентрализованный принцип управления доступом вызывал дополнительные трудности. И отсутствие централизованных методов управления доступом к информации послужило еще одной причиной разработки СУБД.
Следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами. В общем случае системы управления файлами обеспечивали режим многопользовательского доступа. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом.
Если все пользователи собираются только
Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу.
В системах управления файлами обычно применялся следующий подход. В операции открытия файла (первой и обязательной операции, с которой должен начинаться сеанс работы с файлом) среди прочих параметров указывался режим работы (чтение или изменение). Если к моменту выполнения этой операции некоторым пользовательским процессом PR1 файл был уже открыт другим процессом PR2 в режиме изменения, то в зависимости от особенностей системы процессу PR1 либо сообщалось о невозможности открытия файла, либо он блокировался до тех пор, пока в процессе PR2 не выполнялась операция закрытия файла.
При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена.
Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД).
История развития баз данных
В истории вычислительной техники можно проследить развитие двух основных областей ее использования. Первая область — применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, появлению языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Характерной особенностью данной области применения вычислительной техники является наличие сложных алгоритмов обработки, которые применяются к простым по структуре данным, объем которых сравнительно невелик.
Вторая область, которая непосредственно относится к нашей теме, — это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Информационная система представляет собой программно-аппаратный комплекс, обеспечивающий выполнение следующих функций:
надежное хранение информации в памяти компьютера;
выполнение специфических для данного приложения преобразований информации и вычислений;
предоставление пользователям удобного и легко осваиваемого интерфейса.
Обычно такие системы имеют дело с большими объемами информации, имеющей достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, автоматизированные системы управления предприятиями, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными. Говорить о надежном и долговременном хранении информации можно только при наличии запоминающих устройств, сохраняющих информацию после выключения электрического питания. Оперативная (основная) память компьютеров этим свойством обычно не обладает.
В первых компьютерах использовались два
В первых компьютерах использовались два вида устройств внешней памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно велика, но по своей физической природе они обеспечивали последовательный доступ к данным. Магнитные же барабаны (они ближе всего к современным магнитным дискам с фиксированными головками) давали возможность произвольного доступа к данным, но имели ограниченный объем хранимой информации.
Эти ограничения не являлись слишком существенными для чисто численных расчетов. Даже если программа должна обработать (или произвести) большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти (например, на последовательной магнитной ленте), обеспечивающее эффективное выполнение этой программы. Однако в информационных системах совокупность взаимосвязанных информационных объектов фактически отражает модель объектов реального мира. А потребность пользователей в информации, адекватно отражающей состояние реальных объектов, требует сравнительно быстрой реакции системы на их запросы. И в этом случае наличие сравнительно медленных устройств хранения данных, к которым относятся магнитные ленты и барабаны, было недостаточным.
Можно предположить, что именно требования нечисловых приложений вызвали появление съемных магнитных дисков с подвижными головками, что явилось революцией в истории вычислительной техники. Эти устройства внешней памяти обладали существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную скорость доступа к данным в режиме произвольной выборки, а возможность смены дискового пакета на устройстве позволяла иметь практически неограниченный архив данных.
С появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы).Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти.
Эпоха персональных компьютеров
Персональные компьютеры стремительно ворвались в нашу жизнь и буквально перевернули наше представление о месте и роли вычислительной техники в жизни общества. Теперь компьютеры стали ближе и доступнее каждому пользователю. Исчез благоговейный страх рядовых пользователей перед непонятными и сложными языками программирования. Появилось множество программ, предназначенных для работы неподготовленных пользователей. Эти программы были просты в использовании и интуитивно понятны: это прежде всего различные редакторы текстов, электронные таблицы и другие. Простыми и понятными стали операции копирования файлов и перенос информации с одного компьютера на другой, распечатка текстов, таблиц и других документов. Системные программисты были отодвинуты на второй план. Каждый пользователь мог себя почувствовать полным хозяином этого мощного и удобного устройства, Позволяющего автоматизировать многие аспекты деятельности. И, конечно, это сказалось и на работе с базами данных. Появились программы, которые назывались системами управления базами данных и позволяли хранить значительные объемы информации, они имели удобный интерфейс для заполнения данных, встроенные средства для генерации различных отчетов. Эти программы позволяли автоматизировать многие учетные функции, которые раньше велись вручную. Постоянное снижение цен на персональные компьютеры сделало их доступными не только для организаций и фирм, но и для отдельных пользователей. Компьютеры стали инструментом для ведения документации и собственных учетных функций. Это все сыграло как положительную, так и отрицательную роль в области развития баз данных. Кажущаяся простота и доступность персональных компьютеров и их программного обеспечения породила множество дилетантов. Эти разработчики, считая себя знатоками, стали проектировать недолговечные базы данных, которые не учитывали многих особенностей объектов реального мира. Много было создано систем-однодневок, которые не отвечали законам развития и взаимосвязи реальных объектов.
Однако доступность персональных компьютеров заставила
Однако доступность персональных компьютеров заставила пользователей из многих областей знаний, которые ранее не применяли вычислительную технику в своей деятельности, обратиться к ним. И спрос на развитые удобные программы обработки данных заставлял поставщиков программного обеспечения поставлять все новые системы, которые принято называть настольными (desktop) СУБД. Значительная конкуренция среди поставщиков заставляла совершенствовать эти системы, предлагая новые возможности, улучшая интерфейс и быстродействие систем, снижая их стоимость. Наличие на рынке большого -числа СУБД, выполняющих сходные функции, потребовало разработки методов экспорта-импорта данных для этих систем и открытия форматов хранения данных.
Но и в этот период появлялись любители, которые вопреки здравому смыслу разрабатывали собственные СУБД, используя стандартные языки программирования. Это был тупиковый вариант, потому что дальнейшее развитие показало, что перенести данные из нестандартных форматов в новые СУБД было гораздо труднее, а в некоторых случаях требовало таких трудозатрат, что легче было бы все разработать заново, но данные все равно надо было переносить на новую более перспективную СУБД. И это тоже было результатом недооценки тех функций, которые должна была выполнять СУБД.
Особенности этого этапа следующие:
Все СУБД были рассчитаны на создание БД в основном с монопольным доступом. И это понятно. Компьютер персональный, он не был подсоединен к сети, и база данных на нем создавалась для работы одного пользователя. В редких случаях предполагалась последовательная работа нескольких пользователей, например, сначала оператор, который вводил бухгалтерские документы, а потом главбух, который определял проводки, соответствующие первичным документам.
Большинство СУБД имели развитый и удобный пользовательский интерфейс. В большинстве существовал интерактивный режим работы с БД как в рамках описания БД, так и в рамках проектирования запросов. Кроме того, большинство СУБД предлагали развитый и удобный инструментарий для разработки готовых приложений без программирования.
Инструментальная среда состояла из готовых
Инструментальная среда состояла из готовых элементов приложения в виде шаблонов экранных форм, отчетов, этикеток (Labels), графических конструкторов запросов, которые достаточно просто могли быть собраны в единый комплекс.
Во всех настольных СУБД поддерживался только внешний уровень представления реляционной модели, то есть только внешний табличный вид структур данных.
При наличии высокоуровневых языков манипулирования данными типа реляционной алгебры и SQL в настольных СУБД поддерживались низкоуровневые языки манипулирования данными на уровне отдельных строк таблиц.
В настольных СУБД отсутствовали средства поддержки ссылочной и структурной целостности базы данных. Эти функции должны были выполнять приложения, однако скудость средств разработки приложений иногда не позволяла это сделать, и в этом случае эти функции должны были выполняться пользователем, требуя от него дополнительного контроля при вводе и изменении информации, хранящейся в БД.
Наличие монопольного режима работы фактически привело к вырождению функций администрирования БД и в связи с этим — к отсутствию инструментальных средств администрирования БД.
И, наконец, последняя и в настоящий момент весьма положительная особенность — это сравнительно скромные требования к аппаратному обеспечению со стороны настольных СУБД. Вполне работоспособные приложения, разработанные, например, на Clipper, работали на PC 286.
В принципе, их даже трудно назвать полноценными СУБД. Яркие представители этого семейства — очень широко использовавшиеся до недавнего времени СУБД Dbase (DbaseIII+, DbaselV), FoxPro, Clipper, Paradox.
Контрольные вопросы
Найдите сходства первого и четвертого этапов развития.
Найдите отличия первого и третьего этапов развития.
Если при использовании файловых систем для параллельного доступа пользователей создавать копии файлов для каждого пользователя, может ли это ускорить параллельную работу с информацией?
Перспективы развития систем управления базами данных
Этот этап характеризуется появлением новой технологии доступа к данным — интранет. Основное отличие этого подхода от технологии клиент-сервер состоит в том, что отпадает необходимость использования специализированного клиентского программного обеспечения. Для работы с удаленной базой данных используется стандартный броузер Интернета, например Microsoft Internet Explorer или Netscape Navigator, и для конечного пользователя процесс обращения к данным происходит аналогично скольжению по Всемирной Паутине (см. рис. 1.1). При этом встроенный в загружаемые пользователем HTML-страницы код, написанный обычно на языке Java, Java-script, Perl и других, отслеживает все действия пользователя и транслирует их в низкоуровневые SQL-запросы к базе данных, выполняя, таким образом, ту работу, которой в технологии клиент-сервер занимается клиентская программа. Удобство данного подхода привело к тому, что он стал использоваться не только для удаленного доступа к базам данных, но и для пользователей локальной сети предприятия. Простые задачи обработки данных, не связанные со сложными алгоритмами, требующими согласованного изменения данных во многих взаимосвязанных объектах, достаточно просто и эффективно могут быть построены по данной архитектуре. В этом случае для подключения нового пользователя к возможности использовать данную задачу не требуется установка дополнительного клиентского программного обеспечения. Однако алгоритмически сложные задачи рекомендуется реализовывать в архитектуре «клиент-сервер» с разработкой специального клиентского программного обеспечения.
У каждого из вышеперечисленных подходов к работе с данными есть свои достоинства и свои недостатки, которые и определяют область применения того или иного метода, и в настоящее время все подходы широко используются.
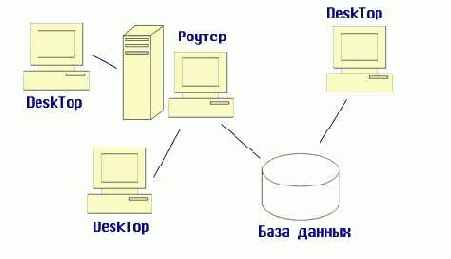
Рис. 1.1. Взаимодействие с базой данных в технологии интранет
Первый этап — базы данных на больших ЭВМ
История развития СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД система IMS фирмы IBM. В 1975 году появился первый стандарт ассоциации по языкам систем обработки данных — Conference of Data System Languages (CODASYL), который определил ряд фундаментальных понятий в теории систем баз данных, которые и до сих пор являются основополагающими для сетевой модели данных.
В дальнейшее развитие теории баз данных большой вклад был сделан американским математиком Э. Ф. Коддом, который является создателем реляционной модели данных. В 1981 году Э. Ф. Кодд получил за создание реляционной модели и реляционной алгебры престижную премию Тьюринга Американской ассоциации по вычислительной технике.
Менее двух десятков лет прошло с этого момента, но стремительное развитие вычислительной техники, изменение ее принципиальной роли в жизни общества, обрушившийся бум персональных ЭВМ и, наконец, появление мощных рабочих станций и сетей ЭВМ повлияло также и на развитие технологии баз данных. Можно выделить четыре этапа в развитии данного направления в обработке данных. Однако необходимо заметить, что все же нет жестких временных ограничений в этих этапах: они плавно переходят один в другой и даже сосуществуют параллельно, но тем не менее выделение этих этапов позволит более четко охарактеризовать отдельные стадии развития технологии баз данных, подчеркнуть особенности, специфичные для конкретного этапа.
Первый этап развития СУБД связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и мини-ЭВМ типа PDP11 (фирмы Digital Equipment Corporation — DEC), разных моделях HP (фирмы Hewlett Packard).
Базы данных хранились во внешней памяти центральной ЭВМ, пользователями этих баз данных были задачи, запускаемые в основном в пакетном режиме. Интерактивный режим доступа обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами (процессором, внешней памятью) и служили только устройствами ввода-вывода для центральной ЭВМ.
к БД писались на различных
Программы доступа к БД писались на различных языках и запускались как обычные числовые программы. Мощные операционные системы обеспечивали возможность условно параллельного выполнения всего множества задач. Эти системы можно было отнести к системам распределенного доступа, потому что база данных была централизованной, хранилась на устройствах внешней памяти одной центральной ЭВМ, а доступ к ней поддерживался от многих пользователей-задач.
Особенности этого этапа развития выражаются в следующем:
Все СУБД базируются на мощных мультипрограммных операционных системах (MVS, SVM, RTE, OSRV, RSX, UNIX), поэтому в основном поддерживается работа с централизованной базой данных в режиме распределенного доступа.
Функции управления распределением ресурсов в основном осуществляются операционной системой (ОС).
Поддерживаются языки низкого уровня манипулирования данными, ориентированные на навигационные методы доступа к данным.
Значительная роль отводится администрированию данных.
Проводятся серьезные работы по обоснованию и формализации реляционной модели данных, и была создана первая система (System R), реализующая идеологию реляционной модели данных.
Проводятся теоретические работы по оптимизации запросов и управлению распределенным доступом к централизованной БД, было введено понятие транзакции.
Результаты научных исследований открыто обсуждаются в печати, идет мощный поток общедоступных публикаций, касающихся всех аспектов теории и практики баз данных, и результаты теоретических исследований активно внедряются в коммерческие СУБД.
Появляются первые языки высокого уровня для работы с реляционной моделью данных. Однако отсутствуют стандарты для этих первых языков.
Распределенные базы данных
Хорошо известно, что история развивается по спирали, поэтому после процесса «персонализации» начался обратный процесс — интеграция. Множится количество локальных сетей, все больше информации передается между компьютерами, остро встает задача согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных, возникают задачи, связанные с параллельной обработкой транзакций — последовательностей операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных баз данных, сохраняющих все преимущества настольных СУБД и в то же время позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Особенности данного этапа:
Практически все современные СУБД обеспечивают поддержку полной реляционной модели, а именно:
структурной целостности — допустимыми являются только данные, представленные в виде отношений реляционной модели;
языковой целостности, то есть языков манипулирования данными высокого уровня (в основном SQL);
ссылочной целостности, контроля за соблюдением ссылочной целостности в течение всего времени функционирования системы, и гарантий невозможности со стороны СУБД нарушить эти ограничения.
Большинство современных СУБД рассчитаны на многоплатформенную архитектуру, то есть они могут работать на компьютерах с разной архитектурой и под разными операционными системами, при этом для пользователей доступ к данным, управляемым СУБД на разных платформах, практически неразличим.
Необходимость поддержки многопользовательской работы с базой данных и возможность децентрализованного хранения данных потребовали развития средств администрирования БД с реализацией общей концепции средств защиты данных.
Потребность в новых реализациях вызвала создание серьезных теоретических трудов по оптимизации реализаций распределенных БД и работе с распределенными транзакциями и запросами с внедрением полученных результатов в коммерческие СУБД.
Для того чтобы не потерять
Для того чтобы не потерять клиентов, которые ранее работали на настольных СУБД, практически все современные СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития.
Именно к этому этапу можно отнести разработку ряда стандартов в рамках языков описания и манипулирования данными начиная с SQL89, SQL92, SQL99 и технологий по обмену данными между различными СУБД, к которым можно отнести и протокол ODBC (Open DataBase Connectivity), предложенный фирмой Microsoft.
Именно к этому этапу можно отнести начало работ, связанных с концепцией объектно-ориентированных БД — ООБД. Представителями СУБД, относящимся ко второму этапу, можно считать MS Access 97 и все современные серверы баз данных Oracle7.3,Oracle 8.4 MS SQL6.5, MS SQL7.0, System 10, System 11, Informix, DB2, SQL Base и другие современные серверы баз данных, которых в настоящий момент насчитывается несколько десятков.
Архитектура базы данных. Физическая и логическая независимость
Терминология в СУБД, да и сами термины «база данных» и «банк данных» частично заимствованы из финансовой деятельности. Это заимствование — не случайно и объясняется тем, что работа с информацией и работа с денежными массами во многом схожи, поскольку и там и там отсутствует персонификация объекта обработки: две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы, как два одинаковых байта (естественно, за исключением серийных номеров). Вы можете положить деньги на некоторый счет и предоставить возможность вашим родственникам или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать ваши расходы с вашего счета или получить их наличными в другом банке, и это будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую вы имели, когда клали их на ваш счет.
В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 2.1:
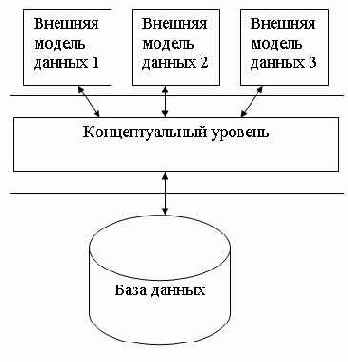
Рис. 2.1. Трехуровневая модель системы управления базой данных, предложенная ANSI
Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое «видение» данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров.
Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных.
Как любая модель, концептуальная модель
Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира.
Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации.
Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем.
Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных.
Основные понятия и определения
Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Сухой канцелярский язык труден для восприятия, но эти определения четко разграничивают назначение всех трех базовых понятий, и мы можем принять их за основу.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистемы складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.
Классификация моделей данных
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
На рис. 2.3 представлена классификация моделей данных.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
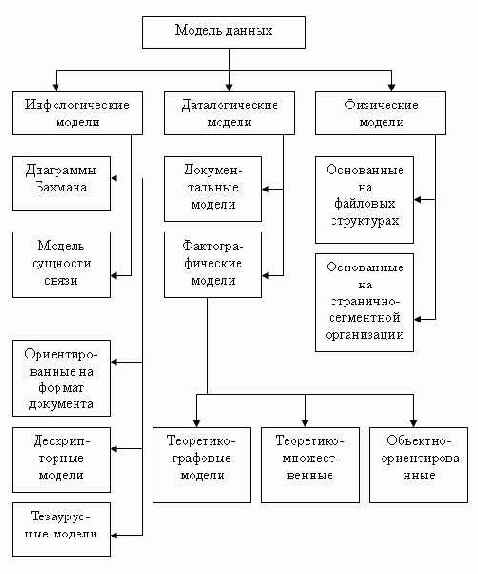
Рис. 2.3. Классификация моделей данных
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне.
к ним внешние модели называются
По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки — SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х годах. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
и удобный, чем SGML, язык
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и, одновременно с этим, удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. То есть сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных.В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
Основные функции группы администратора БД
Анализ предметной области: описание предметной области, выявление ограничений целостности, определение статуса (доступности, секретности) информации, определение потребностей пользователей, определение соответствия «данные—пользователь», определение объемно-временных характеристик обработки данных.
Проектирование структуры БД: определение состава и структуры файлов БД и связей между ними, выбор методов упорядочения данных и методов доступа к информации, описание БД на языке описания данных (ЯОД).
Задание ограничений целостности при описании структуры БД и процедур обработки БД:
задание декларативных ограничений целостности, присущих предметной области;
определение динамических ограничений целостности, присущих предметной области в процессе изменения информации, хранящейся в БД;
определение ограничений целостности, вызванных структурой БД;
разработка процедур обеспечения целостности БД при вводе и корректировке данных;
определение ограничений целостности при параллельной работе пользователей в многопользовательском режиме.
Первоначальная загрузка и ведение БД:
разработка технологии первоначальной загрузки БД, которая будет отличаться от процедуры модификации и дополнения данными при штатном использовании базы данных;
разработка технологии проверки соответствия введенных данных реальному состоянию предметной области. База данных моделирует реальные объекты некоторой предметной области и взаимосвязи между ними, и на момент начала штатной эксплуатации эта модель должна полностью соответствовать состоянию объектов предметной области на данный момент времени;
в соответствии с разработанной технологией первоначальной загрузки может понадобиться проектирование системы первоначального ввода данных.
Защита данных:
определение системы паролей, принципов регистрации пользователей, создание групп пользователей, обладающих одинаковыми правами доступа к данным;
разработка принципов защиты конкретных данных и объектов проектирования; разработка специализированных методов кодирования информации при ее циркуляции в локальной и глобальной информационных сетях;
исследование случаев нарушения системы защиты
разработка средств фиксации доступа к данным и попыток нарушения системы защиты;
тестирование системы защиты;
исследование случаев нарушения системы защиты и развитие динамических методов защиты информации в БД.
Обеспечение восстановления БД:
разработка организационных средств архивирования и принципов восстановления БД;
разработка дополнительных программных средств и технологических процессов восстановления БД после сбоев.
Анализ обращений пользователей БД: сбор статистики по характеру запросов, по времени их выполнения, по требуемым выходным документам
Анализ эффективности функционирования БД:
анализ показателей функционирования БД;
планирование реструктуризации (изменение структуры) БД и реорганизации БнД.
Работа с конечными пользователями:
сбор информации об изменении предметной области;
сбор информации об оценке работы БД;
обучение пользователей, консультирование пользователей;
разработка необходимой методической и учебной документации по работе конечных пользователей.
Подготовка и поддержание системных средств:
анализ существующих на рынке программных средств и анализ возможности и необходимости их использования в рамках БД;
разработка требуемых организационных и программно-технических мероприятий по развитию БД;
проверка работоспособности закупаемых программных средств перед подключением их к БД;
курирование подключения новых программных средств к БД. 11. Организационно-методическая работа по проектированию БД:
выбор или создание методики проектирования БД;
определение целей и направления развития системы в целом;
планирование этапов развития БД;
разработка общих словарей-справочников проекта БД и концептуальной модели;
стыковка внешних моделей разрабатываемых приложений;
курирование подключения нового приложения к действующей БД;
обеспечение возможности комплексной отладки множества приложений, взаимодействующих с одной БД.
Пользователи банков данных
Как любой программно-организационно-технический комплекс, банк данных существует во времени и в пространстве. Он имеет определенные стадии своего развития:
Проектирование.
Реализация.
Эксплуатация;
Модернизация и развитие.
Полная реорганизация.
На каждом этапе своего существования с банком данных связаны разные категории пользователей.
Определим основные категории пользователей и их роль в функционировании банка данных:
Конечные пользователи. Это основная категория пользователей, в интересах которых и создается банк данных. В зависимости от особенностей создаваемого банка данных круг его конечных пользователей может существенно различаться. Это могут быть случайные пользователи, обращающиеся к БД время от времени за получением некоторой информации, а могут быть регулярные пользователи. В качестве случайных пользователей могут рассматриваться, например, возможные клиенты вашей фирмы, просматривающие каталог вашей продукции или услуг с обобщенным или подробным описанием того и другого. Регулярными пользователями могут быть ваши сотрудники, работающие со специально разработанными для них программами, которые обеспечивают автоматизацию их деятельности при выполнении своих должностных обязанностей. Например, менеджер, планирующий работу сервисного отдела компьютерной фирмы, имеет в своем распоряжении программу, которая помогает ему планировать.и распределять текущие заказы, контролировать ход их выполнения, заказывать на складе необходимые комплектующие для новых заказов. Главный принцип состоит в том, что от конечных пользователей не должно требоваться каких-либо специальных знаний в области вычислительной техники и языковых средств.
Администраторы банка данных. Это группа пользователей, которая на начальной стадии разработки банка данных отвечает за его оптимальную организацию с точки зрения одновременной работы множества конечных пользователей, на стадии эксплуатации отвечает за корректность работы данного банка информации в многопользовательском режиме.
и реорганизации эта группа пользователей
На стадии развития и реорганизации эта группа пользователей отвечает за возможность корректной реорганизации банка без изменения или прекращения его текущей эксплуатации.
Разработчики и администраторы приложений. Это группа пользователей, которая функционирует во время проектирования, создания и реорганизации банка данных. Администраторы приложений координируют работу разработчиков при разработке конкретного приложения или группы приложений, объединенных в функциональную подсистему. Разработчики конкретных приложений работают с той частью информации из базы данных, которая требуется для конкретного приложения.
Не в каждом банке данных могут быть выделены все типы пользователей. Мы уже знаем, что при разработке информационных систем с использованием настольных СУБД администратор банка данных, администратор приложений и разработчик часто существовали в одном лице. Однако при построении современных сложных корпоративных баз данных, которые используются для автоматизации всех или большей части бизнес-процессов в крупной фирме или корпорации, могут существовать и группы администраторов приложений, и отделы разработчиков. Наиболее сложные обязанности возложены на группу администратора БД.
Рассмотрим их более подробно.
В составе группы администратора БД должны быть:
системные аналитики;
проектировщики структур данных и внешнего по отношению к банку данных информационного обеспечения;
проектировщики технологических процессов обработки данных;
системные и прикладные программисты;
операторы и специалисты по техническому обслуживанию.
Если речь идет о коммерческом банке данных, то важную роль здесь играют специалисты по маркетингу.
Процесс прохождения пользовательского запроса
Рисунок 2.2 иллюстрирует взаимодействие пользователя, СУБД и ОС при обработке запроса на получение данных. Цифрами помечена последовательность взаимодействий:
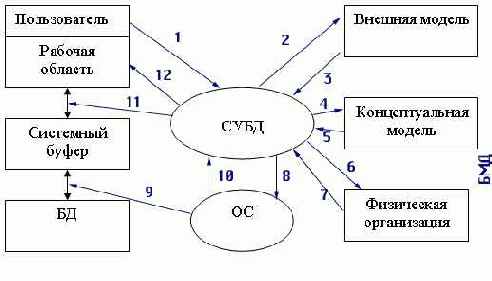
Рис. 2.2. Схема прохождения запроса к БД
Пользователь посылает СУБД запрос на получение данных из БД.
Анализ прав пользователя и внешней модели данных, соответствующей данному пользователю, подтверждает или запрещает доступ данного пользователя к запрошенным данным.
В случае запрета на доступ к данным СУБД сообщает пользователю об этом (стрелка 12) и прекращает дальнейший процесс обработки данных, в противном случае СУБД определяет часть концептуальной модели, которая затрагивается запросом пользователя.
СУБД получает информацию о запрошенной части концептуальной модели.
СУБД запрашивает информацию о местоположении данных на физическом уровне (файлы или физические адреса).
В СУБД возвращается информация о местоположении данных в терминах операционной системы.
СУБД вежливо просит операционную систему предоставить необходимые данные, используя средства операционной системы.
Операционная система осуществляет перекачку информации из устройств хранения и пересылает ее в системный буфер.
Операционная система оповещает СУБД об окончании пересылки.
СУБД выбирает из доставленной информации, находящейся в системном буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя.
БМД — это База Метаданных, именно здесь и хранится вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных. Для управления БМД существует специальное программное обеспечение администрирования баз данных, которое предназначено для корректного использования единого информационного пространства многими пользователями.
Всегда ли запрос проходит полный цикл? Конечно, нет. СУБД обладает достаточно развитым интеллектом, который позволяет ей не повторять бессмысленных действий. И поэтому, например, если этот же пользователь повторно обратится к СУБД с новым запросом, то для него уже не будут проверяться внешняя модель и права доступа, а если дальнейший анализ запроса покажет, что данные могут находиться в системном буфере, то СУБД осуществит только 11 и 12 шаги в обработке запроса.
Разумеется, механизм прохождения запроса в реальных СУБД гораздо сложнее, но и эта упрощенная схема показывает, насколько серьезными и сложными должны быть механизмы обработки запросов, поддерживаемые реальными СУБД.
Теоретико-графовые модели данных
Как уже упоминалось ранее, эти модели отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
Иерархическая модель данных
Иерархическая модель данных является наиболее простой среди всех даталоги-ческих моделей. Исторически она появилась первой среди всех даталогических моделей: именно эту модель поддерживает первая из зарегистрированных промышленных СУБД IMS фирмы IBM.
Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов. Иерархия проста и естественна в отображении взаимосвязи между классами объектов.
Основными информационными единицами в иерархической модели являются: база данных (БД), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Например, если в задачах требуется печатать в документах адрес клиента, но не требуется дополнительного анализа полного адреса, то есть города, улицы, дома, квартиры, то мы можем принять весь адрес за элемент данных, и он будет храниться полностью, а пользователь сможет получить его только как полную строку символов из БД. Если же в наших задачах существует анализ частей, составляющих адрес, например города, где расположен клиент, то нам необходимо выделить город как отдельный элемент данных, только в этом случае пользователь может получить к нему доступ и выполнить, например, запрос на поиск всех клиентов, которые проживают в конкретном городе, например в Париже. Однако если пользователю понадобится и полный адрес клиента, то остальную информацию по адресу также необходимо хранить в отдельном поле, которое может быть названо, например, Сокращенный адрес. В этом случае для каждого клиента в БД хранится как Город, так и Сокращенный адрес.
Сегмент в терминологии Американской Ассоциации по базам данных DBTG (Data Base Task Group) называется записью, при этом в рамках иерархической модели определяются два понятия: тип сегмента или тип записи и экземпляр сегмента или экземпляр записи.
Тип сегмента — это поименованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих.
в рамках иерархической модели образует
Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов (полей, элементов данных). Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающий сотрудника организации, мы должны выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то, вероятно, наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако если мы будем строить БД, содержащую описание множества граждан, например нашей страны, то, скорее всего, нам придется в качестве ключа выбрать совокупность полей, отражающих его паспортные данные.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами: каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответствует несколько (множество) экземпляров данного (подчиненного) типа сегмента. Тип сегмента, находящийся на более высоком уровне иерархии, называется логически исходным по отношению к типам сегментов, соединенным с данным направленными иерархическими ребрами, которые в свою очередь называются логически подчиненными по отношению к этому типу сегмента. Иногда исходные сегменты называют сегментами-предками, а подчиненные сегменты называют сегментами-потомками.
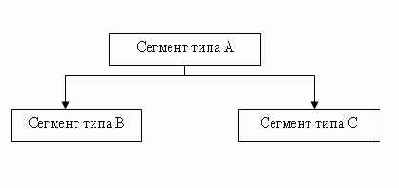
Рис. 3.1. Пример иерархических связей между сегментами
На концептуальном уровне определяется понятие схемы БД в терминологии иерархической модели.
Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных. Каждая физическая БД удовлетворяет следующим иерархическим ограничениям:
в каждой физической БД существует
в каждой физической БД существует один корневой сегмент, то есть сегмент, у которого нет логически исходного (родительского) типа сегмента;
каждый логически исходный сегмент может быть связан с произвольным числом логически подчиненных сегментов;
каждый логически подчиненный сегмент может быть связан только с одним логически исходным (родительским ) сегментом.
Очень важно понимать различие между сегментом и типом сегмента — оно такое же, как между типом переменной и самой переменной: сегмент является экземпляром типа сегмента. Например, у нас может быть тип сегмента Группа (Номер, Староста) и сегменты этого типа, такие как (4305, Петров Ф. И.) или (383, Кустова Т. С.).
Между экземплярами сегментов также существуют иерархические связи. Рассмотрим, например, иерархический граф, представленный на рис. 3.2.
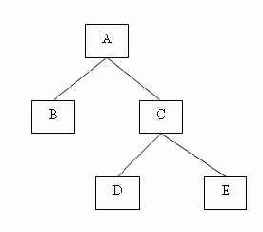
Рис. 3.2. Пример структуры иерархического дерева
Каждый тип сегмента может иметь множество соответствующих ему экземпляров. Между экземплярами сегментов также существуют иерархические связи.
На рис. 3.3 представлены 2 экземпляра иерархического дерева соответствующей
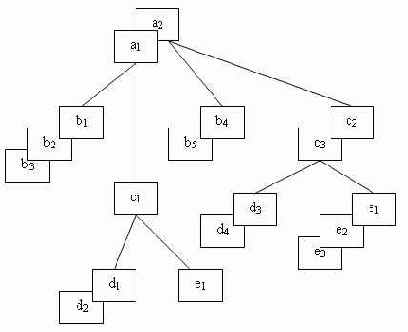
Рис. 3.3. Пример двух экземпляров данного дерева
Экземпляры-потомки одного типа, связанные с одним экземпляром сегмента-предка, называют «близнецами». Так, для нашего примера экземпляры b1, b2 и bЗ являются «близнецами» , но экземпляр b4 подчинен другому экземпляру родительского сегмента, и он не является «близнецом» по отношению к экземплярам b1, b2 и bЗ. Набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, называется физической записью. Количество экземпляров-потомков может быть разным для разных экземпляров родительских сегментов, поэтому в общем случае физические записи имеют разную длину. Так, используя принцип линейной записи иерархических графов, пример на рис 3.3 можно представить в виде двух записей:

Как видно из нашего примера, физические записи в иерархической модели различаются по длине и структуре.
Язык манипулирования данными в иерархических базах данных
Для доступа к базе данных у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде имеющиеся навигационные операции. Для этого в ней должны храниться:
шаблоны всех записей логических баз данных, доступных пользователю;
указатели на текущий экземпляр сегмента данного типа — для всех типов сегментов.
Язык манипулирования данными в иерархической модели поддерживает в явном виде навигационные операции. Эти операции связаны с перемещением указателя, который определяет текущий экземпляр конкретного сегмента.
Все операторы в языке манипулирования данными можно разделить на 3 группы. Первую группу составляют операторы поиска данных.
Операторы поиска данных
Синтаксис:
GET UNIQUE <имя сегмента> WHERE <список поиска>;
список поиска состоит из последовательности условий вида:
<имя сегмента>.<имя поля>ОС <constant или имя другого поля данного сегмента или имя переменной>:
ОС — операция сравнения;
условия могут быть соединены логическими операциями И и ИЛИ {& , V}.
Назначение:
Получить единственное значение.
Пример:
Найти типовую модель стоимостью не более $600, которая существует не менее чем в 10 экземплярах.
GET UNIQUE ТИПОВЫЕ МОДЕЛИ
WHERE Типовые модели.Стоимость <= $600
AND Типовые модели,Количество на складе >= 10
Данная команда всегда ищет с начала БД и останавливается, найдя первый экземпляр сегмента, удовлетворяющий условиям поиска.
Синтаксис:
GET NEXT <имя сегмента> WHERE <список аргументов поиска>
Назначение:
Получить следующий экземпляр сегмента для тех же условии.
Пример:
Напечатать полный список заказов стоимостью не менее $500.
GET UNIQUE ИНДИВИДУАЛЬНЫЕ МОДЕЛИ
WHERE Индивидуальные модели.Стоимость >- $500
WHILE NOT EAIL (пока не конец поиска) DO
PRINT № заказа. Стоимость, Количество
GET NEXT ИНДИВИДУАЛЬНЫЕ МОДЕЛИ
END
Синтаксис:
GET NEXT <имя сегмента> WITHIN PARENT [ where <дополн.условия>]
Назначение:
Получить следующий для того же
Получить следующий для того же исходного.
Пример:
Получить перечень винчестеров, имеющихся на складе номер 1, в количестве не менее 10 с объемом 10 Гбайт.
GET UNIQUE СКЛАД WHERE Склад.Номер = 1
GET NEXT ИЗДЕЛИЕ WITHIN PARENT
WHERE Изделие.Наименование = "Винчестер"
GET NEXT ХАРАКТЕРИСТИКИ WITHIN PARENT
WHERE ХАРАКТЕРИСТИКИ.Параметр = 10 AND
ХАРАКТЕРИСТИКИ.Единицы Измерения = Гб AND
ХАРАКТЕРИСТИКИ.Величина > 10
While Not Fail (пока поиск не завершен) DO
Get Next Within Parent
end
Операторы поиска данных с возможностью модификации
Найти и удержать единственный экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE, единственным отличием этой операции является то, что после выполнения этой операции пал найденным экземпляром сегмента допустимы операции модификации (изменения) данных.
Синтаксис:
GET HOLD UNIQUE <имя сегмента> WHERE <список поиска>
Найти и удержать следующий с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую операции поиска GET NEXT с возможностью выполнения последующей модификации данных.
Синтаксис:
GET HOLD NEXT [WHERE <дополнительные условия>]
Получить и удержать следующий для того же родителя. Эта операция является аналогом операции поиска 3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT WITHIN PARENT [ where <дополн.условия>]
Операторы модификации данных
Удалить : Это первая из трех операций модификации.
Синтаксис:
DELETE
Эта команда не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр сегмента, найденный командами поиска с удержанием. А он всегда единственный текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента. Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
Обновить
Синтаксис:
UPDATE
Как же происходит обновление, если мы и в этой команде не задаем никаких параметров.
СУБД берет данные из рабочей
СУБД берет данные из рабочей области пользователя, где в шаблонах записей соответствующих внутренних переменных находятся значения полей каждого сегмента внешней модели, с которой работает данный пользователь. Именно этими значениями и обновляется текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый экземпляр сегмента.
INSERT <имя сегмента>
Эта команда позволяет ввести новый экземпляр сегмента, имя которого определено в параметре команды. Если мы вводим данные в сегмент, который является подчиненным некоторому родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим, набор операций поиска и манипулирования данными в иерархической БД невелик, но он вполне достаточен для получения доступа к любому экземпляру любого сегмента БД. Однако следует отметить, что способ доступа, который применяется в данной модели, связан с последовательным перемещением от одного экземпляра сегмента к другому. Такой способ напоминает движение летательного аппарата или корабля по заданным координатам и называется навигационным.
Язык манипулирования данными в сетевой модели
Все операции манипулирования данными в сетевой модели делятся на навигационные операции и операции модификации.
Навигационные операции осуществляют перемещение по БД путем прохождения по связям, которые поддерживаются в схеме БД. В этом случае результатом является новый единичный объект, который получает статус текущего объекта.
Операции модификации осуществляют как добавление новых экземпляров отдельных типов записей, так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию отдельных составляющих внутри конкретных экземпляров записей. Средства модификации данных сведены в табл. 3.1:
Таблица 3.1. Операторы манипулирования данными в сетевой модели
| Операция | Назначение | ||||
| READY | Обеспечение доступа данного процесса или пользователя к БД (сходна по смыслу с операцией открытия файла) | ||||
| FINISH | Окончание работы с БД | ||||
| FIND | Группа операций, устанавливающих указатель найденного объекта на текущий объект | ||||
| GET | Передача найденного объекта в рабочую область. Допустима только после FIND | ||||
| STORE | Помещение в БД записи, .сформированной в рабочей области | ||||
| CONNECT | Включение текущей записи в текущий экземпляр набора | ||||
| DISCONNECT | Исключение текущей записи из текущего экземпляра набора | ||||
| MODIFY | Обновление текущей записи данными из рабочей области пользователя | ||||
| ERASE | Удаление экземпляра текущей записи | ||||
В рабочей области пользователя хранятся шаблоны записей, программные переменные и три типа указателей текущего состояния:
текущая запись процесса (код или ключ последней записи, с которой работала данная программа);
текущая запись типа записи (для каждого типа записи ключ последней записи, с которой работала программа);
текущая запись типа набор (для каждого набора с владельцем Т1 и членом Т2 указывается, Т1 или Т2 были последней обрабатываемой записью).
На рис. 3.7 представлена концептуальная модель торгово-посреднической организации.
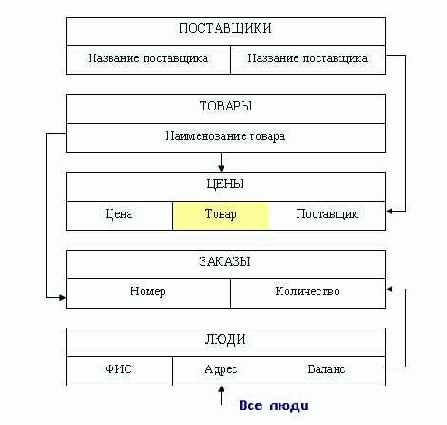
Рис. 3.7. Схема БД «Торговая фирма»
При необходимости возможно описание элементов
При необходимости возможно описание элементов данных, которые не принадлежат непосредственно данной записи, но при ее обработке часто используются. Для этого используется тип VIRTUAL с обязательным указанием источника данного элемента данных.
RECORD Цены
02 Цена TYPE REAL
02 Товар VIRTUAL
SOURCE IS Товары.НаименованиеТовара
OF OWNER OF Товар-Цены SET
Наиболее интересна операция поиска (FIND), так как именно она отражает суть навигационных методов, применяемых в сетевой модели. Всего существует семь типов операций поиска:
По ключу (запись должна быть описана через CALC USING ...):
FIND <Имя записи> RECORD BY CALC KEY <Имя параметра>
Последовательный просмотр записей данного типа:
FIND DUPLICATE <Имя записи> RECORD BY CALC KEY
Найти владельца текущего экземпляра набора:
FIND OWNER OF CURRENT <Имя набора> SET
Последовательный просмотр записей—членов текущего экземпляра набора:
FIND (FIRST | NEXT) <Имя записи> RECORD IN CURRENT <Имя набора> SET
Просмотр записей—членов экземпляра набора, специфицированных рядом нолей:
FIND [DUPLICATE] <Имя записи> RECORD IN CURRENT <Имя набора> SET USING <Список полей>
Сделать текущей записью процесса текущий экземпляр набора:
FIND CURRENT OF <Имя набора> SET
Установить текущую запись процесса:
FIND CURRENT OF <Имя записи> RECORD
Например, алгоритм и программа печати заказов, сделанных Петровым, будут выглядеть так:
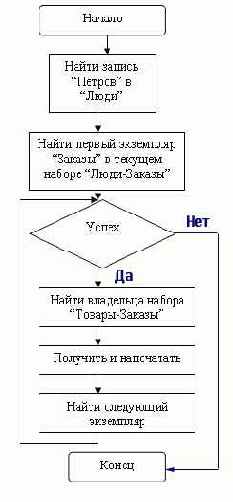
FIND Люди RECORD BY CALC KEY
FIND FIRST Заказы RECORD IN
CURRENT Люди-Заказы SET WHILE NOT FAIL DO
FIND OWNER OF CURRENT
Товары-Заказы SET GET Товары
PRINT НаимТовара FIND NEXT Заказы RECORD IN
CURRENT Люди-Заказы SET
END
Язык описания данных иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (DDL, Data Definition Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД. Описание начинается с оператора DBD (Data Base Definition):
DBD Name = < имя БД>, ACCESS = < способ доступа>
Способ доступа определяет способ организации взаимосвязи физических записей. Определено 5 способов доступа: HSAM — hierarchical sequential access method (иерархически последовательный метод), HISAM — hierarchical index sequential access method (иерархически индексно-последовательный метод), EDAM — hierarchical direct access method (иерархически прямой метод), HID AM — hierarchical index direct access method (иерархически индексно-прямой метод), INDEX — индексный метод.
Далее идет описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>.
DEVICE =< устройство хранения БД>,
[OVFLW = < имя области переполнения>]
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться и превысит исходную длину записи до модификации. В этом случае при определенных методах хранения может понадобиться дополнительное пространство хранения, где и будут размещены дополнительные данные. Это пространство и называется областью переполнения.
После описания всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш с иерархией. Описание сегментов всегда начинается с описания корневого сегмента. Общая схема описания типа сегмента такова:
SEGM NAME = < имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя частота реализаций сегмента под одним исходным>
PARENT = <имя родительского сегмента>
Параметр FREQ определяет среднее количество экземпляров данного сегмента, связанных с одним экземпляром родительского сегмента.
Для корневого сегмента это число
Для корневого сегмента это число возможных экземпляров корневого сегмента.
Для корневого сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание полей:
FIELD NAME = {(<имя поля> [. SEQ].{U M}) | <имя поля> }.
START = < номер байта, с которого начинается значения поля >,
BYTES = <размер поля в байтах>,
TYPE = {X | Р | С}
Признак SEQ — задается для ключевого поля, если экземпляры данного сегмента физически упорядочены в соответствии со значениями данного поля.
Параметр U задается, если значения ключевого поля уникальны для всех экземпляров данного сегмента, М — в противном случае. Если поле является ключевым, то его описание задается в круглых скобках, в противном случае имя поля задается без скобок. Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С — символьный.
Заканчивается описание схемы вызовом процедуры генерации:
DBDGEN — указывает на конец последовательности управляющих операторов описания БД;
FINISH — устанавливает ненулевой код завершения при обнаружении ошибки;
END — конец.
В системе может быть несколько физических БД (ФБД), но каждая из них описывается отдельно своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
Внешние модели
При работе с иерархической моделью каждая программа, пользователь или приложение определяет свою внешнюю модель. Внешняя модель представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данный пользователь. Каждый подграф внешней модели в обязательном порядке должен содержать корневой тип сегмента соответствующей физической базы данных концептуальной модели.
Представление внешней модели называется логической базой данных и определяется совокупностью блоков связи данного приложения с физическими БД, входящими в концептуальную схему БД.
с одной физической БД по
Блок связи — РСВ, program communication bloc — описывает связь с одной физической БД по следующим правилам:
DBD NAME = < имя логической БД (подсхемы)> , ACCESS = LOGICAL
DATA SET = LOGICAL.
SEGM NAME = <имя сегмента в подсхеме>,
PARENT =<имя родительского сегмента в подсхеме>,
SOURSE =(Имя соответствующего сегмента ФБД. имя ФБД)
DBDGEN
FINISH
END
Совокупность блоков РСВ образует полное внешнее представление данного приложения, называемое «блоком спецификации программ» (PSB, program specification block).
Рассмотрим пример иерархической БД.
Наша организация занимается производством и продажей компьютеров, в рамках производства мы комплектуем компьютеры из готовых деталей по индивидуальным заказам. У нас существует несколько базовых моделей, которые мы продаем без предварительных заказов по наличию на складе. В организации существуют несколько филиалов (рис. 3.4) и несколько складов, на которых хранятся комплектующие. Нам необходимо вести учет продаваемой продукции.
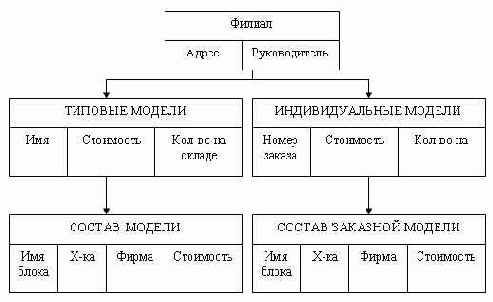
Рис. 3.4. Физическая БД «Филиалы»
Какие задачи нам надо решать в ходе разработки приложения?
При приеме заказа мы должны выяснить, какую модель заказывает заказчик: типичную или индивидуальную комплектацию.
Если заказывается типичная модель, то выясняется, какая модель и есть ли она в наличии, если модель есть, то надо уменьшить количество компьютеров данной модели в данном филиале на покупаемое количество. На этом будем считать заказ выполненным, однако при оформлении заказа может потребоваться задание полной спецификации покупаемого изделия.
Если заказывается индивидуальная модель, то требуется описать весь состав новой модели.
Для того чтобы можно было бы принимать заказы на индивидуальные модели, нам понадобится информация о наличие конкретных деталей на складе, в этом случае нам необходимо второе дерево — Склады (см. рис. 3.5).
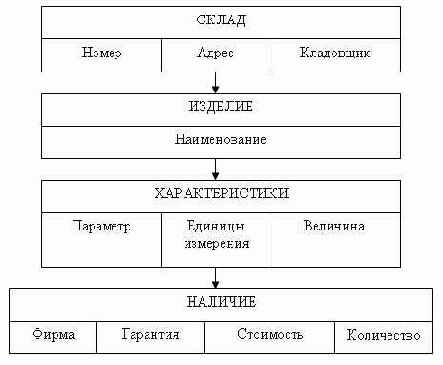
Рис. 3.5. Физическая модель «Склады»
Язык описания данных в сетевой модели
Язык описания данных в сетевой модели имеет несколько разделов:
описание базы данных — области размещения;
описания записей — элементов и агрегатов (каждого в отдельности);
описания наборов (каждого в отдельности).
SCHEMA IS <Имя БД>.
AREA NAME IS <Имя физической области>.
RECORD NAME IS <Имя записи (уникапьное)>
Для каждой записи определяется способ размещения экземпляров записи данного типа:
LOCATION MODE IS'{DIRECT (напрямую)
CALC <Имя программы> USING <[Список пер.>]
DUPLICATE ARE [NOT] ALLOWED
VIA <Имя на6ора> SET (рядом с записями владельца)
SYSTEM (решать будет система)}
Каждый тип записи должен быть приписан к некоторой физической области размещения:
WITHIN <Имя области размещения> AREA
После описания записи в целом идет описание внутренней структуры:
<Имя уровня> <Имя данного> <Шаблон> <Тип>
Номер уровня определяет уровень вложенности при описании элементов и агрегатов данных. Первый уровень — сама запись. Поэтому элементы или агрегаты данных имеют уровень начиная со второго. Если данное соответствует агрегату, то любая его составляющая добавляет один уровень вложенности.
Если агрегат является вектором, то он описывается как <Номер уровня> <Имя агрегата>.<Номер уровня> <Имя 1-й сост.> а если — повторяющейся группой, то следующим образом:
<Номер уровня> <Имя агрегата>.OCCURS <N> TIMES
где N — среднее количество элементов в группе.
Описание набора и порядка включения членов в него выглядит следующим образом:
SET NAME IS <Имя набора>:
OWNER IS (<Имя владельца> SYSTEM).
Далее указывается порядок включения новых экземпляров члена данного набора в экземпляр набора:
ORDER PERMANENT INSERTION IS {SORTED | NEXT | PREV | LAST FIRST}
После этого описывается член набора с указанием способа включения и способа исключения экземпляра — члена набора из экземпляра набора.
MEMBER IS <Имя члена набора> {AUTOMATIC | MANUAL} {MANDATORY OPTIONAL} KEY IS (ACCENDING | DESCENDING) <Имя элемента данных>
При автоматическом включении каждый новый; экземпляр члена набора автоматически попадает в текущий экземпляр набора в соответствии с заданным ранее Порядком включения. При ручном способе экземпляр члена набора сначала попадает в БД, а только потом командой CONNECT может быть включен в конкретный экземпляр набора.
Если задан способ исключения MANDATORY, то экземпляр записи, исключаемый из набора, автоматически исключается и из базы данных. Иначе просто разрываются связи.
Внешняя модель при сетевой организации данных поддерживается путем описания части общего связного графа.
Сетевая модель данных
Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Базовыми объектами модели являются:
элемент данных;
агрегат данных;
запись;
набор данных,
Элемент данных — то же, что и в иерархической модели, то есть минимальная информационная единица, доступная пользователю с использованием СУБД.
Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа вектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
|
Адрес
|
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
|
|
|
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию «сегмент» в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи.
Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый граф, связывающий отношением «одии-комногим» два типа записи.

Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора.
Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение «многие-ко-многим» между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической.
В рамках набора возможен последовательный
В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора.
Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора.
В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
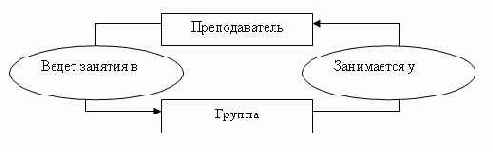
Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров данных наборов.
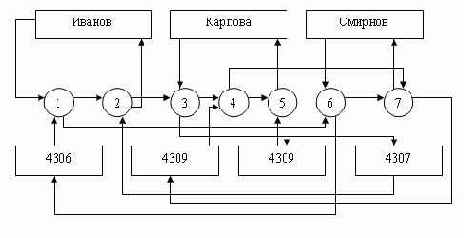
Рис. 3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи «Владелец набора». Например, сингулярный набор М.
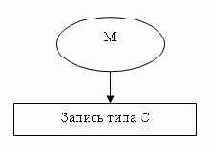
Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор.
В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.
Операции над отношениями. Реляционная алгебра
Напомним, что алгеброй называется множество объектов с заданной на нем совокупностью операции, замкнутых относительно этого множества, называемого основным множеством.
Основным множеством в реляционном алгебре является множество отношений. Всего Э. Ф. Коддом было предложено 8 операций. В общем это множество избыточное, так как одни операции могут быть представлены через другие, однако множество операций выбрано из соображений максимального удобства при реализации произвольных запросов к БД. Все множество операций можно разделить на две группы: теоретико-множественные операции и специальные операции. В первую группу входят 4 операции. Три первые теоретико-множественные операции являются бинарными, то есть в них участвуют два отношения и они требуют эквивалентных схем исходных отношений.
Основные определения
Появление теоретико-множественных моделей в системах баз данных было пред определено настоятельной потребностью пользователей в переходе от работы с элементами данных, как это делается в графовых моделях, к работе с некоторыми макрообъектамн. Основной моделью в этом классе является реляционная модель данных. Простота и наглядность модели для пользователей-непрограммистов, с одной стороны, и серьезное теоретическое обоснование, с другой стороны, определили большую популярность этой модели. Кроме того, развитие формального аппарата представления и манипулирования данными в рамках реляционной модели сделали се наиболее перспективной для использования в системах представления знаний, что обеспечивает качественно иной подход к обработке данных в больших информационных системах.
Теоретической основой этой модели стала теория отношений, основу которой заложили два логика — американец Чарльз Содерс Пирс (1839-1914) и немец Эрнст Шредер (1841-1902). В руководствах по теории отношений было показано, что множество отношений замкнуто относительно некоторых специальных операций, то есть образует вместе с этими операциями абстрактную алгебру. Это важнейшее свойство отношений было использовано в реляционной модели для разработки языка манипулирования данными, связанного с исходной алгеброй. Американский математик Э. Ф. Кодд в 1970 году впервые сформулировал основные понятия и ограничения реляционной модели, ограничив набор операций в ней семью основными и одной дополнительной операцией. Предложения Кодда были настолько эффективны для систем баз данных, что за эту модель он был удостоен престижной премии Тьюринга в области теоретических основ вычислительной техники.
Основной структурой данных в модели является отношение, именно поэтому модель получила название реляционной (от английского relation — отношение).
N-арным отношением R называют подмножество декартова произведения D,xD2x ... xDn множеств D,, D2, ..., Dn (n > 1), необязательно различных. Исходные множества D1, D2, ..., Dn называют в модели доменами.
это набор всевозможных сочетаний из
R

где D1xD2x ...xDn— полное декартово произведение.
Полное декартово произведение — это набор всевозможных сочетаний из п элементов каждое, где каждый элемент берется из своего домена. Например, имеем три домена: D1 содержит три фамилии, D2 — набор из двух учебных дисциплин и D3 — набор из трех оценок. Допустим, содержимое доменов следующее:
D1 = {Иванов, Крылов, Степанов};
D2 = (Теория автоматов, Базы данных};
D3 = {3, 4, 5}
Тогда полное декартово произведение содержит набор из 18 троек, где первый элемент — это одна из фамилий, второй — это название одной из учебных дисциплин, а третий — одна из оценок.
<Иванов.Теория автоматов.3>: <Иванов.Теория автоматов.4>; <Иванов.Теория автоматов,5> <Крылов.Теория автоматов.3>: <Крылов,Теория автоматов,4>: <Крылов,Теория автоматов.5>: <Степанов.Теория автоматов.3>; <Степанов.Теория автоматов.4>: <Степанов,Теория автоматов.5>: <Иванов,Базы данных.3>: <Иванов.Базы данных.4>: <Иванов,Базы данных.5>: <Крылов,Базы данных,3>; <Крылов,Базы данных,4>; <Крылов.Базы данных.5>; <Степанов.Базы данных.3>: <Степанов,Базы данных.4>: <Степанов,Базы данных,5>:
Отношение R моделирует реальную ситуацию и оно может содержать, допустим, только 5 строк, которые соответствуют результатам сессии (Крылов экзамен по «Базам данных» еще не сдавал):
<Иванов.Теория автоматов.4>: <Крылов,Теория автоматов,5>: <Степанов,Теория автоматов,5>; <Иванов.Базы данных.3>; <Степанов.Базы данных.4>;
Отношение имеет простую графическую интерпретацию, оно может быть представлено в виде таблицы, столбцы которой соответствуют вхождениям доменов в отношение, а строки — наборам из п значений, взятых из исходных доменов, которые расположены в строго определенном порядке в соответствии с заголовком. Такие наборы из п значений часто называют п-ками.
R | ||
Фамилия | Дисциплина | Оценка |
Иванов | Теория автоматов | 4 |
Иванов | Базы данных | 3 |
Крылов | Теория автоматов | 5 |
Степанов | Теория автоматов | 5 |
Степанов | Базы данных | 4 |
Данная таблица обладает рядом специфических
Данная таблица обладает рядом специфических свойств:
В таблице нет двух одинаковых строк.
Таблица имеет столбцы, соответствующие атрибутам отношения.
Каждый атрибут в отношении имеет уникальное имя.
Порядок строк в таблице произвольный.
Вхождение домена в отношение принято называть атрибутом. Строки отношения называются кортежами.
Количество атрибутов в отношении называется степенью, или рангом, отношения.
Следует заметить, что в отношении не может быть одинаковых кортежей, это следует из математической модели: отношение — это подмножество декартова произведения, а в декартовом произведении все n-ки различны,
В соответствии со свойствами отношений два отношения, отличающиеся только порядком строк или порядком столбцов, будут интерпретироваться в рамках реляционной модели как одинаковые, то есть отношение R и отношение R1, изображенное далее, одинаковы с точки зрения реляционной модели данных.
R1 | ||
Дисциплина | Фамилия | Оценка |
Теория автоматов | Крылов | 5 |
Теория автоматов | Степанов | 5 |
Теория автоматов | Иванов | 4 |
Базы данных | Иванов | 3 |
Базы данных | Степанов | 4 |
Любое отношение является динамической моделью некоторого реального объекта внешнего мира. Поэтому вводится понятие экземпляра отношения, которое отражает состояние данного объекта в текущий момент времени, и понятие схемы отношения, которая определяет структуру отношения.
Схемой отношения R называется перечень имен атрибутов данного отношения с указанием домена, к которому они относятся:
SR = (А1, А2, Аn) Аi
Если атрибуты принимают значения из одного и того же домена, то они называются Q-сравпимыми, где Q— множество допустимых операций сравнения, заданных для данного домена. Например, если домен содержит числовые данные , то для него допустимы все операции сравнения, тогда Q = {=, <>,>=,<-,<,>}. Однако и для доменов, содержащих символьные данные, могут быть заданы не только операции сравнения по равенству и неравенству значений.
Если для данного домена задано
Если для данного домена задано лексикографическое упорядочение, то он имеет также полный спектр операций сравнения.
Схемы двух отношений называются эквивалентными, если они имеют одинаковую степень и возможно такое упорядочение имен атрибутов в схемах, что на одинаковых местах будут находиться сравнимые атрибуты, то есть атрибуты, принимающие значения из одного домена.
SR1 = (A1, A2, ..., An) — схема отношения R1.
SR2 = (Bi1, Bi2,..., Bin) — схема отношения R2 после упорядочения имен атрибутов.
Тогда
sR1~sR2<=>1. n=m, или 2. Аj,Bij
Как уже говорилось ранее, реляционная модель представляет базу данных в виде множества взаимосвязанных отношений. В отличие от теоретико-графовых моделей в реляционной модели связи между отношениями поддерживаются неявным образом. Какие же связи между отношениями поддерживаются в реляционной модели? В этой модели, так же как и в остальных, поддерживаются иерархические связи между отношениями. В каждой связи одно отношение может выступать как основное, а другое отношение выступает в роли подчиненного. Это означает, что один кортеж основного отношения может быть связан с несколькими кортежами подчиненного отношения. Для поддержки этих связей оба отношения должны содержать наборы атрибутов, по которым они связаны. В основном отношении это первичный ключ отношения (PRIMARY KEY), который однозначно определяет кортеж основного отношения. В подчиненном отношении для моделирования связи должен присутствовать набор атрибутов, соответствующий первичному ключу основного отношения. Однако здесь этот набор атрибутов уже является вторичным ключом, то есть он определяет множество кортежей подчиненного отношения, которые связаны с единственным кортежем основного отношения. Данный набор атрибутов в подчиненном отношении принято называть внешним ключом (FOREIGN KEY).
Например, рассмотрим ситуацию, когда надо описать карьеру некоторого индивидуума. Каждый человек в своей трудовой деятельности сменяет несколько мест работы в разных организациях, где он работает в разных должностях.Тогда мы должны создать два отношения: одно для моделирования всех работающих людей, а другое для моделирования записей в их трудовых книжках, если для нас важно не только отследить переход работника из одной организации в другую, но и прохождение его по служебной лестнице в рамках одной организации (рис. 4.1).
Рис. 4.1. Связь между основным и подчиненным отношениями
PRIMARY KEY отношения Сотрудник атрибут Паспорт является FOREIGHN KEY для отношения «карьера».
Специальные операции реляционной алгебры
Первой специальной операцией реляционной алгебры является горизонтальный выбор, или операция фильтрации, или операция ограничения отношений. Для определения этой операции нам необходимо ввести дополнительные обозначения.
Пусть а — булевское выражение, составленное из термов сравнения с помощью связок И (^), ИЛИ (

а) терм А ос а, где А — имя некоторого атрибута, принимающего значения из домена D; а — константа, взятая из того же домена D, a

б) терм А ос В, где А, В — имена некоторых Q-сравнимых атрибутов, то есть атрибутов, принимающих значения из одного и то же домена D.
Тогда результатом операции выбора, или фильтрации, заданной на отношении R в виде булевского выражения, определенного на атрибутах отношения R, называется отношение R[G], включающее те кортежи из исходного отношения, для которых истинно условие выбора или фильтрации:
R[G(r)] = {r | r
Операция фильтрации является одной из основных при работе с реляционной моделью данных. Условие а может быть сколь угодно сложным.
Например, выбрать из R10 детали с шифром «0011003». R12 =R10[ Шифр детали = «0011003»]
|
R12 |
||
|
Шифр детали |
Название детали |
Цех |
|
000 1 1003 |
Болт М 1 |
Цех 1 |
|
00011003 |
Болт М 1 |
Цех 3 |
Следующей специальной операцией является операция проектирования. Пусть R — отношение, SR = (А1, ... , Аn) — схема отношения R. Обозначим через В подмножество [ Аi]; В
Проекцией отношения R па набор атрибутов В, обозначаемой R[B], называется отношение со схемой, соответствующей набору атрибутов В SR|B| = В, содержащему кортежи, получаемые из кортежей исходного отношения R путем удаления из них значений, не принадлежащих атрибутам из набора В.
По определению отношений все дублирующие
R[B] = {r[В]}
По определению отношений все дублирующие кортежи удаляются из результирующего отношения.
Операция проектирования, называемая иногда также операцией вертикального выбора, позволяет получить только требуемые характеристики моделируемого объекта. Чаще всего операция проектирования употребляется как промежуточный шаг в операциях горизонтального выбора, или фильтрации. Кроме того, она используется самостоятельно на заключительном этапе получения ответа на запрос. Например, выберем все цеха, которые изготавливают деталь «Болт Ml».
Для этого нам необходимо из отношения R10 выбрать детали с заданным названием, а потом полученное отношение спроектировать на столбец «Цех». Результатом выполнения этих операций будет отношение R14:
R13 = R10 [ Название детали = «Болт Ml» ]
R14 = R13 [ Цех |
R13 | ||
Шифр детали детали | Название | Цех |
| 00011003 | Болт M1 | Цех 1 |
00011003 | Болт M1l | Цех3 |
R14 |
Цех |
Цех 1 |
Цех 3 |
Следующей специальной операцией реляционной алгебры является операция условного соединения.
В отличие от рассмотренных специальных операций реляционной алгебры: фильтрации и проектирования, которые являются унарными, то есть производятся над одним отношением, операция условного соединения является бинарной, то есть исходными для нее являются диа отношения, а результатом — одно.
Пусть R = {r}, Q = { q } — исходные отношения,
SR, SQ — схемы отношений R и Q соответственно.
SR = (А1, А2, ... , Ak): SQ = (В1 В2, ... , Bm),
где А,, В, — имена атрибутов в схемах отношений R и Q соответственно. При этом полагаем, что заданы наборы атрибутов А и В
А
Тогда соединением отношений R и Q при условии р будет подмножество декартова произведения отношений R и Q, кортежи которого удовлетворяют условию р, рассматриваемому как одновременное выполнение условий:
r.Aj Qj Вi, : i=l,k, где k — число атрибутов, входящих в наборы А и В, а Qj— конкретная операция сравнения.
Aj Qj Вi Di Qi
Aj Qj Вi Di Qi — i-й предикат сравнения, определяемый из множества допустимых на домене Di операций сравнения.
R [ Р ] Q = { r.q) | (г. q) | r.A Qj q.Bj - «Истина», i=l,k}
Например, рассмотрим следующий запрос. Пусть отношение R15 содержит перечень деталей с указанием материалов, из которых эти детали изготавливаются, и оно имеет вид:
R15 | ||
Шифр детали | Название детали | Материал |
00011073 | Гайка Ml | сталь-ст1 |
00011075 | Гайка М2 | сталь-ст2 |
00011076 | Гайка МЗ | сталь-ст1 |
00011003 | Болт М1 | сталь-стЗ |
00011006 | Болт МЗ | сталь-стЗ |
00013063 | Шайба Ml | сталь-ст1 |
00013066 | Шайба МЗ | сталь-ст1 |
00011077 | Гайка М4 | сталь-ст2 |
00011004 | Болт М2 | сталь-стЗ |
00011005 | Болт М5 | сталь-стЗ |
00013062 | Шайба М2 | сталь-ст1 |
R16 |
Название детали |
Гайка M1 |
Гайка МЗ |
Шайба М1 |
Шайба МЗ |
Шайба М2 |
Получим перечень деталей, которые изготавливаются в цеху 1 из материала «сталь-ст1»
R16 = (R15[(R15Шифр детали =R10.Шифр детали) ^R10.Цех = «Цех1» ^ ^ R15.Материал =«сталь-ст1»] R10)[Hазвание детали]
Последней операцией, включаемой в набор операций реляционной алгебры, является операция деления.
Для определения операции деления рассмотрим сначала понятие множества образов.
Пусть R — отношение со схемой SR = (A1, A2 ,..., Ak);
Пусть А — некоторый набор атрибутов А
Пересечение множеств А и А1 пусто: А


Тогда множеством образов элемента у проекции R[А] называется множество таких элементов у проекции R[A1] , для которых сцепление (х, у) является кортежами отношения R, то есть
QA(x) = {у | у
Например, множеством образов отношения R15 по материалу «сталъ-ст2» будет множество кортежей
К15.Материал = {< 00011075, Гайка М2, «сталь-ст2»>, < 00011077, Гайка М4, «сталь-ст2»>}
Дадим теперь определение операции деления.
Дадим теперь определение операции деления. Пусть даны два отношения R и Т соответственно со схемами: SR = (А1, А2, ... , Ak); ST =-(В1, В2, ... , Вm);
А и В — наборы атрибутов этих отношений, одинаковой длины (без повторений);
А

Пересечение множеств А

Тогда операция деления ставит в соответствие отношениям R и Т отношение
Q = R[A:B]T, кортежи которого являются теми элементами проекции R[A1], для которых Т[В] входит в построенные для них множество образов:
R[A:B]T = {r | r
Операция деления удобна тогда, когда требуется сравнить некоторое множество характеристик отдельных атрибутов. Например, пусть у нас есть отношение R7, которое содержит номенклатуру всех выпускаемых деталей на нашем предприятии, а в отношении R10 хранятся сведения о том, что и в каких цехах действительно выпускается. Поставим задачу определить перечень цехов, в которых выпускается вся номенклатура деталей.
Тогда решением этой задачи будет операция деления отношения R10 на отношение R7 по набору атрибутов (Шифр детали, Наименование детали).
R17 = R10[Шифр детали, Наименование детали: Шифр детали, Наименование детали] R7
R 17 |
Цех |
Цех1 |
Операция деления достаточно сложна для абстрактного представления. Она может быть заменена последовательностью других операций. Действительно, выполним тот же запрос с использованием других операций. Для этого определим последовательность промежуточных запросов, которая приведет нас к конечному результату:
Построим отношение, которое моделирует ситуацию, когда в каждом цеху изготавливается вся номенклатура, это уже построенное нами ранее расширенное декартово произведение отношений R7 и R8. Это отношение R9:
R9 = R7

Теперь найдем перечень того, что из обязательной номенклатуры не выпускается в некоторых цехах
в которых не все детали
R11 =R9\R10
Далее найдем те цеха, в которых не все детали выпускаются, для этого нам надо отношение R11 спроектировать на столбец «Цех»:
R18 = R11[Цех]
R18 |
Цех |
Цех 2 |
ЦeхЗ |
А теперь из перечня всех цехов вычтем те, кто выпускает не все детали, и получим ответ на запрос, и это будет тот же результат, что и в отношении R17.
Посмотрим, как работают операции реляционной алгебры для другого примера. Возьмем набор отношений, которые моделируют сдачу сессии студентами некоторого учебного заведения. Тема весьма понятная и привычная.
R1 = <ФИО, Дисциплина, Оценка>;
R2 = <ФИО, Группа>;
R3 = < Группы, Дисциплина>,
где R1 — информация о попытках (как успешных, так и неуспешных) сдачи экзаменов студентами; R2 — состав групп; R3 — список дисциплин, которые надо сдавать каждой группе. Домены для атрибутов формально задавать не будем, но, ориентируясь на здравый смысл, будем считать, что доменом для атрибута Дисциплина будет множество всех дисциплин, преподающихся в ВУЗе, доменом для атрибута Группа будет множество всех групп ВУЗа и т. д.
Покажем, каким образом можно получить из этих таблиц интересующие нас
сведення с помощью реляционной алгебры. В каждом из приведенных примеров путем операции над исходными отношениями R1, R2, R3 формируются промежуточные отношения и результирующее отношение S, содержащее требуемую информацию.
Список студентов, которые сдали экзамен по БД на «отлично». Результат может быть получен применением операции фильтрации по сложному условию к отношению R1 и последующим проектированием на атрибут «ФИО» (нам ведь требуется только список фамилий).
S = (R1|[Оценка = 5 ^ Дисциплина = «БД»])[ФИО];
Список тех, кто должен был сдавать экзамен по БД, но пока еще не сдавал. Сначала найдем всех, кто должен был сдавать экзамен по БД. В отношении R3 находится список всех дисциплин, по которым каждая группа должна была сдавать экзамены, ограничим перечень дисциплин только «БД».
Для того чтобы получить список
Для того чтобы получить список студентов, нам надо соединить отношение R3 с отношением R2, в котором определен список студентов каждой группы.
R4 = (R2[R3Номер группы = R2.НомерГруппы ^ R3.Дисциплина = «БД»] R3)[ФИО];
Теперь получим список всех, кто сдавал экзамен по «БД» (нас пока не интересует результат сдачи, а интересует сам факт попытки сдачи, то есть присутствие в отношении R1):
R5 = (R1 [Дисциплина = «БД»1)[ФИО];
и, наконец, результат — все, кто есть в первом множестве, но не во втором:
S = R4 \ R5;
Список несчастных, имеющих несколько двоек:
S = (R1[R1.ФИО = Rl.ФИО ^ R1Дисцинлина не равно R'1.Дисциплина ^
R1Оценка <= 2^ R'1.Оценка < 2] Rэ1,)[ФИО]
Этот пример весьма интересен: для поиска строк, удовлетворяющих в совокупности условию больше одною, применяется операция соединения отношения с самим собой. Поэтому мы как бы взяли копию отношения R1 и назвали ее R'1.
Список круглых отличников. Строим список всех пар <студеит—дисциплина>, которые в принципе должны быть сданы:
R4 = (R2[R2Группа = R3Группa] R3)[ФИО, Дисциплина];
Строим список пар <студент- дисциплина>, где получена оценка «отлично»:
R5 = (R1|[Оценкa = 5])[ФИО, Дисциплина];
Строим список студентов, что-либо не сдавших на отлично:
R6=(R4\R5)[ФИО].
Наконец, исключив последнее отношение из общего списка студентов, получаем результат:
R2[ФИО] \ R6
Обратите внимание, что для получения множества студентов, что-либо не сдавших на «отлично» (R6). мы осуществили «инверсию» множества всех отлично сданных пар <студент—дисциплина> (R5) путем вычитания его из предварительного построенного универсального множества (R4). Рекомендуем очень внимательно разобрать этот пример и вникнуть в смысл каждого действия — это очень пригодится для понимания реляционной алгебры.
Теоретико-множественные операции реляционной алгебры
Объединением двух отношении называется отношение, содержащее множество кортежей, принадлежащих либо первому, либо второму исходным отношениям, либо обоим отношениям одновременно.
Пусть заданы два отношения R1 = { r1 } , R2 = { r2 }. где r1 и r2 — соответственно кортежи отношений R1 и R2, то объединение
R1
Пример применения операции объединения приведен па рис. 4.1. Исходными отношениями являются отношения R1 и R2, которые содержат перечни деталей. изготавливаемых соответственно на первом и втором участках цеха. Отношение R3 содержит общин перечень деталей, изготавливаемых в цеху, то есть характеризует общую номенклатуру цеха.
|
R1 |
|
|
Шифр детали |
Название детали |
|
00011073 |
Гаика Ml |
|
00011075 |
Гайка М2 |
|
00011076 |
Гаика M3 |
|
00011003 |
Болт Ml |
|
00011006 |
Болт МЗ |
|
00013063 |
Шайба Ml |
|
00013066 |
Шайба МЗ |
|
R2 |
|
|
Шифр детали |
Название детали |
|
00011073 |
Гайка М1 |
|
00011076 |
Гайка М3 |
|
00011077 |
Гайка М4 |
|
00011004 |
Гайка М2 |
|
00011006 |
Гайка М3 |
|
R3 |
|
|
Шифр детали |
Название детали |
|
00011073 |
Гайка Ml |
|
00011075 |
Гайка М2 |
|
00011076 |
Гайка МЗ |
|
00011003 |
Болт Ml |
|
00011006 |
Болт МЗ |
|
00013063 |
Шайба Ml |
|
00013066 |
Шайба МЗ |
|
00011077 |
Гайка М4 |
|
00011004 |
Болт М2 |
Пересечением отношений называется отношение, которое содержит множество кортежей, принадлежащих одновременно и первому и второму отношениям. R1 и R2:
R3 = R1
В отношении R4 содержатся перечень деталей, которые выпускаются одновременно на двух участках цеха.
|
R4 |
|
|
Шифр детали |
Название детали |
|
00011073 |
Гайка Ml |
|
00011076 |
Гайка МЗ |
|
00011006 |
Болт МЗ |
Разностью отношений R1 и R2 называется отношение, содержащее множество кортежей, принадлежащих R1 и не принадлежащих R2:
Отношение R5 содержит перечень деталей,
R5 = RI \ R2 = { г | r

Отношение R5 содержит перечень деталей, изготавливаемых только на участке 1, отношение RG содержит перечень деталей, изготавливаемых только на участке 2.
R6 = R2 \ R1 = { r | r
R5 | |
Шифр детали | Название детали |
00011075 | Гайка М2 |
00011003 | Болт Ml |
00013063 | Шайба Ml |
00013066 | Шайба МЗ |
R6 | |
Шифр детали | Название детали |
00011077 | Гайка М4 |
00011004 | Болт М2 |
R3 | |
Шифр детали | Название детали |
00011073 | Гайка Ml |
00011075 | Гайка М2 |
00011076 | Гайка МЗ |
00011003 | Болт Ml |
00011006 | Болт МЗ |
00013063 | Шайба Ml |
00013066 | Шайба МЗ |
00011077 | Гайка М4 |
00011004 | Болт М2 |
Пересечением отношений называется отношение, которое содержит множество кортежей, принадлежащих одновременно и первому и второму отношениям. R1 и R2:
R3 = R1
здесь ^— операция логического умножения (логическое «И»).
В отношении R4 содержатся перечень деталей, которые выпускаются одновременно на двух участках цеха.
R4 | |
Шифр детали | Название детали |
00011073 | Гайка M1 |
00011076 | Гайка МЗ |
00011006 | Болт МЗ |
Разностью отношений R, и R2 называется отношение, содержащее множество кортежей, принадлежащих R1 и не принадлежащих R2:
R5 = R1 \ R2 = { r | r
Отношение R5 содержит перечень деталей, изготавливаемых только на участке 1, отношение R6 содержит перечень деталей, изготавливаемых только на участке 2.
R6 = R2 \ R1 = { r | r
R5 | |
Шифр детали | Название детали |
00011075 | Гайка М2 |
00011003 | Бол г M1 |
00013063 | Шайба M1 |
00013066 | Шайба МЗ |
R6 | |
Шифр детали | Название детали |
00011077 | Гайка М4 |
00011004 | Болт М2 |
Следует отметить, что первые две операции, объединение и пересечение, являются коммутативными операциями, то есть результат операции не зависит от порядка аргументов в операции. Операция же разности является принципиально несимметричной операцией, то есть результат операции будет различным для разного порядка аргументов, что и видно из сравнения отношений R5 и R6.
В отличие от навигационных средств
В отличие от навигационных средств манипулирования данными в теоретико-графовых моделях операции реляционной алгебры позволяют получить сразу иной качественный результат, который является семантически гораздо более ценным и понятным пользователям. Например, сравнение результатов объединения и разности номенклатуры двух участков позволит оценить специфику производства: насколько оно уникально на каждом участке, и, в зависимости от необходимости, принять соответствующее решение по изменению номенклатуры.
Для демонстрации возможностей трех первых операций реляционной алгебры рассмотрим еще один пример — уже из другой предметной области. Исходными являются три отношения R1 R2 и R3. Все они имеют эквивалентные схемы.
R1= (ФИО, Паспорт, Школа);
R2= (ФИО, Паспорт, Школа);
R3= (ФИО, Паспорт, Школа).
Рассмотрим ситуацию поступления в высшие учебные заведения, которая была характерна для периода, когда были разрешены так называемые репетиционные вступительные экзамены, которые сдавались раньше основных вступительных экзаменов в вуз. Отношение R1 содержит список абитуриентов, сдававших репетиционные экзамены. Отношение, R2 содержит список абитуриентов, сдававших экзамены на общих условиях. И наконец, отношение R3 содержит список абитуриентов, принятых в институт. Будем считать, что при неудачной сдаче репетиционных экзаменов абитуриент мог делать вторую попытку и сдавать экзамены в общем потоке, поэтому некоторые абитуриенты могут присутствовать как в первом, так и во втором отношении.
Ответим на следующие вопросы:
Список абитуриентов, которые поступали два раза и не поступили в вуз. R = R1
Список абитуриентов, которые поступили в вуз с первого раза, то есть они сдавали экзамены только один раз и сдали их так хорошо, что сразу были зачислены в вуз. R = (R1 \ R2
Список абитуриентов, которые поступили в вуз только со второго раза.
Прежде всего это те абитуриенты, которые присутствуют в отношениях R1 и R2, потому что они поступали два раза, и присутствуют в отношении R3, потому что они поступили.
Список абитуриентов, которые поступали только
R = R1
Список абитуриентов, которые поступали только один раз и не поступили.
Это прежде всего те абитуриенты; которые присутствуют в R1 и не присутствуют в R2, и те, кто присутствуют в R2 и не присутствуют в R1. И разумеется, никто из них не присутствует в R3. R = (R1 \ R2)
В отсутствие скобок порядок выполнения операций реляционной алгебры естественный, поэтому сначала будут выполнены операции в скобках, а затем будет выполнена последняя операция вычитания отношения R3.
Операции объединения, пересечения и разности применимы только к отношениям с эквивалентными схемами.
Кроме перечисленных трех теоретико-множественных операций в рамках реляционной алгебры определена еще одна теоретико-множественная операция — расширенное декартово произведение. Эта операция не накладывает никаких дополнительных условий на схемы исходных отношений, поэтому операция расширенного декартова произведения, обозначаемая R1 ® R2, допустима для любых двух отношений. Но прежде чем определить саму операцию, введем дополнительно понятие конкатенации, или сцепления, кортежей.
Сцеплением, пли конкатенацией, кортежей с = <c1, с2, ..., сn> и q = <q1, q2, ..., qm> называется кортеж, полученный добавлением значений второго в конец первого. Сцепление кортежей с и q обозначается как (с , q).
(с, q) = <с1 с2, ... , сn, q1, q2, .... qm>
Здесь n — число элементов в первом кортеже с, m — число элементов во втором кортеже q.
Все предыдущие операции не меняли степени или арности отношений — это следует из определения эквивалентности схем отношений. Операция декартова произведения меняет степень результирующего отношения.
Расширенным декартовым произведением отношения R, степени n со схемой
SR1=(А1,А2...,Аn) и отношения R2 степени m со схемой
SR2=(В1,В2, ... , Вm) называется отношение R3 степени n+m со схемой
SR3 = (А1, А2, ... , Аn, В1, В2, ..., Вm),
содержащее кортежи, полученные сцеплением каждого кортежа г отношения R] с каждым кортежем q отношения R2.
с учетом возможности перестановки атрибутов
То есть если R1 = { r }, R2 = { q }
R1
Операцию декартова произведения с учетом возможности перестановки атрибутов в отношении можно считать симметричной. Очень часто операция расширенного декартова произведения используется для получения некоторого универсума — т. е. отношения, которое характеризует все возможные комбинации между элементами отдельных множеств. Однако самостоятельного значения результат выполнения операции обычно не имеет, он участвует в дальнейшей обработке. Например, на производстве в отношении 07 задана обязательная номенклатура деталей для всех цехов, а в отношении 08 дан перечень всех цехов.
|
R7 |
|
|
Шифр детали |
Название детали |
|
00011073 |
Гайка M1 |
|
00011075 |
Гайка М2 |
|
00011076 |
Гайка МЗ |
|
00011003 |
Болт М1 |
|
00011006 |
Болт МЗ |
|
00013063 |
Шайба Ml |
|
00013066 |
Шайба МЗ |
|
00011077 |
Гайка М4 |
|
000ll004 |
Болт М2 |
|
00011005 |
Болт М5 |
|
00011006 |
Болт М6 |
|
00013062 |
Шайба М2 |
|
R8 |
|
Цех |
|
Цех 1 |
|
Цех 2 |
|
Цех 3 |
| R9 | ||
|
Шифр детали |
Название детали |
Цех |
|
00011073 |
Гайка Ml |
Цех 1 |
|
00011075 |
Гайка М2 |
Цех 1 |
|
00011076 |
Гайка МЗ |
Цех 1 |
|
00011003 |
Болт Ml |
Цех 1 |
|
00011006 |
Болт МЗ |
Цех 1 |
|
00013063 |
Шайба Ml |
Цех 1 |
|
00013066 |
Шайба МЗ |
Цех 1 |
|
00011077 |
Гайка М4 |
Цех 1 |
|
00011004 |
Болт М2 |
Цех 1 |
|
00011005 |
Болт М5 |
Цех 1 |
|
00011006 |
Болт Мб |
Цех 1 |
|
00013062 |
Шайба М2 |
Цех 1 |
|
00011073 |
Гайка Ml |
Цех 2 |
|
00011075 |
Ганка М2 |
Цех 2 |
| R10 | ||
|
Шифр |
Название детали |
Цех |
|
00011073 |
Гайка Ml |
Цех 1 |
|
(МО И 075 000 11 076 |
Гайка М2 Гайка МЗ |
Цех 1 Цех 1 |
|
000 11 003 |
! Болт Ml |
Цех 1 |
|
0011 0006 |
Болт МЗ |
Цех 1 |
|
00013063 |
Шайба Ml |
Цех 1 |
|
000 11060 |
Шайба МЗ |
Цех 1 |
| 000 11 004 |
Болт М2 |
Цех 1 |
| 00011077 | Гайка М4 | Цех 1 |
|
00011006 |
Болт МЗ |
Цех2 |
|
00013063 |
Шайба Ml |
Цех 2 |
| 0013066 | Шайба МЗ | Цех 2 |
| 00011077 | Гайка М4 | Цех 2 |
| 0001 0778 | Болт М2 | Цех 2 |
В каких запросах нужно использовать
00011076 | Гайка МЗ | Цех 2 |
00011U03 | Болт Ml | Цех 2 |
00011006 | Болт МЗ | Цех 2 |
00013063 | Шайба Ml | Цех 2 |
00013066 | Шайба МЗ | Цех 2 |
00011077 | Гайка М4 | Цех 2 |
00011004 | Болт М'2 | Цех 2 |
00011005 | Болт М5 | Цех 2 |
00011006 | Болт Мб | Цех 2 |
00013062 | Шайба М2 | Цех 2 |
00011073 | Гайка Ml | ЦсхЗ |
00011075 | Гайка М2 | ЦехЗ |
00011076 | Гайка МЗ | Цех 3 |
00011003 | Болт Ml | ЦехЗ |
00011006 | Болт МЗ | ЦехЗ |
00013063 | Шайба Ml | Цех 3 |
00013066 | Шайба МЗ | ЦехЗ |
00011077 | Гайка М4 | ЦехЗ |
00011004 | Болт М2 | Цех 3 |
00011005 | Болт М5 | ЦехЗ |
00011006 | Болт Мб | ЦехЗ |
00013062 | Шайба М2 | ЦехЗ |
00011006 | Болт Мб | Цех 2 |
00013062 | Шайба М2 | Цех 2 |
00011073 | Гайка Ml | ЦeхЗ |
00011075 | Гайка М2 | ЦехЗ |
00011076 | Гайка МЗ | ЦехЗ |
00011003 | Болт Ml | ЦехЗ |
00011006 | Болт МЗ | Цех 3 |
00013063 | Шайба Ml | Цех 3 |
00013066 | Шайба МЗ | ЦехЗ |
00011077 | Гайка М4 | Цeх3 |
00011005 | Болт М5 | Цех3 |
00011006 | Болт Мб | Цех3 |
00011005 | Болт М5 | Цех 1 |
00011006 | Болт Мб | Цех 1 |
00013062 | Шайба М2 | Цех1 |
В каких запросах нужно использовать расширенное декартово произведение? Эта операция моделирует некоторую ситуацию, которая характеризуется словом «все». Поэтому если нам надо узнать, какие детали в каких цехах из общей обязательной номенклатуры не выпускаются, то мы можем вычесть из полученного отношения R9 отношение R10, характеризующее реальный выпуск деталей в каждом цехе.
Отношение R11, которое является результатом выполнения этой операции, имеет вид:
R11 = R9 \ R10
R11 | ||
Шифр детали | Название детали | Цех |
00011073 | Гайка Ml | Цех 2 |
00011075 | Гайка М2 | Цех 2 |
00011076 | Гайка МЗ | Цех 2 |
00011004 | Болт М2 | ЦехЗ |
00013062 | Шайба М2 | ЦехЗ |
00011003 | Болт Ml | Цех 2 |
00011005 | Болт М5 | ЦехЗ |
Группа теоретико-множественных операций избыточна, так, например, операцию можно заменить сочетанием операций объединения и пересечения.
(R1
Однако это достаточно сложная формула, и именно поэтому все три теоретико-множественные операции вошли в базовый набор операций реляционной алгебры.
Далее мы переходим к группе операций, названных специальными операциями реляционной алгебры.
Задания для самостоятельной работы
Задание 1
Даны отношения, моделирующие работу банка и его филиалов. Клиент может иметь несколько счетов, при этом они могут быть размещены как в одном, так и в разных филиалах банка. В отношении R1 содержится информация обо всех клиентах и их счетах в филиалах нашего банка. Каждый клиент, в соответствии со своим счетом, может рассчитывать на некоторый кредит от нашего банка, сумма допустимого кредита также зафиксирована.
|
R, |
||||
|
ФИО клиента |
№ филиала |
№ счета |
Остаток |
Кредит |
|
|
|
|||
|
R2 |
|
|
№ филиала |
Район |
|
|
|
С использованием языка реляционной алгебры составить запросы, позволяющие выбрать:
Филиалы, клиенты которых имеют счета с остатком, превышающим $1000.
Клиентов, которые имеют счета во всех филиалах данного банка.
Клиентов, которые имеют только по одному счету в разных филиалах банка. То есть в общем у этих клиентов может быть несколько счетов, но в одном филиале не более одного счета.
Клиенты, которые имеют счета в нескольких филиалах банка расположенных только в одном районе.
Филиалы, которые не имеют ни одного клиента.
Филиалы, которые имеют клиентов с остатком на счету 0 (ноль).
Филиалы, у которых есть клиенты с кредитом, превышающим остаток на счету в 2 раза.
Задание 2
Даны отношения, моделирующие работу международной фирмы, имеющей несколько филиалов. Филиалы фирмы могут быть расположены в разных странах, это отражено в отношении R1. Клиенты фирмы также могут быть из разных стран, и это отражено в отношении R4. По каждому конкретному заказу клиент мог заказать несколько разных товаров.
|
R1 |
|
|
Филиал |
Страна |
|
|
|
|
R2 |
||
|
Филиал |
Заказчик |
№ заказа |
|
|
|
|
|
R3 |
||
|
N заказа |
Товар |
Количество |
|
|
|
|
|
R4 |
|
|
Заказчик |
Страна |
|
|
|
С использованием реляционной алгебры составить запросы, позволяющие выбрать:
Заказчиков, которые работают со всеми филиалами фирмы, но покупают только один товар.
Филиалы фирмы, которые торгуют всеми товарами.
Товары, которые фирма продает только в одной стране.
Заказчиков, которые работают с филиалами фирмы, которые расположены только в одной стране.
Филиалы, с которыми не работает ни один заказчик.
Заказчиков, которые работают только с филиалами, расположенными в той же стране, что и заказчик.
Заказчиков, которые покупают все товары, представленные в отношении R3.
