Администрирование баз данных
Администратор данных - менеджер, отвечающий за определение общей политики и процедур информационной системы организации.
Администратор базы данных - менеджер, отвечающий за управление техническими аспектами системы управления базами данных.
В дополнение к этим основным обязанностям АБД играет ведущую роль в планировании и разработке базы данных, а также в обучении пользователей. Обучение касается следующих вопросов:
1. Как технология базы данных может помочь на разных уровнях менеджмента (важно для завоевания и поддержания заинтересованности менеджеров в системе управления базами данных).
2. Реальные ожидания от базы данных (важно для снижения недовольства пользователей работой базы данных).
3. Процедуры решения информационных задач (важно для поддержания эффективности системы и удовлетворения пользовательских потребностей).
Хотя точное место АБД в структуре организации может несколько меняться, однако разумная иерархия предложена на рис. 1.1,а. Так, начальник информационного отдела подчиняется исполнительному директору, а начальнику информационного отдела подчиняется АБД. Если в компании существует АД, то АБД может быть передвинута на одну ступеньку вниз, подчиняясь АД (рис. 1.1,б).
Теперь мы переходим к рассмотрению конкретных функций, выполняемых АБД.
Целостность на уровне ссылок
При построении реляционных таблиц для связывания строк одной таблицы со строками другой таблицы используются внешние ключи. Например, ТИП_СПЕЦИАЛЬНОСТИ используется в таблице РАБОТНИК для того, чтобы сообщить нам основную специальность каждого работника, чтобы можно было подсчитать размер премиальных. Таким образом, важно, чтобы значение атрибута ТИП_СПЕЦИ-АЛЬНОСТИ каждой строки, обозначающей служащего, соответствовал некоторому значению атрибута ТИП_СПЕЦИ-АЛЬНОСТИ в таблице СПЕЦИАЛЬНОСТЬ. В противном случае ТИП_СПЕЦИАЛЬНОСТИ служащего ни на что не будет указывать. БД, в которой все непустые внешние ключи ссылаются на текущие значения ключей другой реляционной таблицы, обладает целостностью на уровне ссылок.
COUNTRY
101
105
110
Мальтц
Джефф
Гомес
П/я 102
П/я 98
П/я 76
Австрия
США
Чили
75 314
49 333
27 400
14
23
37
39
Масаи Матцу
Франсуа Муар
Элена Армана
Горо Ацума
44
35
12
44
Токио
Брюссель
Буэнос-Айрес
Токио
11
13
10
PRODUCT
2241
2518
Настольная лампа
Бронзовая скульптура
317
253
22.25
13.60
33.25
21.20
SALE
12.02
12.02
19.02
22.02
25.02
25.02
101
101
100
101
105
110
23
23
39
23
10
37
2518
1035
2518
1035
2241
2518
300
150
200
200
100
150
6360.00
3300.00
4240.00
4400.00
3325.00
3180.00
MANUFACTURER
253
317
Медные изделия
Лампы Лланс
Лагос
Лима
Нигерия
Перу
Рис. 1.2. Образец данных из файловой системы IPD
Предположим, что эти файлы допускают лишь последовательный доступ. Это означает, что каждая запись в файле может быть прочитана и обработана только после того, как прочитаны все предшествующие ей записи в файле. Именно так обстояло дело в шестидесятые годы, когда хранение информации на диске обходилось относительно дорого. Большинство файлов хранилось на ленте, и записи извлекались и обрабатывались последовательно. Обычно с файлами работали в пакетном режиме, то есть все записи файла обрабатывались за один раз, обычно ночью, после закрытия офиса.
Файлы использовались во множестве различных приложений. Например, программа подсчета причитающихся сумм составляла счета для клиентов. Она использовала файлы CUSTOMER и SALE (ПРОДАЖА). Оба файла были упорядочены по CUST-ID; объединяя эти файлы, программа распечатывала счета, как показано на рис. 1.3. Поле BEGINNING-BALANCE (ИСХОД-БАЛАНС) в файле CUSTOMER обновлялось, отражая последние сделки. Уже произведенные платежи, подсчитанные другой программой и внесенные в файл CUSTOMER, были записаны в поле MONTH-TO-DATE-PAYMENTS (ВЫПЛАЧЕНО-НА-СЕГОДНЯ); они также печатались в счете.
101
105
110
Мальтц
Джефф
Гомес
П/я 102
П/я 98
П/я 76
Австрия
США
Чили
75 314
49 333
27 400
ДАТА
1015
1020
14.02
20.02
110
100
37
14
INVOICE LINE
Декартово произведение
Декартово произведение
выполняется над двумя таблицами R1 ,R2, которые имеют разный состав атрибутов: (d




R2, которая включает все атрибуты исходных таблиц (d
Пример. Декартово произведение двух таблиц R1 «Студент» (табл.4.6) и R2 «Предмет» (табл. 4.7.) дает новую таблицу RD «Экзаменационная ведомость» (табл.4.8).
Таблица 4.6. R1 «Студент»
| Номер | Фамилия | ||||
| К11
К12 К13 | 11
12 13 | Иванов
Петров Сидоров |
Таблица 4.7. R2 «Предмет»
| Код | Наименование | ||||
| К21
К22 | П1
П2 | Математика
Информатика |
Таблица 4.8. RD «Экзаменационная ведомость»
| Номер | Фамилия | Код | Наименование | ||||||||
| К11
К11 К12 К12 К13 К13 | К21
К22 К21 К22 К21 К22 | 11
12 13 11 12 13 | Иванов
Петров Сидоров Иванов Петров Сидоров | П1
П1 П1 П2 П2 П2 | Математика
Математика Математика Информатика Информатика Информатика |
Деление
Деление – операция выполняется над двумя таблицами R1, R2, которые имеют разную структуру и некоторые одинаковые атрибуты. В результате операции образуется новая таблица, структура которой получается исключением из множества атрибутов таблицы R1 множество атрибутов таблицы R2. Результирующие строки не должны содержать дубликаты.
Пример. Рассмотрим таблицу R1 «Товар» (табл.4.18) и таблицу R2 «Агент» (табл.4.19). Предположим, что у нас есть такой запрос: перечислить торговых агентов с указанием проданных товаров. Результатом этого запроса будет таблица R3 (табл.4.20).
Таблица 4.18 R1
| № товара | |
| 1035 | |
| 2241 | |
| 2249 | |
| 2518 |
Таблица 4.19 R2
| № агента | № товара | ||
| 10 | 2241 | ||
| 23 | 2518 | ||
| 23 | 1035 | ||
| 39 | 2518 | ||
| 37 | 2518 | ||
| 10 | 2249 | ||
| 23 | 2249 | ||
| 23 | 2241 |
Таблица 4.20 R3
| № агента | |
| 23 |
Рассмотренные выше операции в той или иной мере реализуются в средствах СУБД, которые обеспечивают обработку реляционных таблиц. К таким средствам относятся средства запросов и другие языковые конструкции.
Развитие реляционного подхода привело к созданию реляционных языков. Например, язык SQL, реализованный в большинстве СУБД. Он включает в себя, помимо операций реляционной алгебры, полный набор операторов над строками - «включить», «удалить», «обновить», а также реализует арифметические операции и операции сравнения.
Другие недостатки традиционных файловых систем
Несмотря на появление файлов с произвольным доступом, быстро стало очевидным, что файловые системы любого типа обладают некоторыми врожденными недостатками:
q
Избыточность данных.
q Слабый контроль данных.
q Недостаточные возможности управления данными.
q Большие затраты труда программиста.
20 символов 15 символов 15 символов
Запись текущего Запись сберегательного Запись ссуды
счета счета
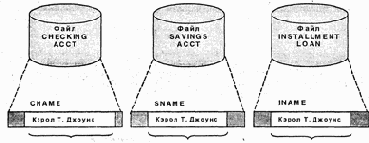
Рис. 1.5. Имя клиента, представленное в разных полях
Избыточность данных. Главная трудность состоит в том, что многие приложения используют свои собственные файлы данных. Таким образом, некоторые единицы данных повторяются в разных приложениях. Например, в банке одно и то же имя клиента встречается в файлах, содержащих сведения о текущих счетах, сберегательных счетах и ссудах (рис. 1.5). Более того, хотя это одно и то же имя клиента, соответствующие поля в разных файлах могут называться по-разному. Так, поле CNAME файла текущих счетов превращается в SNAME файла сберегательных счетов и в INAME файла ссуд. Одно и то же поле в разных файлах может, кроме того, иметь разную длину. Например, поле CNAME может содержать до 20 символов, а поля SNAME и INAME допускают максимальную длину 15 символов. Следствием такой избыточности данных являются лишние затраты на поддержание и хранение данных. Избыточность данных также порождает риск противоречий между разными версиями общих данных.
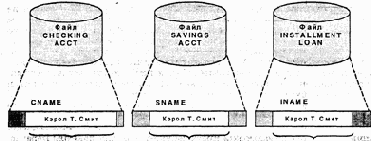
Предположим, что клиент изменил имя с Кэрол Т.Джоунс на Кэрол Т.Смит. Изменение могло быть сразу внесено в файл текущих счетов, через неделю - в файл сберегательных счетов, а в файл ссуд изменение могло оказаться внесенным неверно - Кэрол Т.Смит (рис. 1.6). По прошествии некоторого времени подобные расхождения могут существенно снизить качество информации, содержащейся в файлах данных.
Такая несогласованность данных может также отразиться на точности отчетов. Предположим, что вы хотите составить отчет, в котором должны
20 символов 15 символов 15 символов
Запись текущего Запись сберегательного Запись ссуды
счета счета
Рис. 1.6. Неверные изменения имени клиента
быть перечислены все клиенты, имеющие текущие счета или сберегательные счета, которые брали у банка ссуды. Кэрол Т.Смит будет пропущена в этом отчете, поскольку в файле ссуд ее имя выглядит как Кэрол Т.Смит. Как мы вскоре увидим, информационные системы, использующие базы данных, позволяют избавиться от подобной избыточности данных, поскольку все приложения используют один и тот же набор данных. Существенная информация, например, имя или адрес клиента, будет записываться в базе данных всего один раз. Таким образом, мы сможем изменять адрес или имя клиента один раз, будучи при этом уверены, что все приложения будут пользоваться согласованными данными.
Слабый контроль данных. В файловых системах, как мы уже успели заметить, отсутствует централизованный контроль на уровне элементов данных. Весьма часто один и тот же элемент данных имеет несколько имен в зависимости от того, в какие файлы он входит.
На более фундаментальном уровне всегда существует вероятность того, что разные отделы компании пользуются терминологией, не согласованной с остальными. Например, банк может вкладывать в термин счет один смысл применительно к сбережениям и совсем другой применительно к ссудам. Разные значения одного и того же термина называются омонимами. И наоборот, разные слова могут иметь одинаковые значения. Страховая компания может говорить о владельце полиса или о клиенте, вкладывая в эти два термина один и тот же смысл. Термины, имеющие одно и то же значение, называются синонимами. Система управления базами данных осуществляет централизованный контроль данных и помогает избежать недоразумений, порожденных омонимами и синонимами.
Омонимы - разные значения одного и того же термина.
Синонимы -
термины, имеющие одно и то же значение.
Недостаточные возможности управления данными. Индексно-последовательные файлы позволяют обращаться к определенной записи по ключу, например, по идентификатору товара. Например, если мы знаем идентификатор настольной лампы, мы можем напрямую извлечь из файла PRODUCT относящуюся к ней запись. Этого достаточно до тех пор, пока нам нужна отдельная запись.
Однако предположим, что нам нужен целый ряд связанных между собой записей. Например, мы хотим найти все продажи клиенту Мальтц. Допустим, что мы также хотим узнать общее число таких продаж, среднюю цену или же список товаров, купленных клиентом и кто является изготовителем этих товаров. Такую информацию будет трудно, если не невозможно, извлечь из файловой системы, поскольку файловые системы не позволяют устанавливать связь между данными разных файлов. Системы управления базами данных были специально разработаны для того, чтобы упростить связывание данных из разных файлов.
Большие затраты труда программиста. Новая прикладная программа часто требовала совершенно нового набора файлов. Даже если существующий уже файл содержал некоторые нужные данные, приложению часто требовался еще какой-либо набор элементов данных. В результате программисту приходилось перекодировать определения нужных элементов данных из существующих файлов, а также определять новые элементы данных. Таким образом, в файловой системе существовала жесткая зависимость между программами и данными.
Что еще более важно, манипулирование данными в файлово-ориентированных языках (таких как Кобол) было слишком сложным для создания больших приложений. Это означало, что затраты труда программиста как на создание приложения, так и на поддержание его работы были весьма значительны.
Базы данных позволили разделить программы и данные, так что программа может быть в некотором смысле независима от
2. Реляционная модель данных
Файловые системы
Первые коммерческие компьютерные системы использовались в основном для ведения бухгалтерии: дебет, кредит, ведомости заработной платы и т.д. Эту работу предприятие обязано делать. Следовательно, оправдать стоимость компьютерной системы было несложно. Затраты ручного труда, например, на ведение ведомостей по заработной плате или выписывание счетов, были столь велики, что автоматическая система, которая могла выполнять эти функции, быстро окупалась.
Поскольку эти системы выполняли обычные функции работы с документами, они были названы системами обработки данных. Неудивительно, что программисты и аналитики, разрабатывавшие эти системы, подражали в своих программах тем операциям, которые прежде выполнялись вручную. Так например, компьютерные файлы соответствовали папкам для бумаг, и компьютерный файл содержал ту информацию, которая вполне могла бы лежать в одной обычной папке.
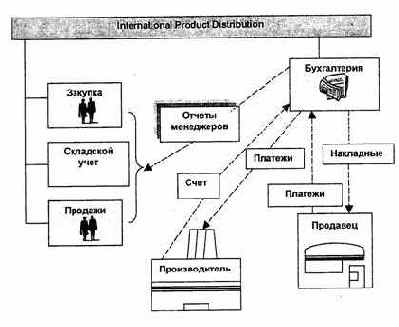
Рис. 1.1. Поиск информации IPD
На рис. 1.1, 1.2 представлены некоторые файлы и образцы данных первой файловой. Каждая таблица представляет один файл системы. Таким образом, мы видим файлы CUSTOMER (КЛИЕНТ), SALES-REPRESENTATIVE (ТОРГОВЫЙ-АГЕНТ), PRODUCT (ТОВАР) и т.д. Каждая строка соответствует одной записи в файле. Так, файл PRODUCT содержит три записи. Каждая из этих записей относится к отдельному товару. Элементарные группы данных или поля файла PRODUCT таковы: PROD-ID (ИД-ТОВАРА), PROD-DESC (ОПИСАНИЕ-ТОВАРА), MANUPACTR-ID (ИД-ИЗГОТОВИТЕЛЯ), COST (ЗАКУПОЧНАЯ ЦЕНА) и PRICE (ЦЕНА ПРОДАЖИ).
CUSTOMER | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Функции АБДФункции АБД могут главным образом лежать в области работы с пользователями базы данных, планирования, проектирования и реализации информационных систем, а также определения стандартных процедур. Планирование, проектирование и реализация информационных систем рассматривались в предыдущих главах, и мы исключим их из дальнейшего изложения. Функциональные зависимости и детерминантыФункциональные зависимости (ФЗ) позволяют накладывать дополнительные ограничения на реляционную схему. Основная идея состоит в том, что значение одного атрибута в кортеже однозначно определяет значение другого атрибута. Например, в каждом кортеже таблицы 3.1 № работника однозначно определяет фамилию; № работника однозначно определяет специальность. Записываются эти две функциональные зависимости следующим образом: ФЗ : № работника ¾> фамилия, ФЗ : № работника ¾> специальность.
Функциональная зависимость – значение атрибута в кортеже однозначно определяет значение другого атрибута в кортеже. Более формально мы можем определить функциональную зависимость следующим образом: если А и В – атрибуты в таблице R, то запись ФЗ : A¾> В обозначает, что если два кортежа в таблице R имеют одно и то же значение атрибута А, то они имеют одно и то же значение атрибута В. Это определение также применимо, если А и В – множества столбцов, а не просто отдельные столбцы. Обозначение ¾> читается «функционально определяет». Атрибут в левой части ФЗ называется детерминантом, так как его значение однозначно определяет значение атрибута в правой части. Ключ таблицы всегда является детерминантом, так как его значение однозначно определяет значение каждого атрибута таблицы. Идентификация пользователяДоступ к базе данных обычно требует идентификации пользователя и подтверждения его полномочий. При идентификации пользователя первый уровень защиты базы данных проверяет, что пользователь, обращающийся к системе, зарегистрирован. Его или ее личность может быть установлена при помощи: чего-то, что пользователь знает, например, номер подключения и пароля; чего-то, чем пользователь обладает, например, пластиковая идентификационная карточка; Физической идентификации (отпечатка пальца или голоса). Пароль на сегодняшний день - наиболее распространенный и зачастую самый дешевый способ защиты, подходит для многих приложений. Идеальная схема паролей ограничивает доступ к системе при помощи паролей, которые трудно угадать, но при этом пользователю достаточно легко их помнить. Для некоторых приложений может оказаться достаточно задать параметры пароля, такие как длина и алфавит, а затем позволить пользователю самому выбрать пароль. При использовании такой схемы следует назначить ответственного за пароль, который будет проверять, что параметры пароля выдержаны и что не возникло повторов. Для особо уязвимых систем следует рассмотреть более сложную схему защиты. В одной из таких схем используется программа, задающая пользователю вопросы, которые сам он ранее ввел в систему вместе с ответами. Вопросы обычно носят личный характер, так что только сам пользователь может ответить на них правильно. Возможны подобные последовательности вопросов: Когда у вашей подруги день рождения? Чем примечательно для вас 2 сентября? Когда пользователь обращается к системе и вводит свой идентификационный номер, компьютер задает вопросы, случайным образом выбранные из записаных ранее. Выбор вопросов меняется от случая к случаю, чтобы другой человек не мог подсмотреть ответы на все вопросы. Еще один способ защиты от несанкционированного доступа состоит в использовании предопределенного алгоритма. То есть компьютер предлагает пользователю случайно выбранное число и запрашивает ответ. Пользователь выполняет над числом заранее определенное преобразование и вводит результат. Компьютер сравнивает полученное значение с тем, которое он вычислил. Если они совпадают, то доступ разрешается. Еще одним средством предотвращения несанкционированного доступа к системе служит задание типов транзакций, которые можно запустить с каждого терминала. Предоставить каждому терминалу крайне узкий круг возможностей – довольно эффективный и простой способ контроля. Например, терминалы, находящиеся в довольно доступном месте, могут выполнять только функции чтения данных. Иерархические и сетевые модели системИндексно-последовательные файлы решили проблему прямого обращения к определенной записи в файле. Для примера посмотрим снова на рис. 1.2. Если мы прочли первую запись о продажах в файле SALE и хотим узнать имя и адрес клиента, с которым была заключена эта сделка, мы можем просто воспользоваться идентификатором клиента (100), чтобы посмотреть соответствующую запись в файле CUSTOMER. Таким образом, мы выясним, что заказ был сделан компанией братьев Уотэйб. Теперь предположим, что нам требуется обратный процесс. Вместо того чтобы выяснять, с каким клиентом заключена сделка, мы хотим найти все продажи данному клиенту. Мы начнем с записи «Братья Уотэйб» в файле CUSTOMER, а затем найдем все продажи этой компании. В файловой системе мы не сможем напрямую получить ответ на наш вопрос. Именно для подобных прикладных задач и были придуманы системы управления базами данных. Первая информационная система, использующая базы данных, появившаяся в середине шестидесятых годов, была основана на иерархической модели, что означает, что отношения между данными имеют иерархическую структуру. Для того чтобы пояснить это, слегка изменим базу данных, приведенную на рис. 1.2. Вместо продаж, записанных в виде одной строки, у нас будут счета-фактуры, которые, в свою очередь, состоят из нескольких строк. К каждому клиенту может относиться несколько таких счетов, и каждый счет может состоять из нескольких строк. Каждая строка обозначает продажу одного товара. На рис. 1.7 представлен пример. Теперь вместо файла SALE у нас есть файлы INVOICE (СЧЕТ) и INVOICE LINE (СТРОКА-СЧЕТА). Иерархическая модель - модель данных, в которой связи между данными имеют вид иерархий.
Рис. 1.7. Файлы IPD, имеющие иерархическую структуру На рис. 1.8 показано, как выглядит иерархия отношений между клиентами, счетами и строками счетов. Клиенту «подчинены» счета, которым, в свою очередь, «подчинены» строки. В иерархической базе данных эти три файла будут связаны между собой физическими указателями, или полями данных, добавленными к отдельным записям. Указатель - это физический адрес, означающий, где запись находится на диске. Каждая запись о клиенте будет содержать указатель первой записи счета этого клиента. В свою очередь, записи счетов будут содержать указатели на другие записи счетов и на записи строк счетов. Таким образом, система легко сможет извлечь все записи счетов и строк счетов, относящихся к данному клиенту. Указатель - физический адрес, обозначающий место хранения записи на диске. Предположим, что мы хотим добавить в нашу иерархическую базу данных информацию о клиентах. Например, если наши клиенты - торговые компании, нам может понадобиться список магазинов каждой компании. В этом случае мы расширим диаграмму, приведенную на рис. 1.8, придав ей вид, представленный на рис. 1.9. Файл CUSTOMER по-прежнему находится над файлом INVOICE, который находится над файлом INVOICE LINE. Но в то же время с файлом CUSTOMER связан файл STORE (МАГАЗИН), а с ним — файл CONTACT (ПРЕДСТАВИТЕЛЬ). Под представителем мы подразумеваем закупщика, которому продаем товары для конкретного магазина. Из этой диаграммы мы видим, что клиент является вершиной иерархии, из которой мы можем извлечь немало информации.
Рис. 1.8. Иерархическая модель отношений между файлами CUSTOMER, INVOICE и INVOICE LINE На этих диаграммах показаны те разновидности связей между файлами, которые могут быть легко реализованы в иерархической модели. Однако быстро стало ясно, что у такой модели есть некоторые существенные ограничения, поскольку не все отношения можно представить в виде иерархии. Например, вернемся к нашему примеру и сделаем следующий шаг. Очевидно, что нас могут интересовать связи не только между клиентами и счетами, но и между торговыми агентами и счетами. То есть мы хотим иметь список всех счетов на продажи, произведенные определенным торговым агентом, чтобы подсчитать сумму причитающихся ему комиссионных. Новые связи представлены на рис. 1.10.
Однако эта диаграмма не является иерархической. В иерархии у каждого потомка может быть только один предок. На рис. 1.9 INVOICE - потомок, CUSTOMER - его предок. Однако на рис. 1.10 у INVOICE имеется два предка - SALES-REPRESENTATIVE и CUSTOMER. Такого рода диаграммы называются сетевыми. В связи с очевидной необходимостью обрабатывать такие отношения в конце шестидесятых появились сетевые системы управления базами данных. Как и в иерархических, в сетевых системах баз данных для связывания файлов использовались физические указатели.
Потомок - подчиненная запись в иерархии. Предок - подчиняющая запись в иерархии. Сеть - отношения между данными, когда каждая подчинена записям более, чем из одного файла. Основная иерархическая СУБД - система IMS фирмы IBM, созданная в середине шестидесятых годов.В конце шестидесятых - начале семидесятых были созданы и завоевали рынок несколько сетевых СУБД; стандартом для такой модели, в конце концов, стал CODASYL. В последующих главах мы обсудим обе эти модели данных, требуемые для них определения данных и возможности управления данными. Метод поалфавитной подстановкиПредположим, мы хотим зашифровать то же самое сообщение, но теперь у нас есть ключ шифра, например, «защита». Тогда: 1. Ключ пишется под текстом и повторяется столько раз, чтобы полностью «закрыть» текст: идет снег защитазащ. 2. Будем считать, что пробел занимает тридцать третье и последнее место в алфавите. Для каждого символа сложим номер в алфавите символа текста и соответствующего символа ключа, разделим на 33 и сохраним остаток. Заменим символ текста на символ, имеющий вычисленный номер. В нашем примере под пробелом (33) стоит т (19), таким образом (33+19)= 52, остаток от деления на 33 равен 19. На 19 месте в алфавите стоит буква т, поэтому вместо пробела в зашифрованном тексте будет т. Многотабличные запросыВозможность связывать элементы данных вне границ одной таблицы важна для любого языка баз данных. SQL связывает данные разных таблиц аналогично тому, как это делает операция соединения реляционной алгебры. Рассмотрим запрос. Запрос: Вывести специальности рабочих, назначенных на здание 435. Данные, необходимые для ответа, находятся в двух таблицах: «Работник» и «Работа». Для решения в SQL требуется перечислить обе таблицы в команде FROM и задать специальный тип условия WHERE: SELECT Специальность FROM Работник, Работа WHERE Работник. № работника = Работа. № работника AND № здания = 435 Рассмотрим два этапа обработки системой данного запроса. 1. Сначала обрабатывается фраза FROM. Однако в этом случае, поскольку в команде указаны две таблицы, система создает декартово произведение строк этих таблиц. Если в команде FROM перечислено более двух таблиц, то создается декартово произведение всех таблиц, указанных в команде. 2. После создания гигантской реляционной таблицы система применяет команду WHERE. Каждая строка таблицы, созданной командой FROM, проверяется на выполнение условия WHERE. Строки, не удовлетворяющие условию, исключаются из рассмотрения. Затем к оставшимся строкам применяется фраза SELECT. Фраза WHERE в данном запросе содержит два условия: 1. WHERE Работник. № работника = Работа. № работника 2. № здания = 435 Первое из этих условий – условие соединения. Так как обе таблицы содержат столбец с именем «№ работника», их декартово произведение будет содержать два столбца с таким именем. Для того чтобы различить их, помещаем перед именем столбца имя исходной таблицы, отделяя его точкой. Полное соединение этих двух таблиц представлено на рис. 7.2.
Рис. 5.2. Соединение таблиц «Работник» и «Работа» Результат: штукатур электрик В SQL можно за один раз связать более двух таблиц: Запрос: Вывести фамилии работников, назначенных на здания офисов. SELECT Фамилия FROM Работник, Работа, Здание WHERE Работник. № работника = Работа. № работника AND Работа. № здания = Здание. № здания AND Тип = 'офис' Результат: Фамилия И. Петров Команды SQL этого запроса создают одну таблицу из трех реляционных таблиц БД. Первые две таблицы создаются по «№ работника», после чего к полученной таблице присоединяется третья таблица по «№ здания». Условие «Тип = 'офис'« команды WHERE приводит к исключению всех строк, кроме относящихся к офисным зданиям. Это соответствует требованиям запроса. Необходимость произвольного доступа к даннымОграниченные возможности файловых систем с чисто последовательным доступом не помешали им быть эффективным средством для составления раз или два раза в месяц счетов, платежных ведомостей и других отчетов. Однако для выполнения большого количества рутинной работы требуется произвольный доступ - возможность напрямую обращаться к конкретной записи без предварительной сортировки файла или последовательного чтения всех записей. Для того чтобы программа расчета причитающихся сумм обрабатывала продажи вместе с файлом CUSTOMER, файл SALE должен быть упорядочен по индексу клиента. Поскольку продажи, скорее всего, вводились как попало, нам придется упорядочивать файл SALE, прежде чем использовать его в качестве исходных данных для программы. Это показано на рис. 1.3. Однако, если файл SALE упорядочен по индексу клиента, он наверняка находится в полном беспорядке относительно индекса товара. Таким образом, общую сумму продажи невозможно посчитать, обратившись к файлу PRODUCT. Из-за этого служащие вынуждены вводить лишние данные, что требует дополнительной затраты ручного труда и увеличивает количество ошибок. Необходимость последовательного доступа к файлам иным образом вынуждает пользователей выполнять лишнюю работу. Например, другая программа IPD подсчитывает комиссионные со сделок и составляет счета на оплату работы агентов. Для того чтобы подсчитать комиссионные, причитающиеся агенту, мы снова должны упорядочить файл SALE, на сей раз по SALREP-ID. И только после этого мы можем обрабатывать файлы SALE и SALES-REPRESENTATIVE вместе, чтобы составить счета на оплату работы агентов (рис. 1.4). Приведенная ситуация иллюстрирует наиболее серьезные ограничения, которые накладывает требование чисто последовательного доступа к файлам. Эти проблемы были частично решены с появлением файлов произвольного доступа и, особенно, индексно-последовательных (ИП) файлов, которые широко распространились в шестидесятые годы. Файлы произвольного доступа, в отличие от файлов последовательного доступа, позволяют извлекать записи в произвольном порядке.
Нормализация отношений
Нормализация отношения - процесс приведения реляционных таблиц к стандартному виду. Рассмотрим реляционную таблицу на рис. 3.1. После небольшого анализа видно, что реляционная таблица на рис. 3.1 спроектирована неудачно. Например, в четырех кортежах, соответствующих рабочему 1412, повторяется одно и то же имя и информация о типе специальности. Эта избыточность данных или повторение приводит не только к потере лишнего места; она может вызвать нарушение целостности данных (противоречивость) в базе данных.
Избыточность данных - повторение данных в базе данных. Целостность данных - согласованность данных в базе данных. Таблица 3.1. «Работник»
Проблема возникает из-за того, что один и тот же работник может работать более, чем на одном здании. Предположим, что специальность Смирнова была указана неправильно, а исправление было внесено только в первый кортеж. Тогда между кортежами, содержащими информацию о Смирнове, возникает несоответствие, которое называется аномалией обновления.
Аномалия обновления - противоречивость данных, вызванная их избыточностью и частичным обновлением. Теперь предположим, что Смирнов в течение трех месяцев был на больничном и все здания, на которых он был назначен работать, уже закончены. Если принимается решение удалить все строки о законченных зданиях из таблицы, то информация о Смирнове, его специальности будет потеряна. Это называется аномалией удаления. Обратный случай: мы могли нанять нового работника по фамилии Сидоров, которого еще не успели назначить ни на какое здание. Если мы не допускаем пустых значений, то не можем ввести информацию о Сидорове в базу данных. Это называется аномалией ввода. Аномалия удаления - непреднамеренная потеря данных, вызванная удалением других данных. Аномалия ввода - невозможность ввести данные в таблицу, вызванная отсутствием других данных. Аномалии обновления, удаления и ввода, очевидно, нежелательны. Чтобы предотвратить или хотя бы свести к минимуму подобные проблемы нужно воспользоваться нормальными формами или правилами структурирования таблиц. Нормализация - за и противНормализация таблиц БД призвана устранить из них избыточную информацию. Как видно из приведенных выше примеров, таблицы нормализованной БД содержат только один элемент избыточных данных - это поля связи, присутствующие одновременно у родительской и дочерних таблиц. Поскольку избыточные данные в таблицах не хранятся, экономится дисковое пространство.  Рис.3.20. Нормализованная база данных Однако у нормализованной БД есть и недостатки, прежде всего практического характера. Чем шире число сущностей, охватываемых предметной областью, тем из большего числа таблиц будет состоять нормализованная БД. Базы данных в составе больших систем, управляющих жизнедеятельностью крупных организаций и предприятий, могут содержать сотни связанных между собою таблиц. Поскольку порог человеческого восприятия не позволяет одновременно анализировать большое число объектов с учетом их взаимосвязей, можно утверждать, что с увеличением числа нормализованных таблиц уменьшается целостное восприятие базы данных как системы взаимосвязанных данных. Поэтому при разработке и эксплуатации крупных систем нередки ситуации, когда каждый сотрудник представляет себе процессы, протекающие только в части системы. Известны случаи эволюционного создания таких систем, принципы функционирования которых впоследствии признавались вышедшими за границы понимания. Другим недостатком нормализованной БД является необходимость считывать связанные данные из нескольких таблиц при выполнении одного запроса. Например, пусть для рассмотренной выше БД требуется выдать отчет, в котором для каждой накладной указан покупатель и его реквизиты (город и адрес). Для этого необходимо каждую запись в таблице «Накладные» объединить по названию покупателя (поле связи) с соответствующей записью из таблицы «Покупатели». Операции такого объединения подразумевают поиск и позиционирование в таблице «Покупатели» и могут выполняться достаточно медленно, особенно когда одна из таблиц имеет большой объем, данные в базе данных и на диске фрагментированы и т.д. Замечено, что ненормализованные или не вполне нормализованные данные отыскиваются быстрее, если они хранятся в одной таблице, по сравнению со случаем поиска данных в одной или более связанных таблицах. Подобное ускорение тем заметнее, чем больше число записей в связанных таблицах. Таким образом, при работе с данными большого объема приходится искать компромисс между требованиями нормализации (то есть логичности данных и экономии места на носителях информации) и необходимостью улучшения быстродействия системы. Нормальная форма Бойса-Кодда (НФБК)Реляционная таблица находится в нормальной форме Бойса-Кодда (НФБК), если для любой ФЗ: X¾> Y, X ( то есть детерминанта) является возможным ключом отношения. Из определения следует, что любая таблица, удовлетворяющая НФБК, также удовлетворяет и 2НФ, однако обратное неверно. Рассмотрим таблицу 3.9 «Оплата за работу». № Работника является ключом, следовательно, в таблице имеются функциональные зависимости: ФЗ: № Работника ¾> Разряд; ФЗ: № Работника ¾> Оплата. Однако также имеется функциональная зависимость ФЗ: Разряд ¾> Оплата.
Атрибут «разряд» является детерминантой, так как он однозначно определяет атрибут «оплата», но «разряд» не может быть ключом отношения, поэтому в таком виде отношение «Оплата за работу» не удовлетворяет НБКФ. Но таблица 3.9 удовлетворяет 2НФ (так как неключевые атрибуты «разряд» и «оплата»). Таким образом, таблица может быть в 2НФ, но не в НФБК. Таблица 3.9. «Работник»
Чем плохи таблицы, не удовлетворяющие НФБК? Вызванные ими проблемы схожи с перечисленными для таблиц, нарушающих 2НФ: 1. Размер премиальных для типа специальности повторяется в каждой строке, относящейся к работнику этой специальности. Это избыточные данные, занимающие лишнее место. 2. Если размер премиальных для типа специальности изменяется, то требуется обновить каждую строку. Если строка удаляется, то мы можем потерять информацию о размере премиальных для данной специальности. Таким образом, таблица подвержена аномалиям обновления и удаления. 3. Если в какой-то момент времени отсутствуют работники данной специальности, то может не оказаться строки, в которой можно хранить размер премиальных. Это аномалия ввода. Для того чтобы решить эти проблемы, таблицу необходимо разбить на несколько таблиц для устранения аномалий и поддержания целостности данных. Создадим новую таблицу 3.10 «Работник 1», удалив из таблицы 3.9 все атрибуты, стоящие в правой части ФЗ, нарушающие критерий НФБК. В нашем примере это Премиальные. Создадим новую таблицу 3.11 «Работник 2», состоящую из атрибутов, как из левой, так и из правой части ФЗ, нарушающей критерий НФБК. В нашем примере это Специальность и Премиальные. Детерминант ФЗ Специальность будет ключом. Таблица 3.10. «Работник 1»
ОбъединениеОбъединение – операция выполняется над двумя совместимыми таблицами R1, R2. В результате этой операции строится новая таблица R = R1 U R2. Таблица R имеет тот же состав атрибутов и кортежей исходных таблиц. Причем одинаковые кортежи не дублируются. Пример. Ниже приведены исходные таблицы: R1 «Клиенты банка А» (табл.4.1) и R2 «Клиенты банка В» (табл. 4.2) и результат объединения - R (табл.4.3). Таблица 4.1. R1 «Клиенты банка А»
Таблица 4.2. R2 «Клиенты банка В»
Таблица 4.3. R «Клиенты»
В новую таблицу R не вошел кортеж К21, так как он дублирует кортеж К11. 4.2. Пересечение Пересечение – операция выполняется над двумя совместимыми таблицами R1, R2. В результате этой операции получается новая таблица RP = R1 З R2. Эта таблица содержит одинаковые кортежи, которые есть в каждой из двух исходных таблиц. Пример. Пересечение двух таблиц R1 «Клиенты банка А» и R2 «Клиенты банка В» дает одну таблицу R «Клиент» (табл. 4.4). Таблица 4.4. Пересечение отношений
Обработка транзакцийТранзакция - это блок программы, выполнение которого сохраняет непротиворечивость БД. Неделимая транзакция – транзакция, в которой либо все связанные с ней действия выполняются до конца, либо ни одно из них не выполняется. Если БД непротиворечива до выполнения транзакции, то она должна оставаться непротиворечивой и после ее выполнения. Для того чтобы обеспечить выполнение этих условий, транзакции должны быть неделимыми, что означает, что либо все действия, связанные с транзакцией, выполняются до конца, либо ни одно из них не выполняется. Например, транзакция записи взноса клиента на сумму 500 $ включает следующие действия: 1. Изменение записи клиента: уменьшение суммы счета на 500 $. 2. Изменение кассовой записи: увеличение суммы на 500 $. Предположим, что второй шаг не выполняется. Тогда баланс счетов не будет сходиться. На рис.5.1 показано, что происходит, когда эти действия выполняются как последовательность независимых шагов (а) и когда они выполняются как единая неделимая транзакция (б). Для обработки транзакций требуется, чтобы СУБД поддерживала запись транзакции для каждого изменения, вносимого в БД. Один из способов – применение протокола. Когда клиент платит 500 $ по счету, транзакция включает 1) уменьшение счета клиента и 2) увеличение кассового счета. Во время выполнения транзакции все записанные операции задерживаются до тех пор, пока не будет выполнено последнее действие транзакции. Результаты обновления записываются в протокол транзакций. Когда все действия выполнены, информация об обновлении из протокола используется для переноса обновленной информации в соответствующие записи данных. ДЕЙСТВИЯ РЕЗУЛЬТАТ
СЧЕТ КЛИЕНТА 1.
КАССОВЫЙ СЧЕТ 2. Отказ КАССОВЫЙ СЧЕТ системы Баланс Баланс
СЧЕТ КЛИЕНТА ТРАНЗАКЦИЯ РЕЗУЛЬТАТ
КАССОВЫЙ СЧЕТ Баланс  Никакие изменения не сделаны, так как транзакция не была успешно выполнена (б) Результат применения неделимой транзакции Рис. 5.1. Независимые и неделимые транзакции Операции с данными в реляционной моделиОперации обработки данных включают операции над строками таблиц и операции над отношениями. Операциями над строками таблиц являются: включение, удаление, обновление. При включении в таблицу добавляется новая строка (кортеж). Для выполнения этой операции требуется задать имя таблицы и указать значения атрибутов новой строки. При удалении из таблицы удаляется строка. Для выполнения этой операции требуется задать имя таблицы и указать значение первичного ключа удаляемой строки. Для удаления группы строк надо задать значение вторичного ключа. При обновлении происходит изменение значений атрибутов в строках. Для этой операции требуется задать имя таблицы, значение первичного ключа обновляемой строки, а также указать имена атрибутов и их новые значения. Основными операциями над отношениями реляционной модели данных являются традиционные операции над множествами: объединение, пересечение, разность (вычитание), декартово произведение, а также специальные операции: выбор, проекция, соединение, деление. А теперь рассмотрим каждую из этих операций. Но сначала введем такое понятие как совместимые таблицы – это такие таблицы, которые имеют в точности одни и те же столбцы, то есть у них совпадает как количество столбцов, так и области столбцов. Определения и понятияБазы данных (БД) всегда создаются для хранения сведений об определенном виде деятельности. Это может быть любой вид деятельности - от коллекционирования марок до ведения домашнего хозяйства. Любая БД хранит сведения о некоторой части реального мира - о людях и предметах, вовлеченных в деятельность, о происходящих событиях, фактах и т.д. Часть реального мира, сведения о которой хранятся в БД, называется предметной областью (ПО) базы данных. В БД хранятся только те сведения, которые представляют интерес с точки зрения соответствующего вида деятельности. Так, в вузе о студенте Иванове как о лице, участвующем в процессе обучения, нужно знать, в какой группе он учится, какие оценки по каким предметам получал и т.д. В поликлинике о пациенте Иванове нужно знать, когда и по какому поводу он обращался к врачу, каков его резус-фактор, группа крови и т.д., но совсем ни к чему здесь сведения об его успеваемости. Объекты - это вовлеченные в деятельность люди, предметы, места, происходящие события и т.д., информация о которых должна храниться в БД. Можно сказать, что объект есть то, что в словесном описании ПО обозначается именем существительным. Например, СТУДЕНТ, ПРЕПОДАВАТЕЛЬ, УЧЕБНАЯ ДИС-ЦИПЛИНА, АУДИТОРИЯ - объекты ПО «Учебный процесс». ПАЦИЕНТ, ПАЛАТА, ВРАЧ - объекты ПО «Больница». Объекты обладают определенным набором свойств, которые называются атрибутами. Например: фамилия студента, номер студбилета, номер группы, адрес - атрибуты, соответствующие характеристикам объекта ПО СТУДЕНТ. Объект ПРЕПОДАВАТЕЛЬ имеет такие атрибуты, как: фамилия, номер диплома, специальность, ученая степень и т.д. В таблице 2.1 приведены экземпляры объекта ПРЕПОДАВАТЕЛЬ с атрибутами НОМЕР, ФИО, Кафедра. Таблица 2.1
Между отдельными таблицами БД могут существовать связи. Например, информация о покупателе в предыдущей таблице может дополняться в другой (рис. 2.2).
Базы данных, между отдельными таблицами которых существуют связи, называются реляционными (от relation - связь, отношение). Связанные отношениями таблицы взаимодействуют по принципу главная (master) - подчиненная (detail). В нашем примере таблица «Отпуск товаров» - главная, а таблица «Покупатель» - подчиненная. Главную таблицу часто называют родительской, а подчиненную - дочерней. Одна и та же таблица может быть главной по отношению к одной таблице БД и дочерней по отношению к другой. Основные понятия и определенияВ сетевой модели существуют два основных понятия: типы записей и наборы. Типы записей - это совокупность логически связанных записей. Например, тип записи клиент может включать такие элементы данных, как ИД-Клиент, Имя, Адрес, Сумма-Счета, Дата-Последнего-Платежа. Все типы записей - это заданные имена, такие как КЛИЕНТ, СЧЕТ, ТОРГОВЫЙ АГЕНТ и т.д. Наборы - это отношения один-ко-многим (или один-к-одному) между двумя типами записей. Например, один набор выражает отношения один-ко-многим между записями клиентов и подлежащих оплате ими счетов. В любом сетевом наборе один тип записей является владельцем, а остальные - членами. В данном примере тип записи клиент является владельцем, а тип записи счета – членом. Отношение один-ко-многим допускает возможность, что с записью клиент может быть связано ноль, одна или несколько записей счетов. Конечно, бывают ситуации, когда отношения - строго один-к-одному, как, например, между грузовиком и его водителем, но они обрабатываются таким же образом. Имя набора - это метка, которая присвоена стрелке. Все эти понятия проиллюстрированы примером, приведенным на рис.6.1. |  |
Рис.6.1 является примером трехуровневого дерева. В данном случае дерево состоит из типов сегментов ОТДЕЛ, СЛУЖАЩИЙ, СПЕЦИАЛЬНОСТЬ, НАЗНАЧЕН НА и их отношений.
базы данных отдела Отношение многие-ко-многимНа рис. 2.5 показаны таблицы, состоящие в отношении многие-ко-многим. Каждой учебной группе соответствует несколько преподавателей. Каждый преподаватель может вести, во-первых, несколько разных предметов и, во-вторых, преподавать в разных группах. Таблица «Учебные группы Таблица и дисциплины» «Преподаватели»
Рис. 2.5. Связь многие-ко-многим Некоторые СУБД не поддерживают связи многие-ко-многим на уровне индексов и ссылочной целостности (см. следующий подраздел), хотя и позволяют реализовывать ее в таблицах неявным образом. Считается, что БД всегда можно перестроить так, чтобы любая связь многие-ко-многим была заменена на одну или более связей один-ко-многим. Отношение один-к-одномуОтношение один-к-одному имеет место, когда одной записи в родительской таблице соответствует одна запись в дочерней таблице (рис. 2.4.). Таблица «Сотрудники» Таблица «Информация о сотрудниках»  Рис. 2.4 Связь один-к-одному. Данное отношение встречается много реже, чем отношение один-ко-многим. Его используют, если не хотят, чтобы таблица БД «распухала» от второстепенной информации. Связь один-к-одному приводит к тому, что для чтения связанной информации в нескольких таблицах приходится производить несколько операций чтения, что замедляет получение нужной информации. Кроме того, базы данных, в состав которых входят таблицы со связью один-к-одному, не могут считаться полностью нормализованными (о нормализации см. ниже). Подобно связи один-ко-многим, связь один-к-одному может быть жесткой и нежесткой. Отношение один-ко-многимТаблица «Товары» Таблица «Отпуск товаров»  Рис. 2.3. Связь один-ко-многим Как видно из рис. 2.3, одной записи из родительской таблицы «Товары» может соответствовать несколько записей в дочерней таблице «Отпуск товаров». Обратите внимание на глагол может: он означает, что такая возможность - потенциальная и что в родительской таблице могут быть записи, для которых в данный момент нет записей в дочерней таблице (например, товар «Куры»). Различают две разновидности связи один-ко-многим: в первом случае выдвигается жесткое требование, согласно которому всякой записи в родительской таблице должны соответствовать записи в дочерней таблице; во втором случае подобное требование не носит жесткого характера и подразумевается (как в описанном выше случае), что некоторые записи в родительской таблице могут не иметь связанных с ними записей в дочерней таблице. Связь один-ко-многим является самой распространенной для реляционных баз данных. Она позволяет моделировать иерархические структуры данных. Параллельная работа с БДПредположим, что Лига Женщин-Избирателей (ЛЖИ) из Москвы решила устроить обед с окороком и индейкой. Коммерческая Палата (КП) из Томска решила, что пришло время порадовать своих членов обедом с окороками и овощами. Каждая организация обратилась в своем городе в представительство фирмы «Хелми». ЛЖИ требует 25 окороков, КП нужно 35 окороков. Оба заказа передаются в систему БД регионального склада одновременно (рис. 5.2). Заказ ЛЖИ приходит на долю секунды раньше, чем заказ КП.  КЛ ">  ЛЖИ "> ЛЖИ
Москва
КП  
ЛЖИ КП
Порядок обработки ЦП
Рис. 5.2 Пример параллельной обработки Образ инвентарной записи об окороках помещается в рабочую область компьютера. Запись показывает, что на складе есть 100 окороков. Но прежде чем транзакция ЛЖИ завершается и инвентарная запись обновляется, транзакция КП также приводит к созданию в рабочей области еще одной копии той же инвентарной записи, показывающей, что на складе 100 окороков. Обе записи показывают, что заказ можно выполнить. 
Предположим, что транзакция ЛЖИ завершена первой. Переписанная инвентарная запись показывает 100-25=75 окороков, оставшихся на складе. После завершения транзакции КП инвентарная запись снова будет переписана, показывая 100-35=65 окороков на складе. В результате на самом деле получается, что из 100 окороков на складе продано 60, то есть осталось 40, но запись в системе показывает, что их осталось 65. Этот пример отражает основную сущность параллельной обработки. ЛЖИ КП
Бесконечное Бесконечное ожидание ожидание  Рис. 5.4 Схема блокировки, приводящая к тупиковой ситуации Общим способом предупреждения проблем, связанных с параллельной обработкой, является простая блокировка. В нашем примере первая транзакция должна заблокировать инвентарную запись об окороках, т.е. запретить доступ к ней других транзакций (рис.5.3) до тех пор, пока обработка первой транзакции не будет завершена. Когда запись заблокирована одним пользователем, никакой другой пользователь не может обращаться к ней для обновления. Предположим, что и ЛЖИ, и КП хотят заказать окорока и индеек (рис.5.4). ЛЖИ сначала обращается к инвентарной записи об индейках. Поскольку эта запись заблокирована, то КП сначала обращается к инвентарной записи об окороках. Таким образом, обе записи заблокированы для доступа других пользователей. Затем и ЛЖИ, и КП заканчивают обработку записей об индейках и окороках и готовы обращаться к другой записи. Однако ни один из пользователей не завершил выполнение транзакции, поэтому обе записи остаются заблокированными. Существует несколько способов справляться с взаимоблокировкой. Один подход – фиксировать порядок обращения к записям. Т.е., если требуется обращаться к записям А и В, то к ним всегда нужно обращаться именно в таком порядке. В нашем примере при требовании записей об окороках и индейках можно заставить систему всегда сначала обращаться к записи об окороках, а затем - к записи об индейках. Когда ЛЖИ закончит обработку, все записи, к которым обращались, будут разблокированы и готовы к работе КП. Однако в результате скорость работы может упасть, поскольку ожидание увеличивает время выполнения транзакций. Более того, если транзакция слишком долго ожидает разблокирования записи, она может быть отменена и ее придется запускать заново. Обычно все это приводит к недовольству пользователей информационной системой. Некоторые СУБД выполняют детекцию взаимоблокировки, регулярно проверяя, не слишком ли долго продолжается ожидание записи или ресурса. Другой метод детекции состоит в том, что проводится стрелка от транзакции к искомой записи, а затем стрелка от записи к транзакции, которая в данный момент ее использует. Если граф имеет петли, то это означает, что обнаружена взаимоблокировка. Это показано на рис. 5.5 .

БД Используется Используется Рис.5.5 Взаимоблокировка, обнаруженная при помощи детектирующих циклов Процедуры детекции взаимоблокировки завершают свою работу, отменяя одну из транзакций и продвигая следующую транзакцию в очереди. Другой способ контроля параллельной обработки - двухфазная блокировка. Говорят, что транзакция следует протоколу двухфазной блокировки, если все операции блокировки - read_lock, write_lock - предшествуют первой операции разблокирования в транзакции. Опция read_lock позволяет считывать запись, а write_lock позволяет и считывать, и обновлять данную запись. Проверено, что транзакции могут выполняться так, что их результаты будут такими же, как если бы они выполнялись одна за другой без прерывания. Однако у двухфазной блокировки тоже есть свои недостатки. Она может привести к взаимоблокировке, если совместно с ней не применяется протокол предотвращения взаимоблокировки. В качестве примера на рис. 5.6 видим процедуру двухфазной блокировки, приводящую к взаимоблокировке.  Рис.5.6 Пример двухфазной блокировки, приведшей к взаимоблокировке Транзакция 1 (Т1) задает опцию read_lock для записи О (окорок); одновременно Т2 задает опцию read_lock для записи И (индейка). Через два шага и Т1, и Т2 требуют опцию write_lock для той записи, которая удерживается опцией read_lock другой транзакции. Такое действие запрещено, так как в этом случае значение может быть изменено операцией записи, выполненной другой транзакцией. Тогда конкурирующий источник опции read_lock может считать неверное значение. Применение двухфазной блокировки с протоколом предотвращения взаимоблокировки показано на рис.5.7. Добавили требование того, чтобы все элементы данных, необходимые в транзакции, блокировались заранее. Если какие-либо из элементов данных недоступны, то ни один элемент не блокируется и транзакция задерживается до тех пор, пока все нужные ей элементы не будут доступны.  Рис. 5.7. Пример двухфазной блокировки с протоколом предотвращения взаимоблокировки На рис.5.8 приведен пример, демонстрирующий параллельные операции, которые можно привести к последовательной форме.  Рис.5.8. Пример двухфазной блокировки с протоколом избежания взаимоблокировки, в результате которого выполняется последовательная обработка Первая нормальная формаРеляционная таблица находится в первой нормальной форме (1НФ), если значения в таблице являются атомарными для каждого атрибута таблицы. Атомарное значение - значение, не являющееся множеством значений или повторяющейся группой. Любая реляционная таблица находится в 1НФ. Для того чтобы пояснить понятие, рассмотрим пример таблицы 3.2, не удовлетворяющей этому условию. Таблица 3.2. «Работник»
Значение атрибута № здания – это множество зданий, на которых работает данный человек. Предположим, что мы хотим получить список рабочих, отделывающих здание 435. Извлечь эту информацию может оказаться непросто, так как идентификатор нужного нам значения запрятан внутри множества в кортеже. Реляционная таблица 3.2 не соответствует 1НФ, так как значения атрибута № здания не являются атомарными. Однако таблица 3.1 имеет 1НФ, так как нужное нам значение, то есть номер конкретного здания, может быть выбрано путем простой ссылки на имя атрибута № здания. Первичные ключи и индексыВ каждой таблице БД может существовать первичный ключ - поле или набор полей, однозначно идентифицирующий запись. Значение первичного ключа в таблице БД должно быть уникальным, то есть в таблице не должно существовать двух или более записей с одинаковым значением первичного ключа. Первичные ключи облегчают установление связи между таблицами. В таблице «Покупатель» таким ключом является одноименное поле. Установив связь по первичному ключу, мы можем выяснить, что, например, 10.02.1999 года со склада было отпущено 100 единиц товара «Сахар» покупателю «Геракл, ТОО», офис которого расположен по адресу: 107005, Москва, 2-я Бауманская ул., 12 (телефон для связи 273-00-14). Поскольку первичный ключ должен быть уникальным, для него могут использоваться не все поля таблицы. В приведенном примере название покупателя вряд ли может быть уникальным, поэтому поле «Покупатель» не может использоваться в качестве первичного ключа. Значительно более редким является совпадение телефонов у двух разных покупателей, поэтому поле «Телефон» в большей степени подходит на роль первичного ключа. Если в таблице нет полей, значения в которых уникальны, для создания первичного ключа в нее обычно вводят дополнительное числовое поле, значениями которого СУБД может распоряжаться по своему усмотрению. Если, например, в таблицу «Покупатель» добавить поле «№№», то связанные таблицы будет выглядеть так:
И таблица:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





















































а) диаграмма КЛИЕНТ ТОРГОВЫЙ АГЕНТ



Связи между записями одной таблицы
Между записями одной таблицы также могут существовать связи, то есть одни записи могут ссылаться на другие.
Пусть в реляционной БД необходимо хранить древовидную структуру произвольного уровня, например, структуру организации (рис. 2.6).

Департамент автоматизации, Техническое управление,
Отдел сетевого оборудования, Ремонтный отдел АТС,
Управление программными системами, Отдел эксплуатации,
Информационная группа, Административная группа,
Диспетчерское бюро, Отдел разработки
Рис. 2.6. Структура организации
В этом случае можно создать таблицу (рис. 2.7), в которой каждому подразделению организации соответствует одна запись. Эта запись ссылается на запись, соответствующую подразделению более высокого уровня, в которое входит данное подразделение. И только в записи о подразделении самого высокого уровня нет подобной ссылки.
| № подразделения | Название подразделения | № подразделения предыдущего уровня | |||
| 1 | Департамент автоматизации | ||||
| 2 | Техническое управление | 1 | |||
| 3 | Управление разработки и эксплуатации программных систем | 1 | |||
| 4 | Отдел сетевого оборудования | 2 | |||
| 5 | Ремонтный отдел | 2 | |||
| 6 | АТС | 2 | |||
| 7 | Отдел эксплуатации | 3 | |||
| 8 | Отдел разработки | 3 | |||
| 9 | Информационная группа | 7 | |||
| 10 | Административная группа | 7 | |||
| 11 | Диспетчерское бюро | 10 |
Рис. 2.7. Табличное представление структуры организации
Телефон
2-я Бауманская ул., 12
Измайловский б-р,
ул. Лесная, 1
Теперь в таблице «Отпуск товаров» в поле «Покупатель» указывается значение первичного ключа, построенного по полю «№№» таблицы «Покупатель», что позволяет установить однозначную связь между таблицами.
Вторичные ключи устанавливаются по полям, которые часто используются при поиске и сортировке данных: вторичные ключи (см. п. 2.5) помогут системе значительно быстрее найти нужные данные. В отличие от первичных ключей, поля для индексов могут содержать неуникальные значения - в этом, собственно, и заключается главная разница между первичными и вторичными ключами.
Третья нормальная форма
Реляционная таблица удовлетворяет третьей нормальной форме 3НФ, если она находится в 2НФ и в ней нет транзитивных зависимостей. Транзитивная зависимость возникает, если неключевой атрибут функционально зависит от одного или более неключевых атрибутов.
В данном примере мы привели таблицу 3.6, содержащую цепочку транзитивных зависимостей, к паре таблиц 3.7 и 3.8, находящихся в 3НФ. Для таблицы 3.6. действительны следующие ограничения предметной области:
1) каждый работник имеет только одного менеджера;
2) один менджер может руководить несколькими рабочими.
Таблица 3.6
| № работника | Фамилия работника | № менеджера | Фамилия менеджера | ||||
| 1235 | Иванов | 1311 | Сергеев | ||||
| 1412 | Петров | 1311 | Сергеев | ||||
| 1311 | Сидоров | 1312 | Попов |
Таблица 3.7
| № работника | Фамилия | № менеджера | |||
| 1235 | Иванов | 1311 | |||
| 1412 | Петров | 1311 | |||
| 1311 | Сидоров | 1312 |
Таблица 3.8
| № менеджера | Фамилия
менеджера | ||
| 1311 | Сергеев | ||
| 1312 | Попов |
Упражнения и задачи
Для заданных предметных областей определить:
·
объекты;
· атрибуты.
1. ПРЕДМЕТНАЯ ОБЛАСТЬ (ПО) «ВЫСШЕЕ ОБРАЗОВАНИЕ ГОРОДА».
2. ПРЕДМЕТНАЯ ОБЛАСТЬ «СРЕДНЕЕ ОБРАЗОВАНИЕ».
3. ПРЕДМЕТНАЯ ОБЛАСТЬ «УЧЕБНЫЙ ПРОЦЕСС В ВУЗЕ».
4. ПРЕДМЕТНАЯ ОБЛАСТЬ «ПРОМЫШЛЕННЫЕ ПРЕДПРИЯТИЯ ГОРОДА».
5. ПРЕДМЕТНАЯ ОБЛАСТЬ «СБЫТ ГОТОВЫХ ИЗДЕЛИЙ».
6. ПРЕДМЕТНАЯ ОБЛАСТЬ «БОЛЬНИЦЫ ГОРОДА».
7. ПРЕДМЕТНАЯ ОБЛАСТЬ «ТЕАТРЫ ГОРОДА».
8. ПРЕДМЕТНАЯ ОБЛАСТЬ «ЦЕНТР КРАСОТЫ».
9. ПРЕДМЕТНАЯ ОБЛАСТЬ «КАДРЫ».
10. ПРЕДМЕТНАЯ ОБЛАСТЬ «АБОНЕМЕНТ ТЕХНИЧЕСКОЙ ЛИТЕРАТУРЫ».
1. Установите соответствие между терминами и объяснениями к ним:
|
Нормализация отношения |
повторение данных в базе данных. |
|
Избыточность данных |
процесс приведения реляционных таблиц к стандартному виду |
|
Целостность данных |
противоречивость данных, вызванная их избыточностью и частичным обновлением |
|
Аномалия обновления |
согласованность данных в базе даных. |
|
Аномалия ввода |
непреднамеренная потеря данных, вызванная удалением других данных |
|
Первая нормальная форма (1НФ) |
невозможность ввести данные в таблицу, вызванная отсутствием других данных |
|
Транзитивная зависимость |
значение атрибута в кортеже однозначно определяет значение другого атрибута в кортеже. |
|
Функциональная зависимость |
все неключевые атрибуты являются функционально зависимыми от всего ключа |
|
Третья нормальная форма 3НФ |
значения в таблице являются атомарными для каждого атрибута таблицы |
|
Вторая нормальная форма (2НФ) |
нет транзитивных зависимостей между атрибутами |
|
Аномалия удаления |
неключевой атрибут функционально зависит от одного или более неключевых атрибутов |
2. Для объектов и атрибутов, определенных в упражнении к предыдущему разделу, построить реляционную базу данных в 3НФ.
Для реляционной БД, построенной в предыдущем упражнении, сформулируйте задачи, которые решаются при помощи операций реляционной алгебры.
Базу данных, спроектированную в упражнении раздела 3, преобразуйте в виде сетевой модели.
Базу данных, спроектированную в упражнении раздела 3, преобразуйте в виде иерархической модели.
Часть 2. Управление окружением базы данных
1. Установите соответствие между терминами и объяснениями к ним:
|
Данные |
Компьютерная программа, выполняющая определенную практическую задачу |
|
Ключ |
Организованные данные или выводы из них |
|
Информационная система |
Разрозненные факты |
|
Синоним |
Люди, которым требуется информация, содержащаяся в базе данных |
|
Предок |
Люди, ответственные за работу информационной системы, использующей базы данных |
|
Пользователь |
Автоматическая система, обрабатывающая данные и выдающая информацию |
|
Прикладная программа |
Термины, означающие одно и то же |
|
Омонимы |
«Подчиненная» запись в иерархии |
|
Потомок |
«Подчиняющая» запись в иерархии |
|
Информация |
Термины, имеющие одинаковое написание, но разные значения |
|
Обслуживающий персонал |
Поля данных, однозначно определяющие запись |
|
Сервер базы данных |
Обеспечивает конечным пользователям удобный доступ к системе |
|
Графический пользовательский интерфейс |
Обслуживает доступ к базе данных клиентских машин |
2. Определите ключ каждого файла на рис. 1.2.
3. Какие из следующих утверждений могут рассматриваться как данные, какие - как информация?
· Маршалл Добри в этом году получил комиссионных на большую сумму, чем любой другой торговый агент.
· Маршалл Добри родился 12 декабря 1960 года.
· В каждом месяце последнего квартала в западном регионе производились продажи на сумму более 000 долларов.
· Товар А235 выгоднее.
· Товар А235 производится фирмой Де Муан.
5. Организуйте следующие файлы для базы данных банка иерархическим образом: ВЗНОС, СБЕРЕГАТЕЛЬНЫЙ СЧЕТ, ДЕПОЗИТ, КЛИЕНТ, ССУДА, СНЯТИЕ.
6. Организуйте следующие файлы в сетевую модель базы данных транспортной компании: ГРУЗ, ТРАНСПОРТ, ОТПРАВИТЕЛЬ, УПАКОВКА, ПОЛУЧАТЕЛЬ.
7. В задачах 4 и 5 определите поля, которые могут содержаться в каждом файле. Определите ключ каждого файла.
8. Объясните, каким образом неконтролируемый одновременный доступ к базе данных может вызвать проблемы в следующих ситуациях:
· При резервировании мест в системе продажи авиабилетов.
· При обновлении количества товара в системе инвентарного учета.
· При обновлении баланса текущих счетов в банке.
Установление стандартов и процедур
Эффективная работа администрации базы данных включает в себя разработку общих стандартов и процедур. Их целью является эффективный контроль целостности и защиты данных. Стандарты особенно применимы к разработке и использованию программ и операций базы данных.

Рис. 1.1 Место администрирования базы данных в организации
В области программирования стандарты устанавливаются для обеспечения должной отладки и тестирования программ перед их вводом в эксплуатацию. Эти стандарты могут включать, например, обязательную экспертизу программы компетентными специалистами, не участвовавшими в ее разработке; использование тестовых данных для проверки того, как программа обрабатывает и правильные данные, и данные, содержащие ошибки. Обычная процедура включает документирование результатов испытания программы.
В области операций могут устанавливаться стандарты поддержания протоколов транзакций, а также создаваться процедуры исправления ошибки контрольных точек, создания резервных копий и восстановления.
Организация, у которой недостаточно стандартов и процедур, может столкнуться с трудностями при переходе к сопровождению базы данных, так как интегрированное управление данными на основе баз данных требует хороших, обширных стандартов и процедур. Организации, начинающей установку базы данных, может быть, полезно изучить стандарты других организаций, уже работающих с такими системами. Например, следующие основные стандарты и процедуры корпорации Зевс:
1.
Анализ и обработка сообщений о проблемах. В фирме Зевс создана официальная система сообщений о проблемах, целью которой является информирование АБД обо всех ошибках. Сообщения о проблемах анализируются с целью выяснения вероятных причин трудностей. Затем информация передается соответствующему менеджеру или группе пользователей. Каждое сообщение о проблеме содержит полный протокол (время и место возникновения проблемы) и описание. На каждое сообщение его автору должен быть дан официальный ответ, в котором описывается способ решения проблемы.
2. Мониторинг оборудования и программного обеспечения. Состояние всего оборудования и программного обеспечения регулярно проверяется; соответствующим менеджерам или группам пользователей сообщается о повреждениях и отказах, а также их последствиях. Периодически проводится анализ требований к оборудованию и программному обеспечению на основании которого принимаются решения о замене или модернизации, в том числе о дополнительных запоминающих устройствах.
3. Тестирование. При оценке всех новых процедур, программного обеспечения и оборудования проводится проверка их рабочих характеристик. Контроль структуры и непротиворечивости базы данных проводится регулярно.
4. Защита. После консультаций с руководством компании Зевс была проведена классификация групп пользователей по элементам данных, к которым им разрешен доступ, и действиям, которые они могут выполнять над этими данными. Компьютерные операции часто отслеживаются с целью проверки того, что контроль доступа функционирует, как положено.
5. Резервные копии и восстановление. Процедуры создания резервных копий и восстановления регулярно тестируются, чтобы гарантировать эффективность восстановления базы данных после любого возможного отказа. Разработан план действий в чрезвычайных обстоятельствах (в котором предусмотрены возможные стихийные бедствия и катастрофы: наводнение, утечка электроэнергии и т.д.), который регулярно проверяется.
6. Оценка рабочих характеристик. Различным видам деятельности, конкурирующим за ресурсы базы данных (таким, как обработка транзакций, создание отчетов и обработка запросов), определены приоритеты. Эффективность функционирования системы отслеживается при помощи сбора статистики об объеме транзакций, времени отклика, частоте появления ошибок и коэффициенте использования оборудования. Проводятся опросы системных пользователей о том, насколько они довольны работой системы.Размеры базы данных и ее рост также отслеживаются. При необходимости запускаются программы расширения файлов и производится реорганизация базы данных. Анализируются протоколы работы и протоколы аварийных окончаний; по ним подготавливаются отчеты для оценки управления.
7. Контроль целостности. В компании Зевс разработаны планы проверки целостности данных, хранящихся в базе данных.
Вторая нормальная форма
Вторая и третья нормальные формы касаются отношений между ключевыми и неключевыми атрибутами. Реляционная таблица находится во второй нормальной форме (2НФ), если все неключевые атрибуты являются функционально зависимыми от всего ключа. Таким образом, 2НФ может оказаться нарушена только в том случае, когда ключ составной, то есть ключом является набор из нескольких атрибутов.
Рассмотрим реляционную таблицу 3.3. В ней ключ состоит из атрибутов № работника и № здания. Фамилия
определяется атрибутом № работника
и, следовательно, функционально зависит от части ключа. Это означает, что для определения фамилии работника достаточно знать № работника. Таким образом, таблица не удовлетворяет 2НФ. Если оставить эту таблицу в таком виде, не приведя ее к 2НФ, то могут возникнуть следующие проблемы:
1. Фамилия работника повторяется в каждой строке, относящейся к назначению этого работника.
2. Если фамилия работника изменяется, то требуется обновить все строки, содержащие записи о назначениях этого работника. Это аномалия изменения данных.
3. Из-за такой избыточности может возникнуть несоответствие данных, когда в разных строках содержатся разные имена для одного и того же работника.
4. Если в какой-то момент времени работник не имеет назначений, то может не оказаться строки, в которой можно хранить имя работника. Это аномалия ввода данных.
Таблица 3.3. «Назначение 1»
| № работника | №
здания | Дата начала | Фамилия | ||||
| 1235 | 312 | 10.10 | Петров | ||||
| 1412 | 312 | 01.10 | Смирнов | ||||
| 1235 | 515 | 17.10 | Петров | ||||
| 1412 | 460 | 08.12 | Смирнов | ||||
| 1412 | 435 | 15.10 | Смирнов |
Для того чтобы решить эти проблемы, таблицу необходимо разбить на две реляционные таблицы, каждая из которых удовлетворяет 2НФ.
Таблица 3.4. «Работник»
|
№ работника |
Фамилия |
|
1235 |
Петров |
|
1412 |
Смирнов |
|
№ работника |
№ здания |
Дата начала |
|
1235 |
312 |
10.10 |
|
1412 |
312 |
01.10 |
|
1235 |
515 |
17.10 |
|
1412 |
460 |
08.12 |
|
1412 |
435 |
15.10 |
Процесс разбиения на две 2НФ-таблицы состоит из нескольких простых шагов:
1. Создается новая таблица, атрибутами которой будут атрибуты исходной таблицы, входящие в противоречащую правилу ФЗ. Детерминант ФЗ становится ключом новой таблицы.
2. Атрибут, стоящий в правой части ФЗ, исключается из исходной таблицы.
3. Если более одной ФЗ нарушают 2НФ, то шаги 1 и 2 повторяются для каждой такой ФЗ.
4. Если один и тот же детерминант входит в несколько ФЗ, то все функционально зависящие от него атрибуты помещаются в качестве неключевых атрибутов в таблицу, ключом которой будет детерминант.
Выбор
Выбор - операция выполняется над одной таблицей R. В результате операции выборки производится отбор строк из таблицы на основании некоторого условия. Результирующая таблица имеет ту же структуру, но число ее кортежей будет меньше (или равно) исходной таблицы.
Пример. Ниже приведен пример исходной таблицы R «Агент» (табл. 4.9). Предположим, что мы хотим знать всю информацию об агенте Никитине. Результатом этого запроса будет таблица R1 «Агент1» (табл.4.10).
Таблица 4.9. R «Агент»
| № агента | Фамилия | № менеджера | Офис | ||||
| 10 | Петров | 27 | Самара | ||||
| 14 | Лазарев | 44 | Москва | ||||
| 23 | Никитин | 35 | Тверь |
Таблица 4.10 R1 «Агент1»
| № агента | Фамилия | № менеджера | Офис | ||||
| 23 | Никитин | 35 | Тверь |
Вычитание
Вычитание - операция выполняется над двумя совместимыми таблицами R1, R2 с одинаковым набором атрибутов. В результате операции вычитания строится новая таблица RV = R1 – R2, она содержит только те кортежи первой таблицы R1, которые не повторяются в другой таблицы R2.
Пример. Вычитание из таблицы R1 «Клиенты банка А» таблицы R2 « Клиенты банка В», поскольку К11 = К21, дает таблицу R5 «Клиент только банка В»:
R5 = R1 – R2 = {K11, K12, K13} – {K21, K22, K23} = {K12,K13}.
Задачи АБД
Большая часть деятельности, которой занимается администратор базы данных, касается обеспечения качества базы данных и ее доступности. Это согласуется с основными целями администрирования базы данных: поддержание целостности, защиты и доступности данных.
Базу данных необходимо защищать от ошибок ввода и программирования, от намеренного повреждения и от отказов оборудования или программного обеспечения, портящих данные. Защита данных от повреждений является частью задачи поддержания целостности данных. Повреждения могут возникать в результате отказов во время обработки транзакций, логических ошибок, нарушающих допущение о том, что при транзакциях соблюдаются наложенные на базу данных ограничения; кроме того, бывают аномалии, связанные с параллельным обращением к базе данных (параллельной обработкой).
Параллельная обработка (конкуренция). Происходит в тех случаях, когда две или более транзакции одновременно требуют доступа к одной и той же записи базы данных.
Предохранение базы данных от несанкционированного доступа и преднамеренных повреждений называется защитой данных. Хотя граница между целостностью данных и защитой данных не вполне четкая, рабочее определение таково:
1. Целостность касается обеспечения правильности операций, выполняемых пользователями, и поддержания непротиворечивости базы данных.
2. Защита связана с ограничением операций, которые позволено производить тому или иному пользователю.
Вероятные отказы оборудования или программного обеспечения требуют, чтобы были предусмотрены процедуры восстановления базы данных. То есть необходимо обеспечить способ приведения базы данных, поврежденной в результате неправильного функционирования системы, в исходное состояние.
Процедуры восстановления базы данных - средства, при помощи которых база данных, поврежденная в результате каких-либо отказов, может быть восстановлена.