НФ (Первая Нормальная Форма)
1НФ (Первая Нормальная Форма)
Понятие первой нормальной формы уже обсуждалось в главе 2. Первая нормальная форма (1НФ) - это обычное отношение. Согласно нашему определению отношений, любое отношение автоматически уже находится в 1НФ. Напомним кратко свойства отношений (это и будут свойства 1НФ): В отношении нет одинаковых кортежей. Кортежи не упорядочены. Атрибуты не упорядочены и различаются по наименованию. Все значения атрибутов атомарны.
В ходе логического моделирования на первом шаге предложено хранить данные в одном отношении, имеющем следующие атрибуты:
СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ (Н_СОТР, ФАМ, Н_ОТД, ТЕЛ, Н_ПРО, ПРОЕКТ, Н_ЗАДАН)
где
Н_СОТР - табельный номер сотрудника
ФАМ - фамилия сотрудника
Н_ОТД - номер отдела, в котором числится сотрудник
ТЕЛ - телефон сотрудника
Н_ПРО - номер проекта, над которым работает сотрудник
ПРОЕКТ - наименование проекта, над которым работает сотрудник
Н_ЗАДАН - номер задания, над которым работает сотрудник
Т.к. каждый сотрудник в каждом проекте выполняет ровно одно задание, то в качестве потенциального ключа отношения необходимо взять пару атрибутов {Н_СОТР, Н_ПРО}.
В текущий момент состояние предметной области отражается следующими фактами: Сотрудник Иванов, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 1 и во втором проекте "Климат" задание 1. Сотрудник Петров, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 2. Сотрудник Сидоров, работающий во 2 отделе, выполняет в первом проекте "Космос" задание 3 и во втором проекте "Климат" задание 2.
Это состояние отражается в таблице (курсивом выделены ключевые атрибуты):
НФ (Вторая Нормальная Форма)
2НФ (Вторая Нормальная Форма)
Определение 3. Отношение

Замечание. Если потенциальный ключ отношения является простым, то отношение автоматически находится в 2НФ.
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ не находится в 2НФ, т.к. есть атрибуты, зависящие от части сложного ключа:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника является зависимостью от части сложного ключа:
Н_СОТР

Н_СОТР
Н_СОТР
Зависимость наименования проекта от номера проекта является зависимостью от части сложного ключа:
Н_ПРО
Для того, чтобы устранить зависимость атрибутов от части сложного ключа, нужно произвести декомпозицию отношения на несколько отношений. При этом те атрибуты, которые зависят от части сложного ключа, выносятся в отдельное отношение.
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ декомпозируем на три отношения - СОТРУДНИКИ_ОТДЕЛЫ, ПРОЕКТЫ, ЗАДАНИЯ.
Отношение СОТРУДНИКИ_ОТДЕЛЫ (Н_СОТР, ФАМ, Н_ОТД, ТЕЛ):
Функциональные зависимости:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР
Н_СОТР
Н_СОТР
Зависимость номера телефона от номера отдела:
Н_ОТД
НФ (Третья Нормальная Форма)
3НФ (Третья Нормальная Форма)
Определение 4. Атрибуты называются взаимно независимыми, если ни один из них не является функционально зависимым от другого.
Определение 5. Отношение
Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится в 3НФ, т.к. имеется функциональная зависимость неключевых атрибутов (зависимость номера телефона от номера отдела):
Н_ОТД
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение СОТРУДНИКИ_ОТДЕЛЫ декомпозируем на два отношения - СОТРУДНИКИ, ОТДЕЛЫ.
Отношение СОТРУДНИКИ (Н_СОТР, ФАМ, Н_ОТД):
Функциональные зависимости:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР
Н_СОТР
Н_СОТР
НФ (Четвертая Нормальная Форма)
4НФ (Четвертая Нормальная Форма)
Рассмотрим следующий пример. Пусть требуется учитывать данные об абитуриентах, поступающих в ВУЗ. При анализе предметной области были выделены следующие требования: Каждый абитуриент имеет право сдавать экзамены на несколько факультетов одновременно. Каждый факультет имеет свой список сдаваемых предметов. Один и тот же предмет может сдаваться на нескольких факультетах. Абитуриент обязан сдавать все предметы, указанные для факультета, на который он поступает, несмотря на то, что он, может быть, уже сдавал такие же предметы на другом факультете.
Предположим, что нам требуется хранить данные о том, какие предметы должен сдавать каждый абитуриент. Попытаемся хранить данные в одном отношении "Абитуриенты-Факультеты-Предметы":
НФ (Пятая Нормальная Форма)
5НФ (Пятая Нормальная Форма)
Функциональные и многозначные зависимости позволяют произвести декомпозицию исходного отношения без потерь на две проекции. Можно, однако, привести примеры отношений, которые нельзя декомпозировать без потерь ни на какие две проекции.
Пример 3. Рассмотрим следующее отношение
Адекватность базы данных предметной области
Адекватность базы данных предметной области
База данных должна адекватно отражать предметную область. Это означает, что должны выполняться следующие условия: Состояние базы данных в каждый момент времени должно соответствовать состоянию предметной области. Изменение состояния предметной области должно приводить к соответствующему изменению состояния базы данных Ограничения предметной области, отраженные в модели предметной области, должны некоторым образом отражаться и учитываться базе данных.
Алгоритм нормализации (приведение к 3НФ)
Алгоритм нормализации (приведение к 3НФ)
Итак, алгоритм нормализации (т.е. алгоритм приведения отношений к 3НФ) описывается следующим образом.
Шаг 1 (Приведение к 1НФ). На первом шаге задается одно или несколько отношений, отображающих понятия предметной области. По модели предметной области (не по внешнему виду полученных отношений!) выписываются обнаруженные функциональные зависимости. Все отношения автоматически находятся в 1НФ.
Шаг 2 (Приведение к 2НФ). Если в некоторых отношениях обнаружена зависимость атрибутов от части сложного ключа, то проводим декомпозицию этих отношений на несколько отношений следующим образом: те атрибуты, которые зависят от части сложного ключа выносятся в отдельное отношение вместе с этой частью ключа. В исходном отношении остаются все ключевые атрибуты:
Исходное отношение:

Ключ:

Функциональные зависимости:


Декомпозированные отношения:



Шаг 3 (Приведение к 3НФ). Если в некоторых отношениях обнаружена зависимость некоторых неключевых атрибутов других неключевых атрибутов, то проводим декомпозицию этих отношений следующим образом: те неключевые атрибуты, которые зависят других неключевых атрибутов выносятся в отдельное отношение. В новом отношении ключом становится детерминант функциональной зависимости:
Исходное отношение:

Ключ:

Функциональные зависимости:


Декомпозированные отношения:



Замечание. На практике, при создании логической модели данных, как правило, не следуют прямо приведенному алгоритму нормализации. Опытные разработчики обычно сразу строят отношения в 3НФ. Кроме того, основным средством разработки логических моделей данных являются различные варианты ER-диаграмм. Особенность этих диаграмм в том, что они сразу позволяют создавать отношения в 3НФ. Тем не менее, приведенный алгоритм важен по двум причинам. Во-первых, этот алгоритм показывает, какие проблемы возникают при разработке слабо нормализованных отношений. Во-вторых, как правило, модель предметной области никогда не бывает правильно разработана с первого шага. Эксперты предметной области могут забыть о чем-либо упомянуть, разработчик может неправильно понять эксперта, во время разработки могут измениться правила, принятые в предметной области, и т.д. Все это может привести к появлению новых зависимостей, которые отсутствовали в первоначальной модели предметной области. Тут как раз и необходимо использовать алгоритм нормализации хотя бы для того, чтобы убедиться, что отношения остались в 3НФ и логическая модель не ухудшилась.
Анализ декомпозированных отношений
Анализ декомпозированных отношений
Отношения, полученные в результате декомпозиции, находятся в 2НФ. Действительно, отношения СОТРУДНИКИ_ОТДЕЛЫ и ПРОЕКТЫ имеют простые ключи, следовательно автоматически находятся в 2НФ, отношение ЗАДАНИЯ имеет сложный ключ, но единственный неключевой атрибут Н_ЗАДАН функционально зависит от всего ключа {Н_СОТР, Н_ПРО}.
Часть аномалий обновления устранена. Так, данные о сотрудниках и проектах теперь хранятся в различных отношениях, поэтому при появлении сотрудников, не участвующих ни в одном проекте просто добавляются кортежи в отношение СОТРУДНИКИ_ОТДЕЛЫ. Точно также, при появлении проекта, над которым не работает ни один сотрудник, просто вставляется кортеж в отношение ПРОЕКТЫ.
Фамилии сотрудников и наименования проектов теперь хранятся без избыточности. Если сотрудник сменит фамилию или проект сменит наименование, то такое обновление будет произведено в одном месте.
Если по проекту временно прекращены работы, но требуется, чтобы сам проект сохранился, то для этого проекта удаляются соответствующие кортежи в отношении ЗАДАНИЯ, а данные о самом проекте и данные о сотрудниках, участвовавших в проекте, остаются в отношениях ПРОЕКТЫ и СОТРУДНИКИ_ОТДЕЛЫ.
Тем не менее, часть аномалий разрешить не удалось.
Анализ критериев для нормализованных и ненормализованных моделей данных
Анализ критериев для нормализованных и ненормализованных моделей данных
Аномалии обновления
Аномалии обновления
Даже одного взгляда на таблицу отношения СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ достаточно, чтобы увидеть, что данные хранятся в ней с большой избыточностью. Во многих строках повторяются фамилии сотрудников, номера телефонов, наименования проектов. Кроме того, в данном отношении хранятся вместе независимые друг от друга данные - и данные о сотрудниках, и об отделах, и о проектах, и о работах по проектам. Пока никаких действий с отношением не производится, это не страшно. Но как только состояние предметной области изменяется, то, при попытках соответствующим образом изменить состояние базы данных, возникает большое количество проблем.
Исторически эти проблемы получили название аномалии обновления. Попытки дать строгое понятие аномалии в базе данных не являются вполне удовлетворительными [51, 7]. В данных работах аномалии определены как противоречие между моделью предметной области и физической моделью данных, поддерживаемых средствами конкретной СУБД. "Аномалии возникают в том случае, когда наши знания о предметной области оказываются, по каким-то причинам, невыразимыми в схеме БД или входящими в противоречие с ней" [7]. Мы придерживаемся другой точки зрения, заключающейся в том, что аномалий в смысле определений упомянутых авторов нет, а есть либо неадекватность модели данных предметной области, либо некоторые дополнительные трудности в реализации ограничений предметной области средствами СУБД. Более глубокое обсуждение проблемы строгого определения понятия аномалий выходит за пределы данной работы.
Таким образом, мы будем придерживаться интуитивного понятия аномалии как неадекватности модели данных предметной области, (что говорит на самом деле о том, что логическая модель данных попросту неверна!) или как необходимости дополнительных усилий для реализации всех ограничений определенных в предметной области (дополнительный программный код в виде триггеров или хранимых процедур).
Т.к. аномалии проявляют себя при выполнении операций, изменяющих состояние базы данных, то различают следующие виды аномалий: Аномалии вставки (INSERT) Аномалии обновления (UPDATE) Аномалии удаления (DELETE)
В отношении СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно привести примеры следующих аномалий:
Аномалии обновления (UPDATE)
Аномалии обновления (UPDATE)
Фамилии сотрудников, наименования проектов, номера телефонов повторяются во многих кортежах отношения. Поэтому если сотрудник меняет фамилию, или проект меняет наименование, или меняется номер телефона, то такие изменения необходимо одновременно выполнить во всех местах, где эта фамилия, наименование или номер телефона встречаются, иначе отношение станет некорректным (например, один и тот же проект в разных кортежах будет называться по-разному). Таким образом, обновление базы данных одним действием реализовать невозможно. Для поддержания отношения в целостном состоянии необходимо написать триггер, который при обновлении одной записи корректно исправлял бы данные и в других местах.
Причина аномалии - избыточность данных, также порожденная тем, что в одном отношении хранится разнородная информация.
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
Аномалии удаления (DELETE)
Аномалии удаления (DELETE)
При удалении некоторых данных может произойти потеря другой информации. Например, если закрыть проект "Космос" и удалить все строки, в которых он встречается, то будут потеряны все данные о сотруднике Петрове. Если удалить сотрудника Сидорова, то будет потеряна информация о том, что в отделе номер 2 находится телефон 33-22-11. Если по проекту временно прекращены работы, то при удалении данных о работах по этому проекту будут удалены и данные о самом проекте (наименование проекта). При этом если был сотрудник, который работал только над этим проектом, то будут потеряны и данные об этом сотруднике.
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Аномалии вставки (INSERT)
Аномалии вставки (INSERT)
В отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ нельзя вставить данные о сотруднике, который пока не участвует ни в одном проекте. Действительно, если, например, во втором отделе появляется новый сотрудник, скажем, Пушников, и он пока не участвует ни в одном проекте, то мы должны вставить в отношение кортеж (4, Пушников, 2, 33-22-11, null, null, null). Это сделать невозможно, т.к. атрибут Н_ПРО (номер проекта) входит в состав потенциального ключа, и, следовательно, не может содержать null-значений.
Точно также нельзя вставить данные о проекте, над которым пока не работает ни один сотрудник.
Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту).
Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Бинарные отношения (отношения степени 2)
Бинарные отношения (отношения степени 2)
В математике большую роль играют бинарные отношения, т.е. отношения, заданные на декартовом произведении двух множеств

Блокировки
Блокировки
Основная идея блокировок заключается в том, что если для выполнения некоторой транзакции необходимо, чтобы некоторый объект не изменялся без ведома этой транзакции, то этот объект должен быть заблокирован, т.е. доступ к этому объекту со стороны других транзакций ограничивается на время выполнения транзакции, вызвавшей блокировку.
Различают два типа блокировок: Монопольные блокировки (X-блокировки, X-locks - eXclusive locks) - блокировки без взаимного доступа (блокировка записи). Разделяемые блокировки (S-блокировки, S-locks - Shared locks) - блокировки с взаимным доступом (блокировка чтения).
Если транзакция A блокирует объект при помощи X-блокировки, то всякий доступ к этому объекту со стороны других транзакций отвергается.
Если транзакция A блокирует объект при помощи S-блокировки, то запросы со стороны других транзакций на X-блокировку этого объекта будут отвергнуты, запросы со стороны других транзакций на S-блокировку этого объекта будут приняты.
Правила взаимного доступа к заблокированным объектам можно представить в виде следующей матрицы совместимости блокировок. Если транзакция A наложила блокировку на некоторый объект, а транзакция B после этого пытается наложить блокировку на этот же объект, то успешность блокирования транзакцией B объекта описывается таблицей:
BNFнотация
BNF-нотация
Опишем синтаксис оператора выборки данных (оператора SELECT) более точно. При описании синтаксиса операторов обычно используются условные обозначения, известные как стандартные формы Бэкуса-Наура (BNF).
В BNF обозначениях используются следующие элементы: Символ "::=" означает равенство по определению. Слева от знака стоит определяемое понятие, справа - собственно определение понятия. Ключевые слова записываются прописными буквами. Они зарезервированы и составляют часть оператора. Метки-заполнители конкретных значений элементов и переменных записываются курсивом. Необязательные элементы оператора заключены в квадратные скобки []. Вертикальная черта | указывает на то, что все предшествующие ей элементы списка являются необязательными и могут быть заменены любым другим элементом списка после этой черты. Фигурные скобки {} указывают на то, что все находящееся внутри них является единым целым. Троеточие "-" означает, что предшествующая часть оператора может быть повторена любое количество раз. Многоточие, внутри которого находится запятая ".,.." указывает, что предшествующая часть оператора, состоящая из нескольких элементов, разделенных запятыми, может иметь произвольное число повторений. Запятую нельзя ставить после последнего элемента. Замечание: данное соглашение не входит в стандарт BNF, но позволяет более точно описать синтаксис операторов SQL. Круглые скобки являются элементом оператора.
Целостность сущностей
Целостность сущностей
Т.к. потенциальные ключи фактически служат идентификаторами объектов предметной области (т.е. предназначены для различения объектов), то значения этих идентификаторов не могут содержать неизвестные значения. Действительно, если бы идентификаторы могли содержать null-значения, то мы не могли бы дать ответ "да" или "нет" на вопрос, совпадают или нет два идентификатора.
Это определяет следующее правило целостности сущностей:
Правило целостности сущностей. Атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Целостность внешних ключей
Целостность внешних ключей
Т.к. внешние ключи фактически служат ссылками на кортежи в другом (или в том же самом) отношении, то эти ссылки не должны указывать на несуществующие объекты. Это определяет следующее правило целостности внешних ключей:
Правило целостности внешних ключей. Внешние ключи не должны быть несогласованными, т.е. для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительском отношении.
Декартово произведение
Декартово произведение
Определение 5. Декартовым произведением двух отношений





а тело состоит из кортежей, являющихся сцеплением кортежей отношений

таких, что


Синтаксис операции декартового произведения:

Замечание. Мощность произведения
Замечание. Если в отношения
Замечание. Перемножать можно любые два отношения, совместимость по типу при этом не требуется.
Пример 5. Пусть даны два отношения
Декартово произведение множеств
Декартово произведение множеств
Одним из способов конструирования новых объектов из уже имеющихся множеств является декартово произведение множеств.
Пусть
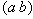







Определение 4. Декартовым (прямым) произведением множеств


Определение 5. Степенью декартового произведения

Замечание. Если все множества


Деление
Деление
Определение 11. Пусть даны отношения







Отношение
Синтаксис операции деления:

Замечание. Типичные запросы, реализуемые с помощью операции деления, обычно в своей формулировке имеют слово "все" - "какие поставщики поставляют все детали?".
Пример 11. В примере с поставщиками, деталями и поставками ответим на вопрос, "какие поставщики поставляют все детали?".
В качестве делимого возьмем проекцию

DELETE удаление строк в таблице
DELETE - удаление строк в таблице
Пример 4. Удаление нескольких строк в таблице: DELETE FROM P WHERE P.PNUM = 1;
Пример 5. Удаление всех строк в таблице: DELETE FROM P;
Для дочернего отношения
Для дочернего отношения
Вставка кортежа в дочернее отношение. Нельзя вставить кортеж в дочернее отношение, если вставляемое значение внешнего ключа некорректно. Вставка кортежа в дочернее отношение привести к нарушению ссылочной целостности.
Обновление кортежа в дочернем отношении. При обновлении кортежа в дочернем отношении можно попытаться некорректно изменить значение внешнего ключа. Обновление кортежа в дочернем отношении может привести к нарушению ссылочной целостности.
Удаление кортежа в дочернем отношении. При удалении кортежа в дочернем отношении ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций: Обновление кортежа в родительском отношении. Удаление кортежа в родительском отношении. Вставка кортежа в дочернее отношение. Обновление кортежа в дочернем отношении.
Для родительского отношения
Для родительского отношения
Вставка кортежа в родительском отношении. При вставке кортежа в родительское отношение возникает новое значение потенциального ключа. Т.к. допустимо существование кортежей в родительском отношении, на которые нет ссылок из дочернего отношения, то вставка кортежей в родительское отношение не нарушает ссылочной целостности.
Обновление кортежа в родительском отношении. При обновлении кортежа в родительском отношении может измениться значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на обновляемый кортеж, то значения их внешних ключей станут некорректными. Обновление кортежа в родительском отношении может привести к нарушению ссылочной целостности, если это обновление затрагивает значение потенциального ключа.
Удаление кортежа в родительском отношении. При удалении кортежа в родительском отношении удаляется значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на удаляемый кортеж, то значения их внешних ключей станут некорректными. Удаление кортежей в родительском отношении может привести к нарушению ссылочной целостности.
Домены
Домены
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами: Домен имеет уникальное имя (в пределах базы данных). Домен определен на некотором простом типе данных или на другом домене. Домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена. Домен несет определенную смысловую нагрузку.
Например, домен


Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику, определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены "Вес детали" и "Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены.
Основное значение доменов состоит в том, что домены ограничивают сравнения. Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов. Синтаксически правильный запрос "выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий "количество" и "вес".
Замечание. Понятие домена помогает правильно моделировать предметную область. При работе с реальной системой в принципе возможна ситуация когда требуется ответить на запрос, приведенный выше. Система даст ответ, но, вероятно, он будет бессмысленным.
Замечание. Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных.
Замечание. Не всегда очевидно, как задать логическое условие, ограничивающее возможные значения домена. Я буду благодарен тому, кто приведет мне условие на строковый тип данных, задающий домен "Фамилия сотрудника". Ясно, что строки, являющиеся фамилиями не должны начинаться с цифр, служебных символов, с мягкого знака и т.д. Но вот является ли допустимой фамилия "Ггггггыыыыы"? Почему бы нет? Очевидно, нет! А может кто-то назло так себя назовет. Трудности такого рода возникают потому, что смысл реальных явлений далеко не всегда можно формально описать. Просто мы, как все люди, интуитивно понимаем, что такое фамилия, но никто не может дать такое формальное определение, которое отличало бы фамилии от строк, фамилиями не являющимися. Выход из этой ситуации простой - положиться на разум сотрудника, вводящего фамилии в компьютер.
Еще пример бинарного отношения
Еще пример бинарного отношения
Пример 5. Пусть множество
Информацию о взаимоотношения данных молодых людей можно описать бинарным отношением "любить", заданном на множестве

Способ 1. Перечисление фактов в виде произвольного текста (как это сделано выше).
Способ 2. В виде графа взаимоотношений:

Рисунок 1 Граф взаимоотношений
Способ 3. При помощи матрицы взаимоотношений:
Естественное соединение
Естественное соединение
Определение 10. Пусть даны отношения



Тогда естественным соединением отношений



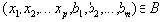
Естественное соединение настолько важно, что для него используют специальный синтаксис:

Замечание. В синтаксисе естественного соединения не указываются, по каким атрибутам производится соединение. Естественное соединение производится по всем одинаковым атрибутам.
Замечание. Естественное соединение эквивалентно следующей последовательности реляционных операций: Переименовать одинаковые атрибуты в отношениях Выполнить декартово произведение отношений Выполнить выборку по совпадающим значениям атрибутов, имевших одинаковые имена Выполнить проекцию, удалив повторяющиеся атрибуты Переименовать атрибуты, вернув им первоначальные имена
Замечание. Можно выполнять последовательное естественное соединение нескольких отношений. Нетрудно проверить, что естественное соединение (как, впрочем, и соединение общего вида) обладает свойством ассоциативности, т.е.

поэтому такие соединения можно записывать, опуская скобки:

Пример 10. В предыдущем примере ответ на вопрос "какие детали поставляются поставщиками", более просто записывается в виде естественного соединения трех отношений

Фиктивные элементы (фантомы)
Фиктивные элементы (фантомы)
Эффект фиктивных элементов несколько отличается от предыдущих транзакций тем, что здесь за один шаг выполняется достаточно много операций - чтение одновременно нескольких строк, удовлетворяющих некоторому условию.
Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора.
Фиктивные элементы (фантомы)
Фиктивные элементы (фантомы)
Транзакция A дважды выполняет выборку строк с одним и тем же условием. Между выборками вклинивается транзакция B, которая добавляет новую строку, удовлетворяющую условию отбора.
Функциональное отношение
Функциональное отношение
Определение 10. Отношение



Обычно, функциональное отношение обозначают в виде функциональной зависимости -

Предикат функционального отношения есть просто выражение функциональной зависимости
Функциональные зависимости
Функциональные зависимости
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ находится в 1НФ, при этом, как было показано выше, логическая модель данных не адекватна модели предметной области. Таким образом, первой нормальной формы недостаточно для правильного моделирования данных.
Функциональные зависимости отношений и математическое понятие функциональной зависимости
Функциональные зависимости отношений и математическое понятие функциональной зависимости
Функциональная зависимость атрибутов отношения напоминает понятие функциональной зависимости в математике. Но это не одно и то же. Для сравнения напомним математическое понятие функциональной зависимости:
Определение 2. Функциональная зависимость (функция) - это тройка объектов






Функциональная зависимость обычно обозначается как


Замечание. Правило
Функциональная зависимость атрибутов отношения тоже напоминает это определение. Действительно: В качестве области определения выступает домен, на котором определен атрибут


Отличие от математического понятия отношения состоит в том, что, если рассматривать математическое понятие функции, то для фиксированного значения



Таким образом, понятие функциональной зависимости атрибутов нельзя считать полностью эквивалентным математическому понятию функциональной зависимости, т.к. значение этой зависимости различны при разных состояниях отношения, и, самое главное, эти значения могут меняться непредсказуемо.
Функциональная зависимость атрибутов утверждает лишь то, что для каждого конкретного состояния базы данных по значению одного атрибута (детерминанта) можно однозначно определить значение другого атрибута (зависимой части). Но конкретные значение зависимой части могут быть различны в различных состояниях базы данных.
Элементы теории множеств
Глава 1. Элементы теории множеств
Базовые понятия реляционной модели данных
Глава 2. Базовые понятия реляционной модели данных
Целостность реляционных данных
Глава 3. Целостность реляционных данных
Во второй части реляционной модели данных определяются два ограничения, которые должны выполняться в любой реляционной базе данных. Это: Целостность сущностей. Целостность внешних ключей.
Прежде, чем говорить о целостности сущностей, опишем использование null-значений в реляционных базах данных.
Реляционная алгебра
Глава 4. Реляционная алгебра
Элементы языка SQL
Глава 5. Элементы языка SQL
В данной главе рассматриваются элементы языка SQL (Structured Query Language). Текущая версия стандарта языка SQL принята в 1992 г. (Официальное название стандарта - Международный стандарт языка баз данных SQL (1992) (International Standart Database Language SQL), неофициальное название - SQL/92, или SQL-92, или SQL2). Документ, описывающий стандарт, содержит более 600 страниц. Мы дадим только некоторые понятия языка.
Язык SQL стал фактически стандартным языком доступа к базам данных. Все СУБД, претендующие на название "реляционные", реализуют тот или иной диалект SQL. Многие нереляционные системы также имеют в настоящее время средства доступа к реляционным данным. Целью стандартизации является переносимость приложений между различными СУБД.
Нужно заметить, что в настоящее время, ни одна система не реализует стандарт SQL в полном объеме. Кроме того, во всех диалектах языка имеются возможности, не являющиеся стандартными. Таким образом, можно сказать, что каждый диалект - это надмножество некоторого подмножества стандарта SQL. Это затрудняет переносимость приложений, разработанных для одних СУБД в другие СУБД.
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например, вместо "отношений" используются "таблицы", вместо "кортежей" - "строки", вместо "атрибутов" - "колонки" или "столбцы".
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее. Например, отношение в реляционной модели данных не допускает наличия одинаковых кортежей, а таблицы в терминологии SQL могут иметь одинаковые строки. Имеются и другие отличия.
Язык SQL является реляционно полным. Это означает, что любой оператор реляционной алгебры может быть выражен подходящим оператором SQL.
Нормальные формы отношений
Глава 6. Нормальные формы отношений
Нормальные формы более высоких порядков
Глава 7. Нормальные формы более высоких порядков
Элементы модели "сущностьсвязь"
Глава 8. Элементы модели "сущность-связь"
Моделирование структуры базы данных при помощи алгоритма нормализации, описанного в предыдущих главах, имеет серьезные недостатки: Первоначальное размещение всех атрибутов в одном отношении является очень неестественной операцией. Интуитивно разработчик сразу проектирует несколько отношений в соответствии с обнаруженными сущностями. Даже если совершить насилие над собой и создать одно или несколько отношений, включив в них все предполагаемые атрибуты, то совершенно неясен смысл полученного отношения. Невозможно сразу определить полный список атрибутов. Пользователи имеют привычку называть разными именами одни и те же вещи или наоборот, называть одними именами разные вещи. Для проведения процедуры нормализации необходимо выделить зависимости атрибутов, что тоже очень нелегко, т.к. необходимо явно выписать все зависимости, даже те, которые являются очевидными.
В реальном проектировании структуры базы данных применяются другой метод - так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship).
Первый вариант модели сущность-связь был предложен в 1976 г. Питером Пин-Шэн Ченом [37]. В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). Кроме того, различные программные средства, реализующие одну и ту же нотацию, могут отличаться своими возможностями. По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
Мы опишем работу с ER-диаграммами близко к нотации Баркера, как довольно легкой в понимании основных идей. Данная глава является скорее иллюстрацией методов семантического моделирования, чем полноценным введением в эту область.
Транзакции и целостность баз данных
Глава 9. Транзакции и целостность баз данных
В данной и в последующих главах изучается фундаментальное понятие транзакции. Это понятие не входит в реляционную модель данных, т.к. транзакции рассматриваются не только в реляционных СУБД, но и в СУБД других типов, а также и в других типах информационных систем.
Транзакция - это неделимая, с точки зрения воздействия на СУБД, последовательность операций манипулирования данными. Для пользователя транзакция выполняется по принципу "все или ничего", т.е. либо транзакция выполняется целиком и переводит базу данных из одного целостного состояния в другое целостное состояние, либо, если по каким-либо причинам, одно из действий транзакции невыполнимо, или произошло какое-либо нарушение работы системы, база данных возвращается в исходное состояние, которое было до начала транзакции (происходит откат транзакции). С этой точки зрения, транзакции важны как в многопользовательских, так и в однопользовательских системах. В однопользовательских системах транзакции - это логические единицы работы, после выполнения которых база данных остается в целостном состоянии. Транзакции также являются единицами восстановления данных после сбоев - восстанавливаясь, система ликвидирует следы транзакций, не успевших успешно завершиться в результате программного или аппаратного сбоя. Эти два свойства транзакций определяют атомарность (неделимость) транзакции. В многопользовательских системах, кроме того, транзакции служат для обеспечения изолированной работы отдельных пользователей - пользователям, одновременно работающим с одной базой данных, кажется, что они работают как бы в однопользовательской системе и не мешают друг другу.
Транзакции и параллелизм
Глава 10. Транзакции и параллелизм
В данной главе изучаются возможности параллельного выполнения транзакций несколькими пользователями, т.е. свойство (И) - изолированность транзакций.
Современные СУБД являются многопользовательскими системами, т.е. допускают параллельную одновременную работу большого количества пользователей. При этом пользователи не должны мешать друг другу. Т.к. логической единицей работы для пользователя является транзакция, то работа СУБД должна быть организована так, чтобы у пользователя складывалось впечатление, что их транзакции выполняются независимо от транзакций других пользователей.
Простейший и очевидный способ обеспечить такую иллюзию у пользователя состоит в том, чтобы все поступающие транзакции выстраивать в единую очередь и выполнять строго по очереди. Такой способ не годится по очевидным причинам - теряется преимущество параллельной работы. Таким образом, транзакции необходимо выполнять одновременно, но так, чтобы результат был бы такой же, как если бы транзакции выполнялись по очереди. Трудность состоит в том, что если не предпринимать никаких специальных мер, то данные измененные одним пользователем могут быть изменены транзакцией другого пользователя раньше, чем закончится транзакция первого пользователя. В результате, в конце транзакции первый пользователь увидит не результаты своей работы, а неизвестно что.
Одним из способов (не единственным) обеспечить независимую параллельную работу нескольких транзакций является метод блокировок.
Транзакции и восстановление данных
Глава 11. Транзакции и восстановление данных
В данной главе изучаются возможности восстановления данных после сбоев системы, т.е. свойство (Д) - долговечность транзакций.
Главное требование долговечности данных транзакций состоит в том, что данные зафиксированных транзакций должны сохраняться в системе, даже если в следующий момент произойдет сбой системы. Казалось бы, самый простой способ обеспечить такую гарантию - это во время каждой операции сразу записывать все изменения на дисковые носители. Такой способ не является удовлетворительным, т.к. имеется существенное различие в скорости работы с оперативной и с внешней памятью. Единственный способ достичь приемлемой скорости работы состоит в буферизации страниц базы данных в оперативной памяти. Это означает, что данные попадают во внешнюю долговременную память не сразу после внесения изменений, а через некоторое (достаточно большое) время. Тем не менее, что-что во внешней памяти должно оставаться, т.к. иначе неоткуда получить информацию для восстановления.
Требование атомарности транзакций утверждает, что не законченные или откатившиеся транзакции не должны оставлять следов в базе данных. Это означает, что данные должны храниться в базе данных с избыточностью, позволяющей иметь информацию, по которой восстанавливается состояние базы данных на момент начала неудачной транзакции. Такую избыточность обычно обеспечивает журнал транзакций. Журнал транзакций содержит детали всех операций модификации данных в базе данных, в частности, старое и новое значение модифицированного объекта, системный номер транзакции, модифицировавшей объект и другая информация.
Индивидуальный откат транзакции
Индивидуальный откат транзакции
Для того чтобы можно было выполнить по журналу транзакций индивидуальный откат транзакции, все записи в журнале от данной транзакции связываются в обратный список. Началом списка для не закончившихся транзакций является запись о последнем изменении базы данных, произведенном данной транзакцией. Для закончившихся транзакций (индивидуальные откаты которых уже невозможны) началом списка является запись о конце транзакции, которая обязательно вытолкнута во внешнюю память журнала. Концом списка всегда служит первая запись об изменении базы данных, произведенном данной транзакцией. В каждой записи имеется уникальный системный номер транзакции, чтобы можно было восстановить прямой список записей об изменениях базы данных данной транзакцией.
Индивидуальный откат транзакции выполняется следующим образом: Просматривается список записей, сделанных данной транзакцией в журнале транзакций (от последнего изменения к первому изменению). Выбирается очередная запись из списка данной транзакции. Выполняется противоположная по смыслу операция: вместо операции INSERT выполняется соответствующая операция DELETE, вместо операции DELETE выполняется INSERT, и вместо прямой операции UPDATE обратная операция UPDATE, восстанавливающая предыдущее состояние объекта базы данных. Любая из этих обратных операций также журнализируются. Это необходимо делать, потому что во время выполнения индивидуального отката может произойти мягкий сбой, при восстановлении после которого потребуется откатить такую транзакцию, для которой не полностью выполнен индивидуальный откат. При успешном завершении отката в журнал заносится запись о конце транзакции.
INSERT вставка строк в таблицу
INSERT - вставка строк в таблицу
Пример 1. Вставка одной строки в таблицу: INSERT INTO P (PNUM, PNAME) VALUES (4, "Иванов");
Пример 2. Вставка в таблицу нескольких строк, выбранных из другой таблицы (в таблицу TMP_TABLE вставляются данные о поставщиках из таблицы P, имеющие номера, большие 2): INSERT INTO TMP_TABLE (PNUM, PNAME) SELECT PNUM, PNAME FROM P WHERE P.PNUM>2;
Использование агрегатных функций с группировками
Использование агрегатных функций с группировками
Пример 23. Для каждой детали получить суммарное поставляемое количество (ключевое слово GROUP BY-): SELECT PD.DNUM, SUM(PD.VOLUME) AS SM GROUP BY PD.DNUM;
Этот запрос будет выполняться следующим образом. Сначала строки исходной таблицы будут сгруппированы так, чтобы в каждую группу попали строки с одинаковыми значениями DNUM. Потом внутри каждой группы будет просуммировано поле VOLUME. От каждой группы в результатирующую таблицу будет включена одна строка:
Использование агрегатных функций в запросах
Использование агрегатных функций в запросах
Пример 21. Получить общее количество поставщиков (ключевое слово COUNT): SELECT COUNT(*) AS N FROM P;
В результате получим таблицу с одним столбцом и одной строкой, содержащей количество строк из таблицы P:
Использование имен корреляции (алиасов псевдонимов)
Использование имен корреляции (алиасов, псевдонимов)
Иногда приходится выполнять запросы, в которых таблица соединяется сама с собой, или одна таблица соединяется дважды с другой таблицей. При этом используются имена корреляции (алиасы, псевдонимы), которые позволяют различать соединяемые копии таблиц. Имена корреляции вводятся в разделе FROM и идут через пробел после имени таблицы. Имена корреляции должны использоваться в качестве префикса перед именем столбца и отделяются от имени столбца точкой. Если в запросе указываются одни и те же поля из разных экземпляров одной таблицы, они должны быть переименованы для устранения неоднозначности в именованиях колонок результатирующей таблицы. Определение имени корреляции действует только во время выполнения запроса.
Пример 19. Отобрать все пары поставщиков таким образом, чтобы первый поставщик в паре имел статус, больший статуса второго поставщика: SELECT P1.PNAME AS PNAME1, P1.PSTATUS AS PSTATUS1, P2.PNAME AS PNAME2, P2.PSTATUS AS PSTATUS2 FROM P P1, P P2 WHERE P1.PSTATUS1 > P2.PSTATUS2;
В результате получим следующую таблицу:
Использование объединения пересечения и разности
Использование объединения, пересечения и разности
Пример 30. Получить имена поставщиков, имеющих статус, больший 3 или поставляющих хотя бы одну деталь номер 2 (объединение двух подзапросов - ключевое слово UNION): SELECT P.PNAME FROM P WHERE P.STATUS > 3 UNION SELECT P.PNAME FROM P, PD WHERE P.PNUM = PD.PNUM AND PD.DNUM = 2;
Замечание. Результатирующие таблицы объединяемых запросов должны быть совместимы, т.е. иметь одинаковое количество столбцов и одинаковые типы столбцов в порядке их перечисления. Не требуется, чтобы объединяемые таблицы имели бы одинаковые имена колонок. Это отличает операцию объединения запросов в SQL от операции объединения в реляционной алгебре. Наименования колонок в результатирующем запросе будут автоматически взяты из результата первого запроса в объединении.
Пример 31. Получить имена поставщиков, имеющих статус, больший 3 и одновременно поставляющих хотя бы одну деталь номер 2 (пересечение двух подзапросов - ключевое слово INTERSECT): SELECT P.PNAME FROM P WHERE P.STATUS > 3 INTERSECT SELECT P.PNAME FROM P, PD WHERE P.PNUM = PD.PNUM AND PD.DNUM = 2;
Пример 32. Получить имена поставщиков, имеющих статус, больший 3, за исключением тех, кто поставляет хотя бы одну деталь номер 2 (разность двух подзапросов - ключевое слово EXCEPT): SELECT P.PNAME FROM P WHERE P.STATUS > 3 EXCEPT SELECT P.PNAME FROM P, PD WHERE P.PNUM = PD.PNUM AND PD.DNUM = 2;
Использование подзапросов
Использование подзапросов
Очень удобным средством, позволяющим формулировать запросы более понятным образом, является возможность использования подзапросов, вложенных в основной запрос.
Пример 25. Получить список поставщиков, статус которых меньше максимального статуса в таблице поставщиков (сравнение с подзапросом): SELECT * FROM P WHERE P.STATYS < (SELECT MAX(P.STATUS) FROM P);
Замечание. Т.к. поле P.STATUS сравнивается с результатом подзапроса, то подзапрос должен быть сформулирован так, чтобы возвращать таблицу, состоящую ровно из одной строки и одной колонки.
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: Выполнить один раз вложенный подзапрос и получить максимальное значение статуса. Просканировать таблицу поставщиков P, каждый раз сравнивая значение статуса поставщика с результатом подзапроса, и отобрать только те строки, в которых статус меньше максимального.
Пример 26. Использование предиката IN. Получить список поставщиков, поставляющих деталь номер 2: SELECT * FROM P WHERE P.PNUM IN (SELECT DISTINCT PD.PNUM FROM PD WHERE PD.DNUM = 2);
Замечание. В данном случае вложенный подзапрос может возвращать таблицу, содержащую несколько строк.
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: Выполнить один раз вложенный подзапрос и получить список номеров поставщиков, поставляющих деталь номер 2. Просканировать таблицу поставщиков P, каждый раз проверяя, содержится ли номер поставщика в результате подзапроса.
Пример 27. Использование предиката EXIST. Получить список поставщиков, поставляющих деталь номер 2: SELECT * FROM P WHERE EXIST (SELECT * FROM PD WHERE PD.PNUM = P.PNUM AND PD.DNUM = 2);
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: Просканировать таблицу поставщиков P, каждый раз выполняя подзапрос с новым значением номера поставщика, взятым из таблицы P. В результат запроса включить только те строки из таблицы поставщиков, для которых вложенный подзапрос вернул непустое множество строк.
Замечание. В отличие от двух предыдущих примеров, вложенный подзапрос содержит параметр (внешнюю ссылку), передаваемый из основного запроса - номер поставщика P.PNUM. Такие подзапросы называются коррелируемыми (correlated). Внешняя ссылка может принимать различные значения для каждой строки-кандидата, оцениваемого с помощью подзапроса, поэтому подзапрос должен выполняться заново для каждой строки, отбираемой в основном запросе. Такие подзапросы характерны для предиката EXIST, но могут быть использованы и в других подзапросах.
Замечание. Может показаться, что запросы, содержащие коррелируемые подзапросы будут выполняться медленнее, чем запросы с некоррелируемыми подзапросами. На самом деле это не так, т.к. то, как пользователь, сформулировал запрос, не определяет, как этот запрос будет выполняться. Язык SQL является непроцедурным, а декларативным. Это значит, что пользователь, формулирующий запрос, просто описывает, каким должен быть результат запроса, а как этот результат будет получен - за это отвечает сама СУБД.
Пример 28. Использование предиката NOT EXIST. Получить список поставщиков, не поставляющих деталь номер 2: SELECT * FROM P WHERE NOT EXIST (SELECT * FROM PD WHERE PD.PNUM = P.PNUM AND PD.DNUM = 2);
Замечание. Также как и в предыдущем примере, здесь используется коррелируемый подзапрос. Отличие в том, что в основном запросе будут отобраны те строки из таблицы поставщиков, для которых вложенный подзапрос не выдаст ни одной строки.
Пример 29. Получить имена поставщиков, поставляющих все детали: SELECT DISTINCT PNAME FROM P WHERE NOT EXIST (SELECT * FROM D WHERE NOT EXIST (SELECT * FROM PD WHERE PD.DNUM = D.DNUM AND PD.PNUM = P.PNUM));
Замечание. Данный запрос содержит два вложенных подзапроса и реализует реляционную операцию деления отношений.
Самый внутренний подзапрос параметризован двумя параметрами (D.DNUM, P.PNUM) и имеет следующий смысл: отобрать все строки, содержащие данные о поставках поставщика с номером PNUM детали с номером DNUM. Отрицание NOT EXIST говорит о том, что данный поставщик не поставляет данную деталь. Внешний к нему подзапрос, сам являющийся вложенным и параметризованным параметром P.PNUM, имеет смысл: отобрать список деталей, которые не поставляются поставщиком PNUM. Отрицание NOT EXIST говорит о том, что для поставщика с номером PNUM не должно быть деталей, которые не поставлялись бы этим поставщиком. Это в точности означает, что во внешнем запросе отбираются только поставщики, поставляющие все детали.
Эквисоединение
Экви-соединение
Наиболее важным частным случаем

Синтаксис экви-соединения:

Пример 9. Пусть имеются отношения



Этапы разработки базы данных
Этапы разработки базы данных
Целью разработки любой базы данных является хранение и использование информации о какой-либо предметной области. Для реализации этой цели имеются следующие инструменты: Реляционная модель данных - удобный способ представления данных предметной области. Язык SQL - универсальный способ манипулирования такими данными.
Однако очевидно, что для одной и той же предметной области реляционные отношения можно спроектировать множеством различных способов. Например, можно спроектировать несколько отношений с большим количеством атрибутов, или наоборот, разнести все атрибуты по большому числу мелких отношений. Как определить, по каким признакам нужно помещать атрибуты в те или иные отношения?
В данной главе рассматриваются способы "хорошего" или "правильного" проектирования реляционных отношений. Сначала мы обсудим, что значит "хорошие" или "правильные" модели данных. Потом будут введены понятия первой, второй и третьей нормальных форм отношений (1НФ, 2НФ, 3НФ) и показано, что "хорошими" являются отношения в третьей нормальной форме.
При разработке базы данных обычно выделяется несколько уровней моделирования, при помощи которых происходит переход от предметной области к конкретной реализации базы данных средствами конкретной СУБД. Можно выделить следующие уровни: Сама предметная область Модель предметной области Логическая модель данных Физическая модель данных Собственно база данных и приложения
Предметная область - это часть реального мира, данные о которой мы хотим отразить в базе данных. Например, в качестве предметной области можно выбрать бухгалтерию какого-либо предприятия, отдел кадров, банк, магазин и т.д. Предметная область бесконечна и содержит как существенно важные понятия и данные, так и малозначащие или вообще не значащие данные. Так, если в качестве предметной области выбрать учет товаров на складе, то понятия "накладная" и "счет-фактура" являются существенно важными понятиями, а то, что сотрудница, принимающая накладные, имеет двоих детей - это для учета товаров неважно. Однако, с точки зрения отдела кадров данные о наличии детей являются существенно важными. Таким образом, важность данных зависит от выбора предметной области.
Модель предметной области. Модель предметной области - это наши знания о предметной области. Знания могут быть как в виде неформальных знаний в мозгу эксперта, так и выражены формально при помощи каких-либо средств. В качестве таких средств могут выступать текстовые описания предметной области, наборы должностных инструкций, правила ведения дел в компании и т.п. Опыт показывает, что текстовый способ представления модели предметной области крайне неэффективен. Гораздо более информативными и полезными при разработке баз данных являются описания предметной области, выполненные при помощи специализированных графических нотаций. Имеется большое количество методик описания предметной области. Из наиболее известных можно назвать методику структурного анализа SADT и основанную на нем IDEF0, диаграммы потоков данных Гейна-Сарсона, методику объектно-ориентированного анализа UML, и др. Модель предметной области описывает скорее процессы, происходящие в предметной области и данные, используемые этими процессами. От того, насколько правильно смоделирована предметная область, зависит успех дальнейшей разработки приложений.
Логическая модель данных. На следующем, более низком уровне находится логическая модель данных предметной области. Логическая модель описывает понятия предметной области, их взаимосвязь, а также ограничения на данные, налагаемые предметной областью. Примеры понятий - "сотрудник", "отдел", "проект", "зарплата". Примеры взаимосвязей между понятиями - "сотрудник числится ровно в одном отделе", "сотрудник может выполнять несколько проектов", "над одним проектом может работать несколько сотрудников". Примеры ограничений - "возраст сотрудника не менее 16 и не более 60 лет".
Логическая модель данных является начальным прототипом будущей базы данных. Логическая модель строится в терминах информационных единиц, но без привязки к конкретной СУБД. Более того, логическая модель данных необязательно должна быть выражена средствами именно реляционной модели данных. Основным средством разработки логической модели данных в настоящий момент являются различные варианты ER-диаграмм (Entity-Relationship, диаграммы сущность-связь). Одну и ту же ER-модель можно преобразовать как в реляционную модель данных, так и в модель данных для иерархических и сетевых СУБД, или в постреляционную модель данных. Однако, т.к. мы рассматриваем именно реляционные СУБД, то можно считать, что логическая модель данных для нас формулируется в терминах реляционной модели данных.
Решения, принятые на предыдущем уровне, при разработке модели предметной области, определяют некоторые границы, в пределах которых можно развивать логическую модель данных, в пределах же этих границ можно принимать различные решения. Например, модель предметной области складского учета содержит понятия "склад", "накладная", "товар". При разработке соответствующей реляционной модели эти термины обязательно должны быть использованы, но различных способов реализации тут много - можно создать одно отношение, в котором будут присутствовать в качестве атрибутов "склад", "накладная", "товар", а можно создать три отдельных отношения, по одному на каждое понятие.
При разработке логической модели данных возникают вопросы: хорошо ли спроектированы отношения? Правильно ли они отражают модель предметной области, а следовательно и саму предметную область?
Физическая модель данных. На еще более низком уровне находится физическая модель данных. Физическая модель данных описывает данные средствами конкретной СУБД. Мы будем считать, что физическая модель данных реализована средствами именно реляционной СУБД, хотя, как уже сказано выше, это необязательно. Отношения, разработанные на стадии формирования логической модели данных, преобразуются в таблицы, атрибуты становятся столбцами таблиц, для ключевых атрибутов создаются уникальные индексы, домены преображаются в типы данных, принятые в конкретной СУБД.
Ограничения, имеющиеся в логической модели данных, реализуются различными средствами СУБД, например, при помощи индексов, декларативных ограничений целостности, триггеров, хранимых процедур. При этом опять-таки решения, принятые на уровне логического моделирования определяют некоторые границы, в пределах которых можно развивать физическую модель данных. Точно также, в пределах этих границ можно принимать различные решения. Например, отношения, содержащиеся в логической модели данных, должны быть преобразованы в таблицы, но для каждой таблицы можно дополнительно объявить различные индексы, повышающие скорость обращения к данным. Многое тут зависит от конкретной СУБД.
При разработке физической модели данных возникают вопросы: хорошо ли спроектированы таблицы? Правильно ли выбраны индексы? Насколько много программного кода в виде триггеров и хранимых процедур необходимо разработать для поддержания целостности данных?
Собственно база данных и приложения. И, наконец, как результат предыдущих этапов появляется собственно сама база данных. База данных реализована на конкретной программно-аппаратной основе, и выбор этой основы позволяет существенно повысить скорость работы с базой данных. Например, можно выбирать различные типы компьютеров, менять количество процессоров, объем оперативной памяти, дисковые подсистемы и т.п. Очень большое значение имеет также настройка СУБД в пределах выбранной программно-аппаратной платформы.
Но опять решения, принятые на предыдущем уровне - уровне физического проектирования, определяют границы, в пределах которых можно принимать решения по выбору программно-аппаратной платформы и настройки СУБД.
Таким образом ясно, что решения, принятые на каждом этапе моделирования и разработки базы данных, будут сказываться на дальнейших этапах. Поэтому особую роль играет принятие правильных решений на ранних этапах моделирования.
Как на самом деле выполняется оператор SELECT
Как на самом деле выполняется оператор SELECT
Если внимательно рассмотреть приведенный выше концептуальный алгоритм вычисления результата оператора SELECT, то сразу понятно, что выполнять его непосредственно в таком виде чрезвычайно накладно. Даже на самом первом шаге, когда вычисляется декартово произведение таблиц, приведенных в разделе FROM, может получиться таблица огромных размеров, причем практически большинство строк и колонок из нее будет отброшено на следующих шагах.
На самом деле в РСУБД имеется оптимизатор, функцией которого является нахождение такого оптимального алгоритма выполнения запроса, который гарантирует получение правильного результата.
Схематично работу оптимизатора можно представить в виде последовательности нескольких шагов:
Шаг 1 (Синтаксический анализ). Поступивший запрос подвергается синтаксическому анализу. На этом шаге определяется, правильно ли вообще (с точки зрения синтаксиса SQL) сформулирован запрос. В ходе синтаксического анализа вырабатывается некоторое внутренне представление запроса, используемое на последующих шагах.
Шаг 2 (Преобразование в каноническую форму). Запрос во внутреннем представлении подвергается преобразованию в некоторую каноническую форму. При преобразовании к канонической форме используются как синтаксические, так и семантические преобразования. Синтаксические преобразования (например, приведения логических выражений к конъюнктивной или дизъюнктивной нормальной форме, замена выражений "x AND NOT x" на "FALSE", и т.п.) позволяют получить новое внутренне представление запроса, синтаксически эквивалентное исходному, но стандартное в некотором смысле. Семантические преобразования используют дополнительные знания, которыми владеет система, например, ограничения целостности. В результате семантических преобразований получается запрос, синтаксически не эквивалентный исходному, но дающий тот же самый результат.
Шаг 3 (Генерация планов выполнения запроса и выбор оптимального плана). На этом шаге оптимизатор генерирует множество возможных планов выполнения запроса. Каждый план строится как комбинация низкоуровневых процедур доступа к данным из таблиц, методам соединения таблиц. Из всех сгенерированных планов выбирается план, обладающий минимальной стоимостью. При этом анализируются данные о наличии индексов у таблиц, статистических данных о распределении значений в таблицах, и т.п. Стоимость плана это, как правило, сумма стоимостей выполнения отдельных низкоуровневых процедур, которые используются для его выполнения. В стоимость выполнения отдельной процедуры могут входить оценки количества обращений к дискам, степень загруженности процессора и другие параметры.
Шаг 4. (Выполнение плана запроса). На этом шаге план, выбранный на предыдущем шаге, передается на реальное выполнение.
Во многом качество конкретной СУБД определяется качеством ее оптимизатора. Хороший оптимизатор может повысить скорость выполнения запроса на несколько порядков. Качество оптимизатора определяется тем, какие методы преобразований он может использовать, какой статистической и иной информацией о таблицах он располагает, какие методы для оценки стоимости выполнения плана он знает.
Классификация ограничений целостности
Классификация ограничений целостности
Ограничения целостности можно классифицировать несколькими способами: По способам реализации. По времени проверки. По области действия.
Классификация ограничений целостности по способам реализации
Классификация ограничений целостности по способам реализации
Каждая система обладает своими средствами поддержки ограничений целостности. Различают два способа реализации: Декларативная поддержка ограничений целостности. Процедурная поддержка ограничений целостности.
Определение 4. Декларативная поддержка ограничений целостности заключается в определении ограничений средствами языка определения данных (DDL - Data Definition Language). Обычно средства декларативной поддержки целостности (если они имеются в СУБД) определяют ограничения на значения доменов и атрибутов, целостность сущностей (потенциальные ключи отношений) и ссылочную целостность (целостность внешних ключей). Декларативные ограничения целостности можно использовать при создании и модификации таблиц средствами языка DDL или в виде отдельных утверждений (ASSERTION).
Например, следующий оператор создает таблицу PERSON и определяет для нее некоторые ограничения целостности: CREATE TABLE PERSON (Pers_Id INTEGER PRIMARY KEY, Pers_Name CHAR(30) NOT NULL, Dept_Id REFERENCES DEPART(Dept_Id) ON UPDATE CASCADE ON DELETE CASCADE);
После выполнения оператора для таблицы PERSON будут объявлены следующие ограничения целостности: Поле Pers_Id образует потенциальный ключ отношения. Поле Pers_Name не может содержать null-значений. Поле Dept_Id является внешней ссылкой на родительскую таблицу DEPART, причем, при изменении или удалении строки в родительской таблице каскадно должны быть внесены соответствующие изменения в дочернюю таблицу.
Средства декларативной поддержки ограничений описаны в стандарте SQL и более подробно рассматриваются ниже.
Определение 5. Процедурная поддержка ограничений целостности заключается в использовании триггеров и хранимых процедур.
Не все ограничения целостности можно реализовать декларативно. Примером такого ограничения может служить требование из примера 1, утверждающее, что поле Dept_Kol таблицы DEPART должно содержать количество сотрудников, реально числящихся в подразделении. Для реализации этого ограничения необходимо создать триггер, запускающийся при вставке, модификации и удалении записей в таблице PERSON, который корректно изменяет значение поля Dept_Kol. Например, при вставке в таблицу PERSON новой строки, триггер увеличивает на единицу значение поля Dept_Kol, а при удалении строки - уменьшает. Заметим, что при модификации записей в таблице PERSON могут потребоваться даже более сложные действия. Действительно, модификация записи в таблице PERSON может заключаться в том, что мы переводим сотрудника из одного отдела в другой, меняя значение в поле Dept_Id. При этом необходимо в старом подразделении уменьшить количество сотрудников, а в новом - увеличить.
Кроме того, необходимо защититься от неправильной модификации строк таблицы DEPART. Действительно, пользователь может попытаться модифицировать запись об отделе, введя неверное значение поля Dept_Kol. Для предотвращения подобных действий необходимо создать также триггеры, запускающиеся при вставке и модификации записей в таблице DEPART. Триггер, запускающийся при удалении записей из таблицы DEPART не нужен, т.к. уже имеется ограничение ссылочной целостности, каскадно удаляющее записи из таблицы PERSON при удалении записи из таблицы DEPART.
По сути, наличие ограничения целостности (как декларативного, так и процедурного характера) всегда приводит к созданию или использованию некоторого программного кода, реализующего это ограничение. Разница заключается в том, где такой код хранится и как он создается.
Если ограничение целостности реализовано в виде триггеров, то этот программный код является просто телом триггера. Если используется декларативное ограничение целостности, то возможны два подхода: При декларировании (объявлении) ограничения текст ограничения хранится в виде некоторого объекта СУБД, а для реализации ограничения используются встроенные в СУБД функции, и тогда этот код представляет собой внутренние функции ядра СУБД. При декларировании ограничения СУБД автоматически генерирует триггеры, выполняющие необходимые действия по проверке ограничений.
Примером использования функций ядра для проверки декларативных ограничений является автоматическая проверка уникальности индексов, соответствующих потенциальным ключам отношений. В качестве другого примера можно привести поддержку ссылочной целостности средствами СУБД ORACLE. Ограничение ссылочной целостности является в ORACLE объектом базы данных, хранящим формулировку этого ограничения. Проверка ограничения выполняется функциями ядра ORACLE со ссылкой на этот объект. Ограничение целостности в этом случае нельзя модифицировать иначе, как используя декларативные операторы создания и модификации ограничений.
Примером генерации новых триггеров для реализации декларативных ограничений, может служить система Visual FoxPro. Триггеры, автоматически сгенерированные Visual FoxPro при объявлении ограничений ссылочной целостности можно посмотреть и даже внести в них изменения, так чтобы они могли выполнять некоторые дополнительные действия.
Если система не поддерживает ни декларативную поддержку ссылочной целостности, ни триггеры (как, например, FoxPro 2.5), то программный код, следящий за корректностью базы данных, приходится размещать в пользовательском приложении (такой ведь код все равно необходим!). Это сильно затрудняет разработку программ и не защищает от попыток пользователей напрямую внести некорректные данные в базу данных. Особенно сложно становится в том случае, когда имеется сложная база данных и множество различных приложений, работающих с ней (например, к базе данных торгового предприятия может обращаться несколько приложений, таких как "Складской учет", "Прием заказов", "Главный бухгалтер" и т.п.). Каждое из таких приложений должно содержать один и тот же код, отвечающий за поддержание целостности базы данных. Особенно весело становится разработчику, когда необходимо внести изменения в логику поддержания целостности. Приходится заменять во всех программах одни и те же места, перекомпилировать все приложения и распространять по рабочим местам новые версии.
Классификация ограничений целостности по области действия
Классификация ограничений целостности по области действия
По области действия ограничения делятся на: Ограничения домена Ограничения атрибута Ограничения кортежа Ограничения отношения Ограничения базы данных
Классификация ограничений целостности по времени проверки
Классификация ограничений целостности по времени проверки
По времени проверки ограничения делятся на: Немедленно проверяемые ограничения. Ограничения с отложенной проверкой.
Определение 6. Немедленно проверяемые ограничения проверяются непосредственно в момент выполнения операции, могущей нарушить ограничение. Например, проверка уникальности потенциального ключа проверяется в момент вставки записи в таблицу. Если ограничение нарушается, то такая операция отвергается. Транзакция, внутри которой произошло нарушение немедленно проверяемого утверждения целостности, обычно откатывается.
Определение 7. Ограничения с отложенной проверкой проверяется в момент фиксации транзакции оператором COMMIT WORK. Внутри транзакции ограничение может не выполняться. Если в момент фиксации транзакции обнаруживается нарушение ограничения с отложенной проверкой, то транзакция откатывается. Примером ограничения, которое не может быть проверено немедленно является ограничение из примера 1. Это происходит оттого, что транзакция, заключающаяся во вставке нового сотрудника в таблицу PERSON, состоит не менее чем из двух операций - вставки строки в таблицу PERSON и обновления строки в таблице DEPART. Ограничение, безусловно, неверно после первой операции и становится верным после второй операции.
Концептуальные и физические ERмодели
Концептуальные и физические ER-модели
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы. Это означает, что диаграмма не учитывает особенности конкретной СУБД. По данной концептуальной диаграмме можно построить физическую диаграмму, которая уже будут учитываться такие особенности СУБД, как допустимые типы и наименования полей и таблиц, ограничения целостности и т.п. Физический вариант диаграммы, приведенной на Рис. 9 может выглядеть, например, следующим образом:

Рис. 10
На данной диаграмме каждая сущность представляет собой таблицу базы данных, каждый атрибут становится колонкой соответствующей таблицы. Обращаем внимание на то, что во многих таблицах, например, "CUST_DETAIL" и "PROD_IN_SKLAD", соответствующих сущностям "Запись списка накладной" и "Товар на складе", появились новые атрибуты, которых не было в концептуальной модели - это ключевые атрибуты родительских таблиц, мигрировавших в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
Легко заметить, что полученные таблицы сразу находятся в 3НФ.
Конфликты между транзакциями
Конфликты между транзакциями
Итак, анализ проблем параллелизма показывает, что если не предпринимать специальных мер, то при работе в смеси нарушается свойство (И) транзакций - изолированность. Транзакции реально мешают друг другу получать правильные результаты.
Однако не всякие транзакции мешают друг другу. Очевидно, что транзакции не мешают друг другу, если они обращаются к разным данным или выполняются в разное время.
Определение 3. Транзакции называются конкурирующими, если они пересекаются по времени и обращаются к одним и тем же данным.
В результате конкуренции за данными между транзакциями возникают конфликты доступа к данным. Различают следующие виды конфликтов: W-W (Запись - Запись). Первая транзакция изменила объект и не закончилась. Вторая транзакция пытается изменить этот объект. Результат - потеря обновления. R-W (Чтение - Запись). Первая транзакция прочитала объект и не закончилась. Вторая транзакция пытается изменить этот объект. Результат - несовместимый анализ (неповторяемое считывание). W-R (Запись - Чтение). Первая транзакция изменила объект и не закончилась. Вторая транзакция пытается прочитать этот объект. Результат - чтение "грязных" данных.
Конфликты типа R-R (Чтение - Чтение) отсутствуют, т.к. данные при чтении не изменяются.
Другие проблемы параллелизма (фантомы и собственно несовместимый анализ) являются более сложными, т.к. принципиальное отличие их в том, что они не могут возникать при работе с одним объектом. Для возникновения этих проблем требуется, чтобы транзакции работали с целыми наборами данных.
Определение 4. График запуска набора транзакций называется последовательным, если транзакции выполняются строго по очереди, т.е. элементарные операции транзакций не чередуются друг с другом.
Определение 5. Если график запуска набора транзакций содержит чередующиеся элементарные операции транзакций, то такой график называется чередующимся.
При выполнении последовательного графика гарантируется, что транзакции выполняются правильно, т.е. при последовательном графике транзакции не "чувствуют" присутствия друг друга.
Определение 6. Два графика называются эквивалентными, если при их выполнении будет получен один и тот же результат, независимо от начального состояния базы данных.
Определение 7. График запуска транзакции называется верным (сериализуемым), если он эквивалентен какому-либо последовательному графику.
Замечание. При выполнении двух различных последовательных (а, следовательно, верных) графиков, содержащих один и тот же набор транзакций, могут быть получены различные результаты. Действительно, пусть транзакция A заключается в действии "Сложить X с 1", а транзакция B - "Удвоить X". Тогда последовательный график {A, B} даст результат 2(X+1), а последовательный график {B, A} даст результат 2X+1. Таким образом, может существовать несколько верных графиков запусков транзакций, приводящих к разным результатам при одном и том же начальном состоянии базы данных.
Задача обеспечения изолированной работы пользователей не сводится просто к нахождению правильных (сериальных) графиков запусков транзакций. Если бы этого было достаточно, то лучшим был бы простейший способ сериализации - ставить транзакции в общую очередь по мере их поступления и выполнять строго последовательно. Таким способом автоматически будет получен правильный (сериальный) график. Проблема в том, что этот график будет неоптимальным с точки зрения общей производительности системы. Получается ситуация, в которой борются противоположные силы - с одной стороны, стремление обеспечить сериальность за счет ухудшения общей эффективности работы, с другой стороны, стремление улучшить общую эффективность за счет ухудшения сериальности.
Один крайний случай (выполнение транзакций по очереди) мы рассмотрели. Рассмотрим другой крайний случай - попытаемся достичь оптимального графика - т.е. графика с максимальной эффективностью выполнения транзакций. Для этого сначала нужно уточнить понятие "оптимальность". С каждым возможным графиком запуска транзакций мы можем связать значение некоей стоимостной функции. В качестве стоимостной функции можно взять, например, суммарное время выполнения всех транзакций в наборе. Время выполнения одной транзакции считается от момента, когда транзакция возникла и до момента, когда транзакция выполнила свою последнюю элементарную операцию. Это время складывается из следующих компонентов: Время ожидания начала транзакции - то время, которое проходит от момента, когда транзакция возникла до момента, когда началась реально выполняться ее первая элементарная операция. Сумма времен выполнения элементарных операций транзакции. Сумма времен всех элементарных операций других транзакций, вклинившихся между элементарными операциями транзакции.
Оптимальным будет график, дающий минимум стоимостной функции. Очевидно, оптимальность графика запуска зависит от выбора стоимостной функции, т.е. график, оптимальный с точки зрения одних критериев (например, с точки зрения приведенной функции стоимости) не будет оптимальным с точки зрения других критериев (например, с точки зрения достижения максимально быстрого начала выполнения каждой транзакции).
Рассмотрим следующую гипотетическую ситуацию. Предположим, что нам заранее на некоторый промежуток времени наперед известно, какие транзакции в какие моменты поступят, т.е. заранее известна вся будущая смесь транзакций и моменты поступления каждой транзакции:
Транзакция


Транзакция


-
Транзакция


В этом случае, т.к. набор всех транзакций заранее известен, теоретически можно перебрать все возможные варианты графиков запусков (их конечное число, хотя и очень большое), и выбрать из них те графики, которые, во-первых, правильные, а во-вторых, оптимальны по выбранному критерию. В этом случае оптимальный график запуска транзакций достижим.
В реальной ситуации, однако, неизвестно не только какие транзакции будут поступать в какие моменты времени, но и неизвестна длительность периода времени, охватывающего набор транзакций. Реально, система может непрерывно работать несколько дней или месяцев и в этом случае набором транзакций будет набор всех транзакций за этот период. С другой стороны, прекращение работы сервера может произойти в любой момент либо по команде администратора системы, либо в результате сбоя. Необходимо, следовательно, чтобы система работала так, чтобы к любому моменту времени набор выполненных и выполняющихся в этот момент транзакций был бы правильным и не слишком далек от оптимального.
Т.к. транзакции не мешают друг другу, если они обращаются к разным данным или выполняются в разное время, то имеется два способа разрешить конкуренцию между поступающими в произвольные моменты транзакциями: "Притормаживать" некоторые из поступающих транзакций настолько, насколько это необходимо для обеспечения правильности смеси транзакций в каждый момент времени (т.е. обеспечить, чтобы конкурирующие транзакции выполнялись в разное время). Предоставить конкурирующим транзакциям "разные" экземпляры данных (т.е. обеспечить, чтобы конкурирующие транзакции работали с разными версиями данными).
Первый метод - "притормаживание" транзакций - реализуется путем использованием блокировок различных видов или метода временных меток.
Второй метод - предоставление разных версий данных - реализуется путем использованием данных из журнала транзакций.
Корректность процедуры нормализации декомпозиция без потерь Теорема Хеза
Корректность процедуры нормализации - декомпозиция без потерь. Теорема Хеза
Как было показано выше, алгоритм нормализации состоит в выявлении функциональных зависимостей предметной области и соответствующей декомпозиции отношений. Предположим, что мы уже имеем работающую систему, в которой накоплены данные. Пусть данных корректны в текущий момент, т.е. факты предметной области правильно отражаются текущим состоянием базы данных. Если в предметной области обнаружена новая функциональная зависимость (либо она была пропущена на этапе моделирования предметной области, либо просто изменилась предметная область), то возникает необходимость заново нормализовать данные. При этом некоторые отношения придется декомпозировать в соответствии с алгоритмом нормализации. Возникают естественные вопросы - что произойдет с уже накопленными данными? Не будут ли данные потеряны в ходе декомпозиции? Можно ли вернуться обратно к исходным отношениям, если будет принято решение отказаться от декомпозиции, восстановятся ли при этом данные?
Для ответов на эти вопросы нужно ответить на вопрос - что же представляет собой декомпозиция отношений с точки зрения операций реляционной алгебры? При декомпозиции мы из одного отношения получаем два или более отношений, каждое из которых содержит часть атрибутов исходного отношения. В полученных новых отношениях необходимо удалить дубликаты строк, если таковые возникли. Это в точности означает, что декомпозиция отношения есть не что иное, как взятие одной или нескольких проекций исходного отношения так, чтобы эти проекции в совокупности содержали (возможно, с повторениями) все атрибуты исходного отношения. Т.е., при декомпозиции не должны теряться атрибуты отношений. Но при декомпозиции также не должны потеряться и сами данные. Данные можно считать не потерянными в том случае, если возможна обратная операция - по декомпозированным отношениям можно восстановить исходное отношение в точности в прежнем виде. Операцией, обратной операции проекции, является операция соединения отношений. Имеется большое количество видов операции соединения (см. гл. 4). Т.к. при восстановлении исходного отношения путем соединения проекций не должны появиться новые атрибуты, то необходимо использовать естественное соединение.
Определение 6. Проекция

Определение 7. Собственные проекции



Рассмотрим пример, показывающий, что декомпозиция без потерь происходит не всегда.
Пример 2. Пусть дано отношение
Критерии оценки качества логической модели данных
Критерии оценки качества логической модели данных
Цель данной главы - описать некоторые принципы построения хороших логических моделей данных. Хороших в том смысле, что решения, принятые в процессе логического проектирования приводили бы к хорошим физическим моделям и в конечном итоге к хорошей работе базы данных.
Для того чтобы оценить качество принимаемых решений на уровне логической модели данных, необходимо сформулировать некоторые критерии качества в терминах физической модели и конкретной реализации и посмотреть, как различные решения, принятые в процессе логического моделирования, влияют на качество физической модели и на скорость работы базы данных.
Конечно, таких критериев может быть очень много и выбор их в достаточной степени произволен. Мы рассмотрим некоторые из таких критериев, которые являются безусловно важными с точки зрения получения качественной базы данных: Адекватность базы данных предметной области Легкость разработки и сопровождения базы данных Скорость выполнения операций обновления данных (вставка, обновление, удаление кортежей) Скорость выполнения операций выборки данных
Кросстаблицы
Кросс-таблицы
Одной из задач, связанных с представлением табличных данных является построение так называемых кросс-таблиц.
Пусть имеется отношение с тремя атрибутами и потенциальным ключом, включающим первые два атрибута. Примером такого отношения могут быть данные с объемами продаж различных товаров за некоторые промежутки времени:
Легкость разработки и сопровождения базы данных
Легкость разработки и сопровождения базы данных
Практически любая база данных, за исключением совершенно элементарных, содержит некоторое количество программного кода в виде триггеров и хранимых процедур.
Хранимые процедуры - это процедуры и функции, хранящиеся непосредственно в базе данных в откомпилированном виде и которые могут запускаться пользователями или приложениями, работающими с базой данных. Хранимые процедуры обычно пишутся либо на специальном процедурном расширении языка SQL (например, PL/SQL для ORACLE или Transact-SQL для MS SQL Server), или на некотором универсальном языке программирования, например, C++, с включением в код операторов SQL в соответствии со специальными правилами такого включения. Основное назначение хранимых процедур - реализация бизнес-процессов предметной области.
Триггеры - это хранимые процедуры, связанные с некоторыми событиями, происходящими во время работы базы данных. В качестве таких событий выступают операции вставки, обновления и удаления строк таблиц. Если в базе данных определен некоторый триггер, то он запускается автоматически всегда при возникновении события, с которым этот триггер связан. Очень важным является то, что пользователь не может обойти триггер. Триггер срабатывает независимо от того, кто из пользователей и каким способом инициировал событие, вызвавшее запуск триггера. Таким образом, основное назначение триггеров - автоматическая поддержка целостности базы данных. Триггеры могут быть как достаточно простыми, например, поддерживающими ссылочную целостность, так и довольно сложными, реализующими какие-либо сложные ограничения предметной области или сложные действия, которые должны произойти при наступлении некоторых событий. Например, с операцией вставки нового товара в накладную может быть связан триггер, который выполняет следующие действия - проверяет, есть ли необходимое количество товара, при наличии товара добавляет его в накладную и уменьшает данные о наличии товара на складе, при отсутствии товара формирует заказ на поставку недостающего товара и тут же посылает заказ по электронной почте поставщику.
Очевидно, что чем больше программного кода в виде триггеров и хранимых процедур содержит база данных, тем сложнее ее разработка и дальнейшее сопровождение.
Механизм выделения версий данных
Механизм выделения версий данных
Использование блокировок гарантирует сериальность планов выполнения смеси транзакций за счет общего замедления работы - конфликтующие транзакции ожидают, когда транзакция, первой заблокировавшая некоторый объект, не освободит его. Без блокировок не обойтись, если все транзакции изменяют данные. Но если в смеси транзакций присутствуют как транзакции, изменяющие данные, так и только читающие данные, можно применить альтернативный механизм обеспечения сериальности, свободный от недостатков метода блокировок. Этот метод состоит в том, что транзакциям, читающим данные, предоставляется как бы "своя" версия данных, имевшаяся в момент начала читающей транзакции. При этом транзакция не накладывает блокировок на читаемые данные, и, поэтому, не блокирует другие транзакции, изменяющие данные. Такой механизм называется механизм выделения версий и заключается в использовании журнала транзакций для генерации разных версий данных.
Журнал транзакций предназначен для выполнения операции отката при неуспешном выполнении транзакции или для восстановления данных после сбоя системы. Журнал транзакций содержит старые копии данных, измененных транзакциями.
Кратко суть метода состоит в следующем: Для каждой транзакции (или запроса) запоминается текущий системный номер (SCN - System Current Number). Чем позже начата транзакция, тем больше ее SCN. При записи страниц данных на диск фиксируется SCN транзакции, производящей эту запись. Этот SCN становится текущим системным номером страницы данных. Транзакции, только читающие данные не блокируют ничего в базе данных. Если транзакция A читает страницу данных, то SCN транзакции A сравнивается с SCN читаемой страницы данных. Если SCN страницы данных меньше или равен SCN транзакции A, то транзакция A читает эту страницу. Если SCN страницы данных больше SCN транзакции A, то это означает, что некоторая транзакция B, начавшаяся позже транзакции A, успела изменить или сейчас изменяет данные страницы. В этом случае транзакция A просматривает журнал транзакция назад в поиске первой записи об изменении нужной страницы данных с SCN меньшим, чем SCN транзакции A. Найдя такую запись, транзакция A использует старый вариант данных страницы.
Рассмотрим, как решается проблема несовместного анализа с использованием механизма выделения версий.
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
Метод временных меток
Метод временных меток
Альтернативный метод сериализации транзакций, хорошо работающий в условиях редких конфликтов транзакций и не требующий построения графа ожидания транзакций основан на использовании временных меток.
Основная идея метода состоит в следующем: если транзакция A началась раньше транзакции B, то система обеспечивает такой режим выполнения, как если бы A была целиком выполнена до начала B.
Для этого каждой транзакции T предписывается временная метка t, соответствующая времени начала T. При выполнении операции над объектом r базы данных транзакция T помечает его своей временной меткой и типом операции (чтение или изменение).
Перед выполнением операции над объектом r транзакция B выполняет следующие действия: Проверяет, не закончилась ли транзакция A, пометившая этот объект. Если A закончилась, B помечает объект r своей временной меткой и выполняет операцию. Если транзакция A не завершилась, то B проверяет конфликтность операций. Если операции неконфликтны, при объекте r остается или проставляется временная метка с меньшим значением (более ранняя), и транзакция B выполняет свою операцию. Если операции B и A конфликтуют, то если t(A) > t(B) (т.е. транзакция A является более "молодой", чем B), то транзакция A откатывается и, получив новую временную метку, начинается заново. Транзакция B продолжает работу. Если же t(A) < t(B) (A "старше" B), то транзакция B откатывается и, получив новую временную метку, начинается заново. Транзакция A продолжает работу.
В итоге система обеспечивает такую работу, при которой при возникновении конфликтов всегда откатывается более молодая транзакция (начавшаяся позже).
Очевидным недостатком метода временных меток является то, что может откатиться более дорогая транзакция, начавшаяся позже более дешевой.
К другим недостаткам метода временных меток относятся потенциально более частые откаты транзакций, чем в случае использования блокировок. Это связано с тем, что конфликтность транзакций определяется более грубо.
Множества
Множества
Наиболее простая структура данных, используемая в математике, имеет место в случае, когда между отдельными изолированными данными отсутствуют какие-либо взаимосвязи. Совокупность таких данных представляет собой множество. Понятие множества является неопределяемым понятием. Множество не обладает внутренней структурой. Множество можно представить себе как совокупность элементов, обладающих некоторым общим свойством. Для того чтобы некоторую совокупность элементов можно было назвать множеством, необходимо, чтобы выполнялись следующие условия: Должно существовать правило, позволяющее определить, принадлежит ли указанный элемент данной совокупности. Должно существовать правило, позволяющее отличать элементы друг от друга. (Это, в частности, означает, что множество не может содержать двух одинаковых элементов).
Множества обычно обозначаются заглавными латинскими буквами. Если элемент


Если каждый элемент множества

Подмножество
Используя понятие множества можно построить более сложные и содержательные объекты.
Nарные отношения (отношения степени n)
n-арные отношения (отношения степени n)
В математике n-арные отношения рассматриваются относительно редко, в отличие от баз данных, где наиболее важными являются именно отношения, заданные на декартовом произведении более чем двух множеств.
Пример 6. В некотором университете на математическом факультете учатся студенты Иванов, Петров и Сидоров. Лекции им читают преподаватели Пушников, Цыганов и Шарипов, причем известны следующие факты: Пушников читает лекции по алгебре и базам данных, соответственно, 40 и 80 часов в семестр. Цыганов читает лекции по геометрии, 50 часов в семестр. Шарипов читает лекции по алгебре и геометрии, соответственно, 40 и 50 часов в семестр. Студент Иванов посещает лекции по алгебре у Шарипова и по базам данных у Пушникова. Студент Петров посещает лекции по алгебре у Пушникова и по геометрии у Цыганова. Студент Сидоров посещает лекции по геометрии у Цыганова и по базам данных у Пушникова.
Для того чтобы формально описать данную ситуацию (например, в целях разработки информационной системы, учитывающей данные о ходе учебного процесса), введем три множества: Множество преподавателей

Имеющиеся факты можно разделить на две группы. 1 группа (факты 1-3) - факты о преподавателях, 2 группа (факты 4-6) - факты о студентах.
Для того чтобы отразить факты 1-3 (характеризующие преподавателей и читаемые ими лекции), введем отношение







Неповторяемое считывание
Неповторяемое считывание
Транзакция A дважды читает одну и ту же строку. Между этими чтениями вклинивается транзакция B, которая изменяет значения в строке.
Неповторяемое считывание
Неповторяемое считывание
Транзакция A дважды читает одну и ту же строку. Между этими чтениями вклинивается транзакция B, которая изменяет значения в строке.
Невыразимость транзитивного замыкания реляционными операторами
Невыразимость транзитивного замыкания реляционными операторами
Следующий пример иллюстрирует класс запросов, невыразимых средствами реляционной алгебры или реляционного исчисления по причине невыразимости средствами реляционной алгебры транзитивного замыкания отношений (см. гл. 1).
Пример 17. Рассмотрим отношение, описывающее сотрудников некоего предприятия. Отношение содержит данные о табельном номере сотрудника, фамилии, должности и табельном номере руководителя сотрудника v СОТРУДНИКИ (ТАБ_НОМ, ФАМИЛИЯ, ДОЛЖНОСТЬ, ТАБ_НОМ_РУК):
НФБК (Нормальная Форма БойсаКодда)
НФБК (Нормальная Форма Бойса-Кодда)
При приведении отношений при помощи алгоритма нормализации к отношениям в 3НФ неявно предполагалось, что все отношения содержат один потенциальный ключ. Это не всегда верно. Рассмотрим следующий пример отношения, содержащего два ключа.
Пример 1. Пусть требуется хранить данные о поставках деталей некоторыми поставщиками. Предположим, что наименования поставщиков являются уникальными. Кроме того, каждый поставщик имеет свой уникальный номер. Данные о поставках можно хранить в следующем отношении:
Nullзначения
Null-значения
Основное назначение баз данных состоит в том, чтобы хранить и предоставлять информацию о реальном мире. Для представления этой информации в базе данных используются привычные для программистов типы данных - строковые, численные, логические и т.п. Однако в реальном мире часто встречается ситуация, когда данные неизвестны или не полны. Например, место жительства или дата рождения человека могут быть неизвестны (база данных разыскиваемых преступников). Если вместо неизвестного адреса уместно было бы вводить пустую строку, то что вводить вместо неизвестной даты? Ответ - пустую дату - не вполне удовлетворителен, т.к. простейший запрос "выдать список людей в порядке возрастания дат рождения" даст заведомо неправильных ответ.
Для того чтобы обойти проблему неполных или неизвестных данных, в базах данных могут использоваться типы данных, пополненные так называемым null-значением. Null-значение - это, собственно, не значение, а некий маркер, показывающий, что значение неизвестно.
Таким образом, в ситуации, когда возможно появление неизвестных или неполных данных, разработчик имеет на выбор два варианта.
Первый вариант состоит в том, чтобы ограничиться использованием обычных типов данных и не использовать null-значения, а вместо неизвестных данных вводить либо нулевые значения, либо значения специального вида - например, договориться, что строка "АДРЕС НЕИЗВЕСТЕН" и есть те данные, которые нужно вводить вместо неизвестного адреса. В любом случае на пользователя (или на разработчика) ложится ответственность на правильную трактовку таких данных. В частности, может потребоваться написание специального программного кода, который в нужных случаях "вылавливал" бы такие данные. Проблемы, возникающие при этом очевидны - не все данные становятся равноправны, требуется дополнительный программный код, "отслеживающий" эту неравноправность, в результате чего усложняется разработка и сопровождение приложений.
Второй вариант состоит в использовании null-значений вместо неизвестных данных. За кажущейся естественностью такого подхода скрываются менее очевидные и более глубокие проблемы. Наиболее бросающейся в глаза проблемой является необходимость использования трехзначной логики при оперировании с данными, которые могут содержать null-значения. В этом случае при неаккуратном формулировании запросов, даже самые естественные запросы могут давать неправильные ответы. Есть более фундаментальные проблемы, связанные с теоретическим обоснованием корректности введения null-значений, например, непонятно вообще, входят ли null-значения в домены или нет.
Подробное обсуждение проблем использования null-значений выходит за пределы данной работы. Можно только сказать о том, что этот вопрос в теории реляционных баз данных окончательно не решен. Основоположник реляционного подхода Кодд считал null-значения неотъемлемой частью реляционной модели. К.Дейт, один из крупнейших теоретиков реляционной модели выступает категорически против null-значений (подробное обсуждение проблем, возникающих при использовании null-значений приведено в книге [11].
Практически все реализации современных реляционных СУБД позволяют использовать null-значения, несмотря на их недостаточную теоретическую обоснованность. Такую ситуацию можно сравнить с ситуацией, сложившейся в начале века с теорией множеств. Почти сразу после создания Кантором теории множеств, в ней были обнаружены внутренние противоречия (антиномии). Были разработаны более строгие теории, позволяющие избежать этих противоречий (конструктивная теория множеств). Однако в реальной работе большинство математиков пользуется классической теорией множеств, т.к. более строгие теории более ограничены и негибки в применении именно в силу своей большей строгости.
Мнение автора (очень скромное по сравнению с мнением корифеев реляционной теории) состоит в том, что желательно избегать null-значений. Тем не менее, приведем здесь описание трехзначной логики, необходимой для работы с null-значениями.
Объединение
Объединение
Определение 2. Объединением двух совместимых по типу отношений
Синтаксис операции объединения:

Замечание. Объединение, как и любое отношение, не может содержать одинаковых кортежей. Поэтому, если некоторый кортеж входит и в отношение
Пример 2. Пусть даны два отношения
Общая характеристика реляционной модели данных
Общая характеристика реляционной модели данных
Основы реляционной модели данных были впервые изложены в статье Е.Кодда [43] в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту [11]. Согласно Дейту, реляционная модель состоит из трех частей: Структурной части. Целостной части. Манипуляционной части.
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей.
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.
В данной главе рассматривается структурная часть реляционной модели.
Общая операция соединения
Общая операция соединения
Определение 8. Соединением отношений


Таким образом, операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях
Общие принципы реализации ограничений средствами SQL
Общие принципы реализации ограничений средствами SQL
Стандарт SQL не предусматривает процедурных ограничений целостности, реализуемых при помощи триггеров и хранимых процедур. В стандарте SQL 92 отсутствует понятие "триггер", хотя триггеры имеются во всех промышленных СУБД SQL-типа. Таким образом, реализация ограничений средствами конкретной СУБД обладает большей гибкостью, нежели с использованием исключительно стандартных средств SQL.
Стандарт SQL позволяет задавать декларативные ограничения следующими способами: Как ограничения домена. Как ограничения, входящие в определение таблицы. Как ограничения, хранящиеся в базе данных в виде независимых утверждений (assertion).
Допускаются как немедленно проверяемые, так и ограничения с отложенной проверкой. Режим проверки отложенных ограничений можно в любой момент изменить так, чтобы ограничение проверялось: После исполнения каждого оператора, изменяющего содержимое таблицы, к которой относится данное ограничение. При завершении каждой транзакции, включающей операторы, изменяющие содержимое таблиц, к которым относятся данное ограничение. В любой промежуточный момент, если пользователь инициирует проверку.
При определении ограничения указывается тип проверки ограничения - является ли это ограничение неоткладываемым (NOT DEFERRED) или может быть откладываемым (DEFERRED). Во втором случае можно задать процедуру по умолчанию: проверять немедленно или проверять по завершении транзакции. Таким образом, можно определить потенциально откладываемое ограничение, которое по умолчанию проверяется немедленно. В любой момент режим проверки такого ограничения можно изменить на отложенный и наоборот. Режим проверки может быть изменен для одного ограничения или сразу для всех потенциально откладываемых ограничений. Если ограничение определено как неоткладываемое, то тип такого ограничения изменить нельзя и ограничение всегда проверяется немедленно.
Элементы процедурности все же присутствуют в стандарте SQL в виде так называемых действий, исполняемых по ссылке (referential triggered actions). Эти действия определяют, что будет происходить при изменении значения родительского ключа, на который ссылается некоторый внешний ключ. Эти действия можно задавать независимо для операций обновления (ON UPDATE) или для операций удаления (ON DELETE) записей в родительском отношении. Стандартом SQL определяется 4 типа действий, исполняемых по ссылке: CASCADE. Изменения значения родительского ключа автоматически приводят к таким же изменениям связанного с ним значения внешнего ключа. Удаление кортежа в родительском отношении приводит к удалению связанных с ним кортежей в дочернем отношении. SET NULL. Все внешние ключи, которые ссылаются на обновленный или удаленный родительский ключ получают значения NULL. SET DEFAULT. Все внешние ключи, которые ссылаются на обновленный или удаленный родительский ключ получают значения, принятые по умолчанию для этих ключей. NO ACTION. Значения внешнего ключа не изменяются. Если операция приводит к нарушению ссылочной целостности (появляются "висящие" ссылки), то такая операция не выполняется.
Как видно, действия, исполняемые по ссылке, фактически являются встроенными в СУБД триггерами. Действия типа CASCADE, SET NULL и SET DEFAULT являются компенсирующими операциями, вызывающимися при попытке нарушить ссылочную целостность.
Обзор реляционной алгебры
Обзор реляционной алгебры
Третья часть реляционной модели, манипуляционная часть, утверждает, что доступ к реляционным данным осуществляется при помощи реляционной алгебры или эквивалентного ему реляционного исчисления.
В реализациях конкретных реляционных СУБД сейчас не используется в чистом виде ни реляционная алгебра, ни реляционное исчисление. Фактическим стандартом доступа к реляционным данным стал язык SQL (Structured Query Language). Язык SQL представляет собой смесь операторов реляционной алгебры и выражений реляционного исчисления, использующий синтаксис, близкий к фразам английского языка и расширенный дополнительными возможностями, отсутствующими в реляционной алгебре и реляционном исчислении. Вообще, язык доступа к данным называется реляционно полным, если он по выразительной силе не уступает реляционной алгебре (или, что то же самое, реляционному исчислению), т.е. любой оператор реляционной алгебры может быть выражен средствами этого языка. Именно таким и является язык SQL.
В данной главе будут рассмотрены основы реляционной алгебры.
Оглавление
Оглавление
ГЛАВА 1. ЭЛЕМЕНТЫ ТЕОРИИ МНОЖЕСТВ
Множества
Операции над множествами
Декартово произведение множеств
Отношение
Примеры отношений
Бинарные отношения (отношения степени 2)
Отношение эквивалентности
Отношения порядка
Функциональное отношение
Еще пример бинарного отношения
n-арные отношения (отношения степени n)
Транзитивное замыкание отношений
Выводы
ГЛАВА 2. БАЗОВЫЕ ПОНЯТИЯ РЕЛЯЦИОННОЙ МОДЕЛИ ДАННЫХ
Общая характеристика реляционной модели данных
Типы данных
Простые типы данных
Структурированные типы данных
Ссылочные типы данных
Типы данных, используемые в реляционной модели
Домены
Отношения, атрибуты, кортежи отношения
Определения и примеры
Свойства отношений
Первая нормальная форма
Выводы
ГЛАВА 3. ЦЕЛОСТНОСТЬ РЕЛЯЦИОННЫХ ДАННЫХ
Null-значения
Трехзначная логика (3VL)
Потенциальные ключи
Целостность сущностей
Внешние ключи
Целостность внешних ключей
Замечания к правилам целостности сущностей и внешних ключей
Операции, могущие нарушить ссылочную целостность
Для родительского отношения
Для дочернего отношения
Стратегии поддержания ссылочной целостности
Применение стратегий поддержания ссылочной целостности
При обновлении кортежа в родительском отношении
При удалении кортежа в родительском отношении
При вставке кортежа в дочернее отношение
При обновлении кортежа в дочернем отношении
Выводы
ГЛАВА 4. РЕЛЯЦИОННАЯ АЛГЕБРА.
Обзор реляционной алгебры
Замкнутость реляционной алгебры
Отношения, совместимые по типу
Оператор переименования атрибутов
Теоретико-множественные операторы
Объединение
Пересечение
Вычитание
Декартово произведение
Специальные реляционные операторы
Выборка (ограничение, селекция)
Проекция
Соединение
Общая операция соединения
Тэта-соединение
Экви-соединение
Естественное соединение
Деление
Примеры использования реляционных операторов
Зависимые реляционные операторы
Оператор соединения
Оператор пересечения
Оператор деления
Примитивные реляционные операторы
Оператор декартового произведения
Оператор проекции
Оператор выборки
Операторы объединения и вычитания
Запросы, невыразимые средствами реляционной алгебры
Плохая нормализация отношений
Невыразимость транзитивного замыкания реляционными операторами
Кросс-таблицы
Выводы
ГЛАВА 5. ЭЛЕМЕНТЫ ЯЗЫКА SQL.
Операторы SQL
Операторы DDL (Data Definition Language) - операторы определения объектов базы данных
Операторы DML (Data Manipulation Language) - операторы манипулирования данными
Операторы защиты и управления данными
Примеры использования операторов манипулирования данными
INSERT - вставка строк в таблицу
UPDATE - обновление строк в таблице
DELETE - удаление строк в таблице
Примеры использования оператора SELECT
Отбор данных из одной таблицы
Отбор данных из нескольких таблиц
Использование имен корреляции (алиасов, псевдонимов)
Использование агрегатных функций в запросах
Использование агрегатных функций с группировками
Использование подзапросов
Использование объединения, пересечения и разности
Синтаксис оператора выборки данных (SELECT)
BNF-нотация
Синтаксис оператора выборки
Синтаксис соединенных таблиц
Синтаксис условных выражений раздела WHERE
Порядок выполнения оператора SELECT
Стадия 1. Выполнение одиночного оператора SELECT
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Стадия 3. Упорядочение результата
Как на самом деле выполняется оператор SELECT
Реализация реляционной алгебры средствами оператора
SELECT (Реляционная полнота SQL)
Оператор декартового произведения
Оператор проекции
Оператор выборки
Оператор объединения
Оператор вычитания
Оператор соединения
Оператор пересечения
Оператор деления
Выводы
ГЛАВА 6. НОРМАЛЬНЫЕ ФОРМЫ ОТНОШЕНИЙ
Этапы разработки базы данных
Критерии оценки качества логической модели данных
Адекватность базы данных предметной области
Легкость разработки и сопровождения базы данных
Скорость операций обновления данных (вставка, обновление, удаление)
Скорость операций выборки данных
Основной пример
1НФ (Первая Нормальная Форма)
Аномалии обновления
Аномалии вставки (INSERT)
Аномалии обновления (UPDATE)
Аномалии удаления (DELETE)
Функциональные зависимости
Определение функциональной зависимости
Функциональные зависимости отношений и математическое понятие функциональной зависимости
2НФ (Вторая Нормальная Форма)
Анализ декомпозированных отношений
Оставшиеся аномалии вставки (INSERT)
Оставшиеся аномалии обновления (UPDATE)
Оставшиеся аномалии удаления (DELETE)
3НФ (Третья Нормальная Форма)
Алгоритм нормализации (приведение к 3НФ)
Анализ критериев для нормализованных и ненормализованных моделей данных
Сравнение нормализованных и ненормализованных моделей
OLTP и OLAP-системы
Корректность процедуры нормализации - декомпозиция без потерь. Теорема Хеза
Выводы
ГЛАВА 7. НОРМАЛЬНЫЕ ФОРМЫ БОЛЕЕ ВЫСОКИХ ПОРЯДКОВ
НФБК (Нормальная Форма Бойса-Кодда)
4НФ (Четвертая Нормальная Форма)
5НФ (Пятая Нормальная Форма)
Продолжение алгоритма нормализации (приведение к 5НФ)
Выводы
ГЛАВА 8. ЭЛЕМЕНТЫ МОДЕЛИ "СУЩНОСТЬ-СВЯЗЬ"
Основные понятия ER-диаграмм
Пример разработки простой ER-модели
Концептуальные и физические ER-модели
Выводы
ГЛАВА 9. ТРАНЗАКЦИИ И ЦЕЛОСТНОСТЬ БАЗ ДАННЫХ
Пример нарушения целостности базы
Понятие транзакции
Ограничения целостности
Классификация ограничений целостности
Классификация ограничений целостности по способам реализации
Классификация ограничений целостности по времени проверки
Классификация ограничений целостности по области действия
Ограничения домена
Ограничения атрибута
Ограничения кортежа
Ограничения отношения
Ограничения базы данных
Реализация декларативных ограничений целостности средствами SQL
Общие принципы реализации ограничений средствами SQL
Синтаксис ограничений стандарта SQL
Синтаксис операторов SQL, использующих ограничения
Выводы
ГЛАВА 10. ТРАНЗАКЦИИ И ПАРАЛЛЕЛИЗМ
Работа транзакций в смеси
Проблемы параллельной работы транзакций
Проблема потери результатов обновления
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Проблема несовместимого анализа
Неповторяемое считывание
Фиктивные элементы (фантомы)
Собственно несовместимый анализ
Конфликты между транзакциями
Блокировки
Решение проблем параллелизма при помощи блокировок
Проблема потери результатов обновления
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Проблема несовместимого анализа
Неповторяемое считывание
Фиктивные элементы (фантомы)
Собственно несовместимый анализ
Разрешение тупиковых ситуаций
Преднамеренные блокировки
Предикатные блокировки
Метод временных меток
Механизм выделения версий данных
Теорема Есварана о сериализуемости
Реализация изолированности транзакций средствами SQL
Уровни изоляции
Синтаксис операторов SQL, определяющих уровни изоляции
Выводы
ГЛАВА 11. ТРАНЗАКЦИИ И ВОССТАНОВЛЕНИЕ ДАННЫХ
Виды восстановления данных
Индивидуальный откат транзакции
Восстановление после мягкого сбоя
Восстановление после жесткого сбоя
Восстановление данных и стандарт SQL
Выводы
Ограничения атрибута
Ограничения атрибута
Определение 9. Ограничение целостности атрибута представляют собой ограничения, накладываемые на допустимые значения атрибута вследствие того, что атрибут основан на каком-либо домене. Ограничение атрибута в точности совпадают с ограничениями соответствующего домена. Отличие ограничений атрибута от ограничений домена в том, что ограничения атрибута проверяются.
Если логика предметной области такова, что на значения атрибута необходимо наложить дополнительные ограничения, помимо ограничений домена, то такие ограничения переходят в следующую категорию.
Проверка ограничения. Ограничение атрибута является немедленно проверяемым ограничением. Действительно, ограничение атрибута не зависит ни от каких других объектов базы данных, кроме домена, на котором основан атрибут. Поэтому никакие изменения в других объектах не могут повлиять на истинность ограничения.
Ограничения базы данных
Ограничения базы данных
Определение 12. Ограничения целостности базы данных представляют ограничения, накладываемые на значения двух или более связанных между собой отношений (в том числе отношение может быть связано само с собой).
Пример 13. Ограничение целостности ссылок (см. гл. 3), задаваемое внешним ключом отношения, является ограничением базы данных.
Пример 14. Ограничение на таблицы DEPART и PERSON из примера 1 является отношением базы данных, т.к. оно связывает данные, размещенные в различных таблицах.
Проверка ограничения. К моменту проверки ограничения базы данных должны быть проверены ограничения целостности отношений.
Ограничение базы данных может быть как немедленно проверяемым ограничением, так и ограничением с отложенной проверкой.
Ограничение отношения, являющееся ограничением внешнего ключа может быть как немедленно проверяемым ограничением, так и отложенным ограничением. Действительно, в простейшем случае, если кортеж


Ограничение, приведенное в примере 1, может быть только ограничением с отложенной проверкой.
Ограничения целостности
Ограничения целостности
Свойство (С) - согласованность транзакций определяется наличием понятия согласованности базы данных.
Определение 2. Ограничение целостности - это некоторое утверждение, которое может быть истинным или ложным в зависимости от состояния базы данных.
Примерами ограничений целостности могут служить следующие утверждения:
Пример 2. Возраст сотрудника не может быть меньше 18 и больше 65 лет.
Пример 3. Каждый сотрудник имеет уникальный табельный номер.
Пример 4. Сотрудник обязан числиться в одном отделе.
Пример 5. Сумма накладной обязана равняться сумме произведений цен товаров на количество товаров для всех товаров, входящих в накладную.
Как видно из этих примеров, некоторые из ограничений целостности являются ограничениями реляционной модели данных (см. гл. 3). Пример 3 представляет ограничение, реализующее целостность сущности. Пример 4 представляет ограничение, реализующее ссылочную целостность. Другие ограничения являются достаточно произвольными утверждениями (примеры 2 и 5). Любое ограничение целостности является семантическим понятием, т.е. появляется как следствие определенных свойств объектов предметной области и/или их взаимосвязей.
Определение 3. База данных находится в согласованном (целостном) состоянии, если выполнены (удовлетворены) все ограничения целостности, определенные для базы данных.
В данном определении важно подчеркнуть, что должны быть выполнены не все вообще ограничения предметной области, а только те, которые определены в базе данных. Для этого необходимо, чтобы СУБД обладала развитыми средствами поддержки ограничений целостности. Если какая-либо СУБД не может отобразить все необходимые ограничения предметной области, то такая база данных хотя и будет находиться в целостном состоянии с точки зрения СУБД, но это состояние не будет правильным с точки зрения пользователя.
Таким образом, согласованность базы данных есть формальное свойство базы данных. База данных не понимает "смысла" хранимых данных. "Смыслом" данных для СУБД является весь набор ограничений целостности. Если все ограничения выполнены, то СУБД считает, что данные корректны.
Вместе с понятием целостности базы данных возникает понятие реакции системы на попытку нарушения целостности. Система должна не только проверять, не нарушаются ли ограничения в ходе выполнения различных операций, но и должным образом реагировать, если операция приводит к нарушению целостности. Имеется два типа реакции на попытку нарушения целостности: Отказ выполнить "незаконную" операцию. Выполнение компенсирующих действий.
Например, если система знает, что в поле "Возраст_Сотрудника" должны быть целые числа в диапазоне от 18 до 65, то система отвергает попытку ввести значение возраста 66. При этом может генерироваться какое-нибудь сообщение для пользователя.
В противоположность этому, в примере 1 система допускает вставку записи о новом сотруднике (что приводит к нарушению целостности базы данных), но автоматически производит компенсирующие действия, изменяя значение поля Dept_Kol в таблице DEPART.
Работу системы по проверке ограничений можно изобразить на следующем рисунке:

Рисунок 1
В некоторых случаях система может не выполнять проверку на нарушение ограничений, а сразу выполнять компенсирующие операции. Действительно, в примере 1 при вставке или удалении сотрудника проверку производить не нужно, т.к. результаты ее известны заранее - ограничение обязательно будет нарушено. В этом случае необходимо сразу приступать к компенсированию возникшего нарушения.
Ограничения домена
Ограничения домена
Определение 8. Ограничения целостности домена представляют собой ограничения, накладываемые только на допустимые значения домена. Фактически, ограничения домена обязаны являться частью определения домена (см. определение домена в гл. 2).
Например, ограничением домена "Возраст сотрудника" может быть условие "Возраст сотрудника не менее 18 и не более 65".
Проверка ограничения. Ограничения домена сами по себе не проверяются. Если на каком-либо домене основан атрибут, то ограничение соответствующего домена становится ограничением этого атрибута.
Ограничения кортежа
Ограничения кортежа
Определение 10. Ограничения целостности кортежа представляют собой ограничения, накладываемые на допустимые значения отдельного кортежа отношения, и не являющиеся ограничением целостности атрибута. Требование, что ограничение относится к отдельному кортежу отношения, означает, что для его проверки не требуется никакой информации о других кортежах отношения.
Пример 6. Атрибут "Возраст сотрудника" в таблице "Спецподразделение", может иметь дополнительное ограничение "Возраст сотрудника не менее 25 и не более 45", помимо того, что этот атрибут уже имеет ограничение, определяемое доменом - "Возраст сотрудника не менее 18 и не более 65".
Приведенное ограничение кортежа, по сути, является дополнительным ограничением на значения одного атрибута. В этом случае допустимы два решения. Можно объявить новый домен "Возраст сотрудника спецподразделения" и тогда ограничение кортежа становится ограничением домена и атрибута, либо рассматривать это ограничение именно как ограничение кортежа. Оба решения имеют свои положительные и отрицательные стороны.
Замечание. Тут имеются некоторые возможности для оптимизации. Формально, при изменении значения данного атрибута необходимо проверить два ограничения - ограничение атрибута и ограничение кортежа. Но в данном случае ограничение кортежа сильнее ограничения атрибута и достаточно проверить только ограничение кортежа. Разумно построенная СУБД могла бы выявлять такие случаи и уменьшать лишнюю работу.
Пример 7. Для отношения "Сотрудники" можно сформулировать следующее ограничение: если атрибут "Должность" принимает значение "Директор", то атрибут "Зарплата" содержит значение не менее 1000$.
Это ограничение связывает два атрибута одного кортежа.
Пример 8. В накладной можно установить следующую взаимосвязь атрибутов - "Цена*Количество=Сумма", связывающую атрибуты "Цена", "Количество", "Сумма".
Данный пример кажется неестественным, т.к. сумма является явно избыточным атрибутом, значение которого просто выводятся из значений других атрибутов. Поэтому кажется, что лучше хранить только два базовых атрибута "Цена" и "Количество", а сумму вычислять во время выполнения запросов по мере необходимости. Так, собственно, требует реляционная теория, стремящаяся свести избыточность к минимуму. В практике, однако, дело обстоит сложнее. Например, каждая строка реальной накладной может содержать следующие данные о товаре:
Ограничения отношения
Ограничения отношения
Определение 11. Ограничения целостности отношения представляют ограничения, накладываемые только на допустимые значения отдельного отношения, и не являющиеся ограничением целостности кортежа. Требование, что ограничение относится к отдельному отношению, означает, что для его проверки не требуется информации о других отношениях (в том числе не требуется ссылок по внешнему ключу на кортежи этого же отношения).
Пример 9. Ограничение целостности сущности (см. гл. 3), задаваемое потенциальным ключом отношения, является ограничением отношения, т.к. для его проверки необходимо иметь информацию обо всех кортежах отношения (более точно, обо всех занятых в данный момент значениях потенциального ключа).
Пример 10. Ограничение целостности, определяемые наличием функциональных, многозначных зависимостей и зависимостей соединения, являются ограничениями отношения.
Пример 11. Предположим, что в отношении PERSON (см. пример 1) задано следующее ограничение - в каждом отделе должно быть не менее двух сотрудников. Это ограничение можно сформулировать так - количество строк с одинаковым значением Dept_Id должно быть не меньше 2.
Замечание. Для того чтобы ввести в действие (объявить) это ограничение, необходимо, чтобы в отношение уже были вставлены некоторые кортежи.
Пример 12. Ограничение целостности, определяемое требованием, что некоторая таблица должна быть не пуста, являются ограничениями отношения.
Проверка ограничения. К моменту проверки ограничения отношения должны быть проверены ограничения целостности кортежей этого отношения.
Ограничение отношения может быть как немедленно проверяемым ограничением, так и ограничением с отложенной проверкой.
Ограничение отношения, являющееся ограничением потенциального ключа (пример 9) является немедленно проверяемым ограничением.
Ограничение, определенное наличием функциональной зависимости атрибутов также является немедленно проверяемым ограничением.
Ограничения же, определенные многозначной зависимостью или зависимостью соединения являются ограничениями с отложенной проверкой. Действительно, эти ограничения требуют, чтобы кортежи вставлялись и удалялись целыми группами (см. гл. 7). Это невозможно сделать, если выполнять проверку после каждой одиночной вставки или удаления кортежа.
Ограничение в примере 11 кажется немедленно проверяемым. Действительно, можно сразу после вставки или удаления кортежа проверить, выполняется ли ограничение, и, если оно не выполняется, то откатить операцию. Но, однако, в этом случае, невозможно вставить ни один новый кортеж для нового отдела. В новый отдел необходимо вставить сразу не менее двух сотрудников. Таким образом, это ограничение с отложенной проверкой.
Ограничение из примера 12 имеет смысл проверять только при удалении кортежей из отношения. Это ограничение может быть как немедленно проверяемым, так и отложенным.
OLTP и OLAPсистемы
OLTP и OLAP-системы
Можно выделить некоторые классы систем, для которых больше подходят сильно или слабо нормализованные модели данных.
Сильно нормализованные модели данных хорошо подходят для так называемых OLTP-приложений (On-Line Transaction Processing (OLTP)- оперативная обработка транзакций). Типичными примерами OLTP-приложений являются системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег, и т.п. Основная функция подобных систем заключается в выполнении большого количества коротких транзакций. Сами транзакции выглядят относительно просто, например, "снять сумму денег со счета А, добавить эту сумму на счет В". Проблема заключается в том, что, во-первых, транзакций очень много, во-вторых, выполняются они одновременно (к системе может быть подключено несколько тысяч одновременно работающих пользователей), в-третьих, при возникновении ошибки, транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета А, но не поступили на счет В). Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов, таким образом, известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных. Чем выше уровень нормализации данных в OLTP-приложении, тем оно, как правило, быстрее и надежнее. Отступления от этого правила могут происходить тогда, когда уже на этапе разработки известны некоторые часто возникающие запросы, требующие соединения отношений и от скорости выполнения которых существенно зависит работа приложений. В этом случае можно пожертвовать нормализацией для ускорения выполнения подобных запросов.
Другим типом приложений являются так называемые OLAP-приложения (On-Line Analitical Processing (OLAP) - оперативная аналитическая обработка данных). Это обобщенный термин, характеризующий принципы построения систем поддержки принятия решений (Decision Support System - DSS), хранилищ данных (Data Warehouse), систем интеллектуального анализа данных (Data Mining). Такие системы предназначены для нахождения зависимостей между данными (например, можно попытаться определить, как связан объем продаж товаров с характеристиками потенциальных покупателей), для проведения анализа "что если-". OLAP-приложения оперируют с большими массивами данных, уже накопленными в OLTP-приложениях, взятыми их электронных таблиц или из других источников данных. Такие системы характеризуются следующими признаками: Добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-приложения). Данные, добавленные в систему, обычно никогда не удаляются. Перед загрузкой данные проходят различные процедуры "очистки", связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны. Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного в результате предыдущего запроса. Скорость выполнения запросов важна, но не критична.
Данные OLAP-приложений обычно представлены в виде одного или нескольких гиперкубов, измерения которого представляют собой справочные данные, а в ячейках самого гиперкуба хранятся собственно данные. Например, можно построить гиперкуб, измерениями которого являются: время (в кварталах, годах), тип товара и отделения компании, а в ячейках хранятся объемы продаж. Такой гиперкуб будет содержать данных о продажах различных типов товаров по кварталам и подразделениям. Основываясь на этих данных, можно отвечать на вопросы вроде "у какого подразделения самые лучшие объемы продаж в текущем году?", или "каковы тенденции продаж отделений Юго-Западного региона в текущем году по сравнению с предыдущим годом?"
Физически гиперкуб может быть построен на основе специальной многомерной модели данных (MOLAP - Multidimensional OLAP) или построен средствами реляционной модели данных (ROLAP - Relational OLAP).
Возвращаясь к проблеме нормализации данных, можно сказать, что в системах OLAP, использующих реляционную модель данных (ROLAP), данные целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных. При этом происходит как добавление новых данных, так и пересчет итогов.
Операции могущие нарушить ссылочную целостность
Операции, могущие нарушить ссылочную целостность
Ссылочная целостность может нарушиться в результате операций, изменяющих состояние базы данных. Таких операций три - вставка, обновление и удаление кортежей в отношениях. Т.к. в определении ссылочной целостности участвуют два отношения - родительское и дочернее, а в каждом из них возможны три операции - вставка, обновление, удаление, то нужно рассмотреть шесть различных вариантов.
Операции над множествами
Операции над множествами
Основными операциями над множествами являются объединение, пересечение и разность.
Определение 1. Объединением двух множеств называется новое множество

Определение 2. Пересечением двух множеств называется новое множество

Определение 3. Разностью двух множеств называется новое множество

Если класс объектов, на которых определяются различные множества обозначить


Оператор декартового произведения
Оператор декартового произведения
Оператор декартового произведения - это единственный оператор, увеличивающий количество атрибутов, поэтому его нельзя выразить через объединение, вычитание, выборку, проекцию.
Оператор декартового произведения
Оператор декартового произведения
Реляционная алгебра:
Оператор SQL: SELECT A.Поле1, A.Поле2, -, B.Поле1, B.Поле2, - FROM A, B;
или SELECT A.Поле1, A.Поле2, -, B.Поле1, B.Поле2, - FROM A CROSS JOIN B;
Оператор деления
Оператор деления
Оператор деления выражается через операторы вычитания, декартового произведения и проекции следующим образом:

Таким образом показано, что операторы соединения, пересечения и деления можно выразить через другие реляционные операторы, т.е. эти операторы не являются примитивными.
Оператор деления
Оператор деления
Реляционная алгебра:

Оператор SQL: SELECT DISTINCT A.X FROM A WHERE NOT EXIST (SELECT * FROM B WHERE NOT EXIST (SELECT * FROM A A1 WHERE A1.X = A.X AND A1.Y = B.Y));
Замечание. Оператор SQL, реализующий деление отношений трудно запомнить, поэтому дадим пример эквивалентного преобразования выражений, представляющих суть запроса.
Пусть отношение A содержит данные о поставках деталей, отношение B содержит список всех деталей, которые могут поставляться. Атрибут X является номером поставщика, атрибут Y является номером детали.
Разделить отношение A на отношение B означает в данном примере "отобрать номера поставщиков, которые поставляют все детали".
Преобразуем текст выражения:
"Отобрать номера поставщиков, которые поставляют все детали" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует непоставляемых деталей в таблице B" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует тех номеров деталей из таблицы B, которые не поставляются этим поставщиком" эквивалентно
"Отобрать те номера поставщиков из таблицы A, для которых не существует тех номеров деталей из таблицы B, для которых не существует записей о поставках в таблице A для этого поставщика и этой детали".
Последнее выражение дословно переводится на язык SQL. При переводе выражения на язык SQL нужно учесть, что во внутреннем подзапросе таблица A должна быть переименована, для того чтобы отличать ее от экземпляра этой же таблицы, используемой во внешнем запросе.
Оператор объединения
Оператор объединения
Реляционная алгебра:
Оператор SQL: SELECT * FROM A UNION SELECT * FROM B;
Оператор переименования атрибутов
Оператор переименования атрибутов
Оператор переименования атрибутов имеет следующий синтаксис:

где


В результате применения оператора переименования атрибутов получаем новое отношение, с измененными именами атрибутов.
Пример 1.
Следующий оператор возвращает неименованное отношение, в котором атрибут



Оператор пересечения
Оператор пересечения
Оператор пересечения выражается через вычитание следующим образом:

Оператор пересечения
Оператор пересечения
Реляционная алгебра:

Оператор SQL: SELECT * FROM A INTERSECT SELECT * FROM B;
Оператор проекции
Оператор проекции
Оператор проекции - единственный оператор, уменьшающий количество атрибутов, поэтому его нельзя выразить через объединение, вычитание, декартово произведение, выборку.
Оператор проекции
Оператор проекции
Реляционная алгебра:

Оператор SQL: SELECT DISTINCT X, Y, -, Z FROM A;
Оператор соединения
Оператор соединения
Оператор соединения определяется через операторы декартового произведения и выборки. Для оператора естественного соединения добавляется оператор проекции.
Оператор соединения
Оператор соединения
Реляционная алгебра:
Оператор SQL: SELECT A.Поле1, A.Поле2, -, B.Поле1, B.Поле2, - FROM A, B WHERE c;
или SELECT A.Поле1, A.Поле2, -, B.Поле1, B.Поле2, - FROM A CROSS JOIN B WHERE c;
Оператор выборки
Оператор выборки
Оператор выборки - единственный оператор, позволяющий проводить сравнения по атрибутам отношения, поэтому его нельзя выразить через объединение, вычитание, декартово произведение, проекцию.
Оператор выборки
Оператор выборки
Реляционная алгебра:

Оператор SQL: SELECT * FROM A WHERE c;
Оператор вычитания
Оператор вычитания
Реляционная алгебра:

Реляционный оператор переименования RENAME выражается при помощи ключевого слова AS в списке отбираемых полей оператора SELECT. Таким образом, язык SQL является реляционно полным.
Остальные операторы реляционной алгебры (соединение, пересечение, деление) выражаются через примитивные, следовательно, могут быть выражены операторами SQL. Тем не менее, для практических целей приведем их.
Операторы DDL (Data Definition Language) операторы определения объектов базы данных
Операторы DDL (Data Definition Language) - операторы определения объектов базы данных
CREATE SCHEMA - создать схему базы данных DROP SHEMA - удалить схему базы данных CREATE TABLE - создать таблицу ALTER TABLE - изменить таблицу DROP TABLE - удалить таблицу CREATE DOMAIN - создать домен ALTER DOMAIN - изменить домен DROP DOMAIN - удалить домен CREATE COLLATION - создать последовательность DROP COLLATION - удалить последовательность CREATE VIEW - создать представление DROP VIEW - удалить представление
Операторы DML (Data Manipulation Language) операторы манипулирования данными
Операторы DML (Data Manipulation Language) - операторы манипулирования данными
SELECT - отобрать строки из таблиц INSERT - добавить строки в таблицу UPDATE - изменить строки в таблице DELETE - удалить строки в таблице COMMIT - зафиксировать внесенные изменения ROLLBACK - откатить внесенные изменения
Операторы объединения и вычитания
Операторы объединения и вычитания
Доказательство примитивности операторов объединения и вычитания более сложны и мы их здесь не приводим.
Операторы SQL
Операторы SQL
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям.
Можно выделить следующие группы операторов (перечислены не все операторы SQL):
Операторы защиты и управления данными
Операторы защиты и управления данными
CREATE ASSERTION - создать ограничение DROP ASSERTION - удалить ограничение GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами REVOKE - отменить привилегии пользователя или приложения
Кроме того, есть группы операторов установки параметров сеанса, получения информации о базе данных, операторы статического SQL, операторы динамического SQL.
Наиболее важными для пользователя являются операторы манипулирования данными (DML).
Определение функциональной зависимости
Определение функциональной зависимости
Для устранения указанных аномалий (а на самом деле для правильного проектирования модели данных!) применяется метод нормализации отношений. Нормализация основана на понятии функциональной зависимости атрибутов отношения.
Определение 1. Пусть




Множество атрибутов
Замечание. Если атрибуты
Пример 1. В отношении СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно привести следующие примеры функциональных зависимостей:
Зависимость атрибутов от ключа отношения:
{Н_СОТР, Н_ПРО}
{Н_СОТР, Н_ПРО}
{Н_СОТР, Н_ПРО}
{Н_СОТР, Н_ПРО}
{Н_СОТР, Н_ПРО}
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР
Н_СОТР
Н_СОТР
Зависимость наименования проекта от номера проекта:
Н_ПРО
Зависимость номера телефона от номера отдела:
Н_ОТД
Замечание. Приведенные функциональные зависимости не выведены из внешнего вида отношения, приведенного в таблице 1. Эти зависимости отражают взаимосвязи, обнаруженные между объектами предметной области и являются дополнительными ограничениями, определяемыми предметной областью. Таким образом, функциональная зависимость - семантическое понятие. Она возникает, когда по значениям одних данных в предметной области можно определить значения других данных. Например, зная табельный номер сотрудника, можно определить его фамилию, по номеру отдела можно определить телефона. Функциональная зависимость задает дополнительные ограничения на данные, которые могут храниться в отношениях. Для корректности базы данных (адекватности предметной области) необходимо при выполнении операций модификации базы данных проверять все ограничения, определенные функциональными зависимостями.
Определения и примеры
Определения и примеры
Фундаментальным понятием реляционной модели данных является понятие отношения. В определении понятия отношения будем следовать книге К. Дейта [11].
Определение 1. Атрибут отношения есть пара вида <Имя_атрибута : Имя_домена>.
Имена атрибутов должны быть уникальны в пределах отношения. Часто имена атрибутов отношения совпадают с именами соответствующих доменов.
Определение 2. Отношение

Заголовок отношения содержит фиксированное количество атрибутов отношения:

Тело отношения содержит множество кортежей отношения. Каждый кортеж отношения представляет собой множество пар вида <Имя_атрибута : Значение_атрибута>:

таких что значение



Отношение обычно записывается в виде:

или короче

или просто
Число атрибутов в отношении называют степенью (или -арностью) отношения.
Мощность множества кортежей отношения называют мощностью отношения.
Возвращаясь к математическому понятию отношения, введенному в предыдущей главе, можно сделать следующие выводы:
Вывод 1. Заголовок отношения описывает декартово произведение доменов, на котором задано отношение. Заголовок статичен, он не меняется во время работы с базой данных. Если в отношении изменены, добавлены или удалены атрибуты, то в результате получим уже другое отношение (пусть даже с прежним именем).
Вывод 2. Тело отношения представляет собой набор кортежей, т.е. подмножество декартового произведения доменов. Таким образом, тело отношения собственно и является отношением в математическом смысле слова. Тело отношения может изменяться во время работы с базой данных - кортежи могут изменяться, добавляться и удаляться.
Пример 1. Рассмотрим отношение "Сотрудники" заданное на доменах "Номер_сотрудника", "Фамилия", "Зарплата", "Номер_отдела". Т.к. все домены различны, то имена атрибутов отношения удобно назвать так же, как и соответствующие домены. Заголовок отношения имеет вид:
Сотрудники (Номер_сотрудника, Фамилия, Зарплата, Номер_отдела)
Пусть в данный момент отношение содержит три кортежа:
(1,Иванов, 1000, 1)
(2, Петров, 2000, 2)
(3, Сидоров, 3000, 1)
такое отношение естественным образом представляется в виде таблицы:
Основной пример
Основной пример
Рассмотрим в качестве предметной области некоторую организацию, выполняющую некоторые проекты. Модель предметной области опишем следующим неформальным текстом: Сотрудники организации выполняют проекты. Проекты состоят из нескольких заданий. Каждый сотрудник может участвовать в одном или нескольких проектах, или временно не участвовать ни в каких проектах. Над каждым проектом может работать несколько сотрудников, или временно проект может быть приостановлен, тогда над ним не работает ни один сотрудник. Над каждым заданием в проекте работает ровно один сотрудник. Каждый сотрудник числится в одном отделе. Каждый сотрудник имеет телефон, находящийся в отделе сотрудника.
В ходе дополнительного уточнения того, какие данные необходимо учитывать, выяснилось следующее: О каждом сотруднике необходимо хранить табельный номер и фамилию. Табельный номер является уникальным для каждого сотрудника. Каждый отдел имеет уникальный номер. Каждый проект имеет номер и наименование. Номер проекта является уникальным. Каждая работа из проекта имеет номер, уникальный в пределах проекта. Работы в разных проектах могут иметь одинаковые номера.
Основные понятия ERдиаграмм
Основные понятия ER-диаграмм
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе.
Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
Каждая сущность в модели изображается в виде прямоугольника с наименованием:

Рис. 1
Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:

Рис. 2
Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием:

Рис. 3
Определение 5. Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:

Рис. 4
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:

Рис. 5
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный пример такой связи приведен на Рис. 4.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:

Рис. 6
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Связь может иметь разную модальность с разных концов (как на Рис. 4).
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>.
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так:
Слева направо: "каждый сотрудник может иметь несколько детей".
Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
Оставшиеся аномалии обновления (UPDATE)
Оставшиеся аномалии обновления (UPDATE)
Одни и те же номера телефонов повторяются во многих кортежах отношения. Поэтому если в отделе меняется номер телефона, то такие изменения необходимо одновременно выполнить во всех местах, где этот номер телефона встречаются, иначе отношение станет некорректным. Таким образом, обновление базы данных одним действием реализовать невозможно. Необходимо написать триггер, который при обновлении одной записи корректно исправляет номера телефонов в других местах.
Причина аномалии - избыточность данных, также порожденная тем, что в одном отношении хранится разнородная информация.
Вывод - увеличивается сложность разработки базы данных. База данных, основанная на такой модели, будет работать правильно только при наличии дополнительного программного кода в виде триггеров.
