Этот же запрос может быть
Пример 14
| Иванов | Петров | Болт | 100 |
| Иванов | Сидоров | Гайка | 200 |
| Иванов | Сидоров | Винт | 300 |
| Петров | Сидоров | Болт | 150 |
| Петров | Сидоров | Гайка | 250 |
| Сидоров | Иванов | Болт | 1000 |
Замечание. Этот же запрос может быть выражен очень большим количеством способов, например, так:
SELECT P.NAME AS PNAME, C.NAME AS CNAME, DETAILS.DNAME, CD.VOLUME FROM CONTRAGENTS P, CONTRAGENTS C, DETAILS NATURAL JOIN CD WHERE P.NUM = CD.PNUM AND C.NUM = CD.CNUM;
что этого не может быть,
Пример 14
| 1 | Иванов | 1000 |
| 2 | Петров | 1000 |
| 2 | Сидоров | 2000 |
Таблица 13 Отношение

Кажется, что этого не может быть, т.к. значения в атрибуте "НОМЕР" повторяются. Но мы же ничего не говорили о ключе этого отношения! Сейчас проекции будут иметь вид:
включающие по два атрибута, имеют
Пример 14
| 1 | 1 | 2 |
| 1 | 2 | 1 |
| 2 | 1 | 1 |
| 1 | 1 | 1 |
Таблица 14 Отношение R
Всевозможные проекции отношения
с целью потом блокировать строки)
Пример 14
| S-блокировка таблицы ( с целью потом блокировать строки) - успешна |  |
--- |
S-блокировка строк, удовлетворяющих условию  (Заблокировано n строк) |
 |
--- |
| Выборка строк, удовлетворяющих условию (Отобрано n строк) |
 |
--- |
| --- |  |
IX-блокировка таблицы (с целью потом вставлять строки) - отвергается из-за конфликта с S-блокировкой, наложенной транзакцией A |
| --- |  |
Ожидание- |
| --- |  |
Ожидание- |
| S-блокировка строк, удовлетворяющих условию (Заблокировано n строк) |
 |
Ожидание- |
| Выборка строк, удовлетворяющих условию (Отобрано n строк) |
 |
Ожидание- |
| Фиксация транзакции - блокировки снимаются |  |
Ожидание- |
| --- |  |
IX-блокировка таблицы (с целью потом вставлять строки) - успешна |
| --- |  |
Вставка новой строки, удовлетворяющей условию |
| --- |  |
Фиксация транзакции |
Результат. Проблема фиктивных элементов (фантомов) решается, если транзакция A использует преднамеренную S-блокировку или более сильную.
Замечание. Т.к. транзакция A собирается только читать строки таблицы, то минимально необходимым условием в соответствии с протоколом преднамеренных блокировок является преднамеренная IS-блокировка таблицы. Однако этот тип блокировки не предотвращает появление фантомов. Таким образом, транзакцию A можно запускать с разными уровнями изолированности - предотвращая или допуская появление фантомов. Причем, оба способа запуска соответствуют протоколу преднамеренных блокировок для доступа к данным.
Какие поставщики поставляют какие
Пример 15
| 1 | Иванов | 4 | 1 | Болт | 3 |
| 1 | Иванов | 4 | 2 | Гайка | 2 |
| 1 | Иванов | 4 | 3 | Винт | 1 |
| 2 | Петров | 1 | 3 | Винт | 1 |
| 3 | Сидоров | 2 | 2 | Гайка | 2 |
| 3 | Сидоров | 2 | 3 | Винт | 1 |
Таблица 15 Отношение " Какие поставщики поставляют какие детали"
и среднее количества поставляемых деталей
Пример 15
| 3 |
Пример 22. Получить общее, максимальное, минимальное и среднее количества поставляемых деталей (ключевые слова SUM, MAX, MIN, AVG):
SELECT SUM(PD.VOLUME) AS SM, MAX(PD.VOLUME) AS MX, MIN(PD.VOLUME) AS MN, AVG(PD.VOLUME) AS AV FROM PD;
В результате получим следующую таблицу с одной строкой:
Таблица 14 Отношение
Пример 15
| 1 | Иванов |
| 2 | Петров |
| 2 | Сидоров |
Таблица 14 Отношение

Таблица 15 Проекция
Пример 15
| 1 | 1 |
| 1 | 2 |
| 2 | 1 |
Таблица 15 Проекция R1=R[X,Y]
SCN транзакции больше SCN счета.
Пример 15
Проверка SCN счета  Чтение счета 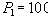  |
|
--- |
| --- | |
X-блокировка счета  |
| --- | |
Снятие денег со счета   |
| --- | |
X-блокировка счета  |
| --- | |
Помещение денег на счет  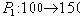 |
| --- | |
Фиксация транзакции (Снятие блокировок) |
Проверка SCN счета  Чтение счета   |
|
--- |
Проверка SCN счета  Чтение старого варианта счета   |
|
--- |
| Фиксация транзакции | |
--- |
Результат. Транзакция A, начавшаяся первой не тормозит конкурирующую транзакцию B. При обнаружении конфликта (чтение транзакцией A измененного счета 3), транзакции A предоставляется своя версия данных, которая была на момент начала транзакции A.
Таблица 16 Отношение
Пример 16
| 1 | Иванов |
| 2 | Петров |
| 3 | Сидоров |
Таблица 16 Отношение P (Поставщики)
Пример SM MX MN AV
Пример 16
| 2000 | 1000 | 100 | 333.33333333 |
Естественное соединение этих проекций будет
Пример 16
| 1 | 1000 |
| 2 | 1000 |
| 2 | 2000 |
Таблица 15 Отношение

Естественное соединение этих проекций будет содержать лишние кортежи:
Таблица 16 Проекция
Пример 16
| 1 | 2 |
| 1 | 1 |
| 2 | 1 |
Таблица 16 Проекция R2=R[X,Z]
Уровни изоляции стандарта
Пример 16
| Да | Да | Да |
| Да | Да | |
| Да | ||
Таблица 4 Уровни изоляции стандарта SQL
Таблица 17 Отношение
Пример 17
| 1 | Болт |
| 2 | Гайка |
| 3 | Винт |
Таблица 17 Отношение D (Детали)
В списке отбираемых полей оператора
Пример 17
| 1 | 1250 |
| 2 | 450 |
| 3 | 300 |
Замечание. В списке отбираемых полей оператора SELECT, содержащего раздел GROUP BY можно включать только агрегатные функции и поля, которые входят в условие группировки. Следующий запрос выдаст синтаксическую ошибку:
SELECT PD.PNUM, PD.DNUM, SUM(PD.VOLUME) AS SM GROUP BY PD.DNUM;
Причина ошибки в том, что в список отбираемых полей включено поле PNUM, которое не входит в раздел GROUP BY. И действительно, в каждую полученную группу строк может входить несколько строк с различными значениями поля PNUM. Из каждой группы строк будет сформировано по одной итоговой строке. При этом нет однозначного ответа на вопрос, какое значение выбрать для поля PNUM в итоговой строке.
Замечание. Некоторые диалекты SQL не считают это за ошибку. Запрос будет выполнен, но предсказать, какие значения будут внесены в поле PNUM в результатирующей таблице, невозможно.
Пример 24. Получить номера деталей, суммарное поставляемое количество которых превосходит 400 (ключевое слово HAVING-):
Замечание. Условие, что суммарное поставляемое количество должно быть больше 400 не может быть сформулировано в разделе WHERE, т.к. в этом разделе нельзя использовать агрегатные функции. Условия, использующие агрегатные функции должны быть размещены в специальном разделе HAVING:
SELECT PD.DNUM, SUM(PD.VOLUME) AS SM GROUP BY PD.DNUM HAVING SUM(PD.VOLUME) > 400;
В результате получим следующую таблицу:
Таким образом, без дополнительных ограничений
Пример 17
| 1 | Иванов | 1000 |
| 2 | Петров | 1000 |
| 2 | Петров | 2000 |
| 2 | Сидоров | 1000 |
| 2 | Сидоров | 2000 |
Таблица 16 Отношение

Вывод. Таким образом, без дополнительных ограничений на отношение
Такими дополнительными ограничениями и являются функциональные зависимости. Имеет место следующая теорема Хеза [54]:
Теорема (Хеза). Пусть





Доказательство. Необходимо доказать, что



Докажем первое включение. Возьмем произвольный кортеж









Докажем обратное включение. Возьмем произвольный кортеж










Замечание. В доказательстве теоремы Хеза наличие функциональной зависимости не использовалось при доказательстве включения
Т.к. алгоритм нормализации (приведения отношений к 3НФ) основан на имеющихся в отношениях функциональных зависимостях, то теорема Хеза показывает, что алгоритм нормализации является корректным, т.е. в ходе нормализации не происходит потери информации.
не восстанавливается ни по одному
Пример 17
| 1 | 2 |
| 2 | 1 |
| 1 | 1 |
Таблица 17 Проекция R3=R[Y,Z]
Как легко заметить, отношение



Ответ на вопрос, какие детали
Пример 18
| 1 | 1 | 100 |
| 1 | 2 | 200 |
| 1 | 3 | 300 |
| 2 | 1 | 150 |
| 2 | 2 | 250 |
| 3 | 1 | 1000 |
Таблица 18 Отношение PD (Поставки)
Ответ на вопрос, какие детали поставляются поставщиками, дает экви-соединение


Обычно, такой сложной формой записи не пользуются. Но как бы то ни было, в результате имеем отношение:
В одном запросе могут встретиться
Пример 18
| 1 | 1250 |
| 2 | 450 |
Замечание. В одном запросе могут встретиться как условия отбора строк в разделе WHERE, так и условия отбора групп в разделе HAVING. Условия отбора групп нельзя перенести из раздела HAVING в раздел WHERE. Аналогично и условия отбора строк нельзя перенести из раздела WHERE в раздел HAVING, за исключением условий, включающих поля из списка группировки GROUP BY.
Серым цветом выделен лишний кортеж,
Пример 18
| 1 | 1 | 2 |
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 1 | 2 | 1 |
| 2 | 1 | 1 |
Таблица 18 R1 JOIN R2
Серым цветом выделен лишний кортеж, отсутствующий в отношении
Однако отношение

Это говорит о том, что между атрибутами этого отношения также имеется некоторая зависимость, но эта зависимость не является ни функциональной, ни многозначной зависимостью.
Определение 5. Пусть



тогда и только тогда, когда оно равносильно соединению всех своих проекций с подмножествами атрибутов

Можно предположить, что отношение

Утверждать, что это именно так мы пока не можем, т.к. определение зависимости соединения должно выполняться для любого состояния отношения
Покажем, что зависимость соединения является обобщением понятия многозначной зависимости. Действительно, согласно теореме Фейджина, отношение


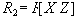

Теорема Фейджина (другая формулировка). Отношение

Т.к. теорема Фейджина является взаимно обратной, то ее можно взять в качестве определения многозначной зависимости. Таким образом, многозначная зависимость является частным случаем зависимости соединения, т.е., если в отношении имеется многозначная зависимость, то имеется и зависимость соединения. Обратное, конечно, неверно.
Определение 6. Зависимость соединения
Одно из множеств атрибутов

Ни одно из множеств атрибутов не совпадает со всем множеством атрибутов отношения
Для удобства работы сформулируем это определение так же и в отрицательной форме:
Определение 7. Зависимость соединения
Определение 8. Отношение
Определения 5НФ может стать более понятным, если сформулировать его в отрицательной форме:
Определение 9. Отношение
Возвращаясь к примеру 3, становится понятно, что не зная ничего о том, какие потенциальные ключи имеются в отношении и как взаимосвязаны атрибуты, нельзя делать выводы о том, находится ли данное отношение в 5НФ (как, впрочем, и в других нормальных формах). По данному конкретному примеру можно только предположить, что отношение в примере 3 не находится в 5НФ. Предположим, что анализ предметной области позволил выявить следующие зависимости атрибутов в отношении
(i) Отношение
(ii) Имеется следующая зависимость (довольно странная, с практической точки зрения): если в отношении

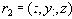


Утверждение. Докажем, что при наличии ограничений (i) и (ii), отношение находится в 4НФ, но не в 5НФ.
Доказательство. Покажем, что отношение
Покажем, что отношение не находится в 5НФ. Для этого нужно привести пример нетривиальной зависимости соединения. Естественным кандидатом на нее является



Но является ли такая декомпозиция именно зависимостью соединения? Для этого нужно показать, что декомпозиция на три проекции



Как и в предыдущих доказательствах, нужно доказать, что
Включение

Докажем включение

Пусть кортеж












соединения является то, что если
Пример 19
| 1 | Иванов | 1 | 1 | 100 |
| 1 | Иванов | 1 | 2 | 200 |
| 1 | Иванов | 1 | 3 | 300 |
| 2 | Петров | 2 | 1 | 150 |
| 2 | Петров | 2 | 2 | 250 |
| 3 | Сидоров | 3 | 1 | 1000 |
Таблица 19 Отношение "Какие детали поставляются какими поставщиками"
Недостатком экви- соединения является то, что если соединение происходит по атрибутам с одинаковыми наименованиями (а так чаще всего и происходит!), то в результатирующем отношении появляется два атрибута с одинаковыми значениями. В нашем примере атрибуты PNUM1 и PNUM2 содержат дублирующие данные. Избавиться от этого недостатка можно, взяв проекцию по всем атрибутам, кроме одного из дублирующих. Именно так действует естественное соединение.
P JOIN PD JOIN
Пример 20
| 1 | Иванов | 1 | Болт | 100 |
| 1 | Иванов | 2 | Гайка | 200 |
| 1 | Иванов | 3 | Винт | 300 |
| 2 | Петров | 1 | Болт | 150 |
| 2 | Петров | 2 | Гайка | 250 |
| 3 | Сидоров | 1 | Болт | 1000 |
Таблица 20 Отношение P JOIN PD JOIN D
В качестве делителя возьмем проекцию
Пример 21
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 2 |
| 3 | 1 |
Таблица 21 Проекция X=PD[PNUM,DNUM]
В качестве делителя возьмем проекцию

дает список номеров поставщиков, поставляющих
Пример 22
| 1 |
| 2 |
| 3 |
Таблица 22 Проекция Y=D[DNUM]
Деление

Таблица 23 Отношение
Пример 23
| 1 |
Таблица 23 Отношение X DEVIDEBY Y
Оказалось, что только поставщик с номером 1 поставляет все детали.
Найти все химические элементы, содержание
Пример 24
| Дезоксирибону-клеиновая кислота | 5 | 3 | - | 0.01 |
| Бензин | 50 | 0 | - | 0 |
| - | - | - | - | - |
Таблица 24 Отношение ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ
Рассмотрим запрос " Найти все химические элементы, содержание которых в каком-либо из веществ превышает заданный процент (скажем, 90)".
С алгоритмической точки зрения этот запрос выполняется элементарно - просматриваются все столбцы таблицы, если в столбце присутствует хотя бы одно значение, большее 90, то запоминается заголовок этого столбца. Набор наименований запомненных столбцов и является ответом на запрос.
Формально невозможно выразить этот запрос в рамках реляционной алгебры, т.к. ответом на этот запрос должен быть список атрибутов отношений, удовлетворяющих определенному условию. В реляционной алгебре нет операторов, манипулирующих с наименованиями атрибутов.
На самом деле, этот пример показывает, что таблица плохо нормализована (нормализация отношений рассматривается в гл.6 и 7). В таблице есть набор однотипных атрибутов ("Водород", "Гелий" и т.д. в количестве 105 столбцов).
Правильнее разбить это отношение на три различных отношения:
ВЕЩЕСТВО(НОМ_ВЕЩЕСТВА, ВЕЩЕСТВО), ЭЛЕМЕНТЫ(НОМ_ЭЛЕМЕНТА, ЭЛЕМЕНТ), ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ(НОМ_ВЕЩЕСТВА, НОМ_ЭЛЕМЕНТА, ПРОЦЕНТ).
Таблица 25 Отношение
Пример 25
| 1 | Дезоксирибонуклеиновая кислота |
| 2 | Бензин |
Таблица 25 Отношение ВЕЩЕСТВО
Таблица 26 Отношение
Пример 26
| 1 | Водород |
| 2 | Гелий |
| - | - |
| 105 | - |
Таблица 26 Отношение ЭЛЕМЕНТЫ
Для отношений, нормализованных таким образом,
Пример 27
| 1 | 1 | 5 |
| 1 | 2 | 3 |
| 1 | 105 | 0.01 |
| 2 | 1 | 50 |
Таблица 27 Отношение ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ
Для отношений, нормализованных таким образом, исходный запрос реализуется следующей последовательностью операторов:
R1(НОМЕР_ВЕЩЕСТВА,НОМ_ЭЛЕМЕНТА,ПРОЦЕНТ)= ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ[ПРОЦЕНТ>90]. (Выборка из отношения). R2(НОМ_ЭЛЕМЕНТА) = R1[НОМ_ЭЛЕМЕНТА]. (Проекция отношения). R3(НОМ_ЭЛЕМЕНТА,ЭЛЕМЕНТ)= R2[НОМ_ЭЛЕМЕНТА=НОМ_ЭЛЕМЕНТА]ЭЛЕМЕНТЫ. (Естественное соединение) ОТВЕТ(ЭЛЕМЕНТ) = R3[ЭЛЕМЕНТ]. (Проекция таблицы).
На языке SQL такой запрос реализуется одной командой:
SELECT ЭЛЕМЕНТЫ.ЭЛЕМЕНТ
FROM ЭЛЕМЕНТЫ, ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ
WHERE
ЭЛЕМЕНТЫ.НОМ_ЭЛЕМЕНТА=ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ.НОМ_ЭЛЕМЕНТА
AND ХИМИЧЕСКИЙ_СОСТАВ_ВЕЩЕСТВ.ПРОЦЕНТ>90;
Ответом на запрос может быть
Пример 28
| 1 | Иванов | Директор | 1 |
| 2 | Петров | Глав.бухгалтер | 1 |
| 3 | Сидоров | Бухгалтер | 2 |
| 4 | Васильев | Начальник цеха | 1 |
| 5 | Сухов | Мастер | 4 |
| 6 | Шарипов | Рабочий | 5 |
| - | - | - | - |
Таблица 28 Отношение СОТРУДНИКИ
Рассмотрим запрос "Перечислить всех руководителей (прямых и непрямых) данного сотрудника".
Ответом на запрос может быть получен при помощи понятия транзитивного замыкания. Однако транзитивное замыкание не может быть выражено операторами реляционной алгебры.
в виде таблицы, по строкам
Пример 29
| Компьютеры | Январь | 100 |
| Принтеры | Январь | 200 |
| Сканеры | Январь | 300 |
| Компьютеры | Февраль | 150 |
| Принтеры | Февраль | 250 |
| Сканеры | Февраль | 350 |
| - | - | - |
Таблица 29 Данные о продажах
Требуется представить эти данные в виде таблицы, по строкам которой идут наименования товаров, по столбцам - месяцы, а в ячейках содержатся объемы продаж. Это и будет кросс-таблицей:
таблицы средствами реляционной алгебры невозможно,
Пример 30
| Компьютеры | 100 | 150 | - |
| Принтеры | 200 | 250 | - |
| Сканеры | 300 | 350 | - |
Таблица 30 Кросс-таблица
Построение кросс- таблицы средствами реляционной алгебры невозможно, т.к. для этого требуется превратить данные в ячейках таблицы в наименования новых столбцов таблицы.
Пример нарушения целостности базы
Пример нарушения целостности базы
Для иллюстрации возможного нарушения целостности базы данных рассмотрим следующий пример:
Пример 1. Пусть имеется система, в которой хранятся данные о подразделениях и работающих в них сотрудниках. Список подразделений хранится в таблице DEPART(Dep_Id, Dep_Name, Dept_Kol), где Dept_Id - идентификатор подразделения, Dept_Name - наименование подразделения, Dept_Kol - количество сотрудников в подразделении. Список сотрудников хранится в таблице PERSON(Pers_Id, Pers_Name, Dept_Id), где Pers_Id - идентификатор сотрудника, Pers_Name - имя сотрудника, Dept_Id - идентификатор подразделения, в котором работает сотрудник:
Пример разработки простой ERмодели
Пример разработки простой ER-модели
При разработке ER-моделей мы должны получить следующую информацию о предметной области: Список сущностей предметной области. Список атрибутов сущностей. Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия: Хранить информацию о покупателях. Печатать накладные на отпущенные товары. Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса): Покупатель - явный кандидат на сущность. Накладная - явный кандидат на сущность. Товар - явный кандидат на сущность (?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность. (?)Наличие товара v это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями - "покупатели могут покупать много товаров" и "товары могут продаваться многим покупателям". Первый вариант диаграммы выглядит так:

Рис. 7
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада.
Куда поместить сущности "Накладная" и "Склад" и с чем их связать? Спросим себя, как связаны эти сущности между собой и с сущностями "Покупатель" и "Товар"? Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных). Каждый товар, в свою очередь, может быть продан нескольким покупателям через несколько накладных. Кроме того, каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных. Таким образом, после уточнения, диаграмма будет выглядеть следующим образом:

Рис. 8
Пора подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее: Каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты. Каждый товар имеет наименование, цену, а также характеризуется единицами измерения. Каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя. Каждый склад имеет свое наименование. Снова выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем их: Юридическое лицо - термин риторический, мы не работаем с физическими лицами. Не обращаем внимания. Наименование покупателя - явная характеристика покупателя. Адрес - явная характеристика покупателя. Банковские реквизиты - явная характеристика покупателя. Наименование товара - явная характеристика товара. (?)Цена товара - похоже, что это характеристика товара. Отличается ли эта характеристика от цены в накладной? Единица измерения - явная характеристика товара. Номер накладной - явная уникальная характеристика накладной. Дата накладной - явная характеристика накладной. (?)Список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность. (?)Количество товара в накладной - это явная характеристика, но характеристика чего? Это характеристика не просто "товара", а "товара в накладной". (?)Цена товара в накладной - опять же это должна быть не просто характеристика товара, а характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же? Сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную. Наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием "Список товаров в накладной" все довольно ясно. Сущности "Накладная" и "Товар" связаны друг с другом отношением типа много-ко-многим. Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность "Список товаров в накладной". Связь ее с сущностями "Накладная" и "Товар" характеризуется следующими фразами - "каждая накладная обязана иметь несколько записей из списка товаров в накладной", "каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную", "каждый товар может включаться в несколько записей из списка товаров в накладной", " каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром". Атрибуты "Количество товара в накладной" и "Цена товара в накладной" являются атрибутами сущности " Список товаров в накладной".
Точно также поступим со связью, соединяющей сущности "Склад" и "Товар". Введем дополнительную сущность "Товар на складе". Атрибутом этой сущности будет "Количество товара на складе". Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму:

Рис. 9
Примеры использования оператора SELECT
Примеры использования оператора SELECT
Оператор SELECT является фактически самым важным для пользователя и самым сложным оператором SQL. Он предназначен для выборки данных из таблиц, т.е. он, собственно, и реализует одно их основных назначение базы данных - предоставлять информацию пользователю.
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных.
Замечание. На самом деле в базах данных могут быть не только постоянно хранимые таблицы, а также временные таблицы и так называемые представления. Представления - это просто хранящиеся в базе данные SELECT-выражения. С точки зрения пользователей представления - это таблица, которая не хранится постоянно в базе данных, а "возникает" в момент обращения к ней. С точки зрения оператора SELECT и постоянно хранимые таблицы, и временные таблицы и представления выглядят совершенно одинаково. Конечно, при реальном выполнении оператора SELECT системой учитываются различия между хранимыми таблицами и представлениями, но эти различия скрыты от пользователя.
Результатом выполнения оператора SELECT всегда является таблица. Таким образом, по результатам действий оператор SELECT похож на операторы реляционной алгебры. Любой оператор реляционной алгебры может быть выражен подходящим образом сформулированным оператором SELECT. Сложность оператора SELECT определяется тем, что он содержит в себе все возможности реляционной алгебры, а также дополнительные возможности, которых в реляционной алгебре нет.
Примеры использования операторов манипулирования данными
Примеры использования операторов манипулирования данными
Примеры использования реляционных операторов
Примеры использования реляционных операторов
Пример 12. Получить имена поставщиков, поставляющих деталь номер 2.
Решение:

Пример 13. Получить имена поставщиков, поставляющих по крайней мере одну гайку.
Решение:

Ответ на этот запрос можно получить и иначе:

Пример 14. Получить имена поставщиков, поставляющих все детали.
Решение:

Пример 15. Получить имена поставщиков, не поставляющих деталь номер 2.
Решение:

Ответ на этот запрос можно получить и пошагово:







Примеры отношений
Примеры отношений
Примитивные реляционные операторы
Примитивные реляционные операторы
Оставшиеся реляционные операторы (объединение, вычитание, декартово произведение, выборка, проекция) являются примитивными операторами - их нельзя выразить друг через друга.
Проблема несовместимого анализа
Проблема несовместимого анализа
Проблема несовместимого анализа включает несколько различных вариантов: Неповторяемое считывание. Фиктивные элементы (фантомы). Собственно несовместимый анализ.
Проблема несовместимого анализа
Проблема несовместимого анализа
Проблема незафиксированной зависимости (чтение "грязных" данных неаккуратное считывание)
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Транзакция B изменяет данные в строке. После этого транзакция A читает измененные данные и работает с ними. Транзакция B откатывается и восстанавливает старые данные.
Проблема незафиксированной зависимости (чтение "грязных" данных неаккуратное считывание)
Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание)
Транзакция B изменяет данные в строке. После этого транзакция A читает измененные данные и работает с ними. Транзакция B откатывается и восстанавливает старые данные.
Проблема потери результатов обновления
Проблема потери результатов обновления
Две транзакции по очереди записывают некоторые данные в одну и ту же строку и фиксируют изменения.
Проблема потери результатов обновления
Проблема потери результатов обновления
Две транзакции по очереди записывают некоторые данные в одну и ту же строку и фиксируют изменения.
Проблемы параллельной работы транзакций
Проблемы параллельной работы транзакций
Каким образом транзакции различных пользователей могут мешать друг другу? Различают три основные проблемы параллелизма: Проблема потери результатов обновления. Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание). Проблема несовместимого анализа.
Рассмотрим подробно эти проблемы.
Рассмотрим две транзакции, A и B, запускающиеся в соответствии с некоторыми графиками. Пусть транзакции работают с некоторыми объектами базы данных, например со строками таблицы. Операцию чтение строки




Продолжение алгоритма нормализации (приведение к 5НФ)
Продолжение алгоритма нормализации (приведение к 5НФ)
В предыдущей главе был описан алгоритм нормализации как алгоритм приведения отношений к 3НФ. Теперь мы можем продолжить этот алгоритм, доведя его до алгоритма приведения к 5НФ.
Шаг 4 (Приведение к НФБК). Если имеются отношения, содержащие несколько потенциальных ключей, то необходимо проверить, имеются ли функциональные зависимости, детерминанты которых не являются потенциальными ключами. Если такие функциональные зависимости имеются, то необходимо провести дальнейшую декомпозицию отношений. Те атрибуты, которые зависят от детерминантов, не являющихся потенциальными ключами выносятся в отдельное отношение вместе с детерминантами.
Шаг 5 (Приведение к 4НФ). Если в отношениях обнаружены нетривиальные многозначные зависимости, то необходимо провести декомпозицию для исключения таких зависимостей.
Шаг 5 (Приведение к 5НФ). Если в отношениях обнаружены нетривиальные зависимости соединения, то необходимо провести декомпозицию для исключения и таких зависимостей.
Проекция
Проекция
Определение 7. Проекцией отношения









Синтаксис операции проекции:

Замечание. Операция проекции дает "вертикальный срез" отношения, в котором удалены все возникшие при таком срезе дубликаты кортежей.
Пример 7. Пусть дано отношение
Простые типы данных
Простые типы данных
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы: Логический. Строковый. Численный.
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как: Целый. Вещественный. Дата. Время. Денежный. Перечислимый. Интервальный. И т.д.-
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Пушников А Ю
Пушников А.Ю.
Работа транзакций в смеси
Работа транзакций в смеси
Транзакция рассматривается как последовательность элементарных атомарных операций. Атомарность отдельной элементарной операции состоит в том, что СУБД гарантирует, что, с точки зрения пользователя, будут выполнены два условия: Эта операция будет выполнена целиком или не выполнена вовсе (атомарность - все или ничего). Во время выполнения этой операции не выполняются никакие другие операции других транзакций (строгая очередность элементарных операций).
Например, элементарными операциями транзакции будут считывание страницы данных с диска или запись страницы данных на диск (страница данных - это минимальная единица для дисковых операций СУБД). Условие 2 на самом деле является именно логическим условием, т.к. реально система может выполнять несколько различных элементарных операций в один и тот же момент. Например, данные могут храниться на нескольких физически различных дисках и операции чтения-записи на эти диски могут выполняться одновременно.
Элементарные операции различных транзакций могут выполняться в произвольной очередности (конечно, внутри каждой транзакции последовательность элементарных операций этой транзакции является строго определенной). Например, если есть несколько транзакций, состоящих из последовательности операций элементарных:



то реальная последовательность, в которой СУБД выполняет эти транзакции может быть, например, такой:

Определение 1. Набор из нескольких транзакций, элементарные операции которых чередуются друг с другом, называется смесью транзакций.
Определение 2. Последовательность, в которой выполняются элементарные операции заданного набора транзакций, называется графиком запуска набора транзакций.
Замечание. Очевидно, что для заданного набора транзакций может быть несколько (вообще говоря, достаточно много) различных графиков запуска.
Обеспечение изолированности пользователей, таким образом, сводится к выбору подходящего (в каком-то смысле правильного) графика запуска транзакций. Одновременно с этим график запуска должен быть оптимальным в некотором смысле, например, давать минимальное среднее время выполнения транзакций каждым пользователем.
Далее мы уточним понятие "правильного" графика и сделаем некоторые замечания об оптимальности.
Разрешение тупиковых ситуаций
Разрешение тупиковых ситуаций
Итак, при использовании протокола доступа к данным с использованием блокировок часть проблем разрешилось (не все), но возникла новая проблема - тупики: Проблема потери результатов обновления - возник тупик. Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание) - проблема разрешилась. Неповторяемое считывание - проблема разрешилась. Появление фиктивных элементов - проблема не разрешилась. Проблема несовместимого анализа - возник тупик.
Общий вид тупика (dead locks) следующий:
Реализация декларативных ограничений целостности средствами SQL
Реализация декларативных ограничений целостности средствами SQL
Реализация изолированности транзакций средствами SQL
Реализация изолированности транзакций средствами SQL
Реализация реляционной алгебры средствами оператора SELECT (Реляционная полнота SQL)
Реализация реляционной алгебры средствами оператора SELECT (Реляционная полнота SQL)
Для того, чтобы показать, что язык SQL является реляционно полным, нужно показать, что любой реляционный оператор может быть выражен средствами SQL. На самом деле достаточно показать, что средствами SQL можно выразить любой из примитивных реляционных операторов.
Решение проблем параллелизма при помощи блокировок
Решение проблем параллелизма при помощи блокировок
Рассмотрим, как будут себя вести транзакции, вступающие в конфликт при доступе к данным, если они подчиняются протоколу доступа к данным.
Синтаксис ограничений стандарта SQL
Синтаксис ограничений стандарта SQL
Понятие ограничения используется во многих операторах определения данных (DDL).
Ограничение check::=
CHECK Предикат
Ограничения таблицы ::=
[CONSTRAINT Имя ограничения]
{
{PRIMARY KEY (Имя столбца.,..)}
| {UNIQUE (Имя столбца.,..)}
| {FOREIGN KEY (Имя столбца.,..) REFERENCES Имя таблицы [(Имя столбца.,..)] [Ссылочная спецификация]}
| { Ограничение check }
}
[Атрибуты ограничения]
Ограничения столбца::=
[CONSTRAINT Имя ограничения]
{
{NOT NULL}
| {PRIMARY KEY}
| {UNIQUE}
| {REFERENCES Имя таблицы [(Имя столбца)] [Ссылочная спецификация]}
| { Ограничение check }
}
[Атрибуты ограничения]
Ссылочная спецификация::=
[MATCH {FULL | PARTIAL}]
[ON UPDATE {CASCADE | SET NULL | SET DEFAULT | NO ACTION}]
[ON DELETE {CASCADE | SET NULL | SET DEFAULT | NO ACTION}]
Атрибуты ограничения::=
{DEFERRABLE [INITIALLY DEFERRED | INITIALLY IMMEDIATE]}
| {NOT DEFERRABLE}
Ограничение типа CHECK. Ограничение типа CHECK содержит предикат, могущий принимать значения TRUE, FALSE и UNKNOWN (NULL). Примеры предикатов различного вида приведены в главе 5. Ограничение типа CHECK может быть использовано как часть описания домена, таблицы, столбца таблицы или отдельного ограничения целостности - ASSERTION. Ограничение считается нарушенным, если предикат ограничения принимает значение FALSE.
Пример 15. Пример ограничения типа CHECK:
CHECK (Salespeaple.Salary IS NOT NULL) OR (Salespeaple.Commission IS NOT NULL)
Данное ограничение утверждает, что каждый продавец должен иметь либо ненулевую зарплату, либо ненулевые комиссионные.
Пример 16. Еще пример ограничения типа CHECK:
CHECK EXIST(SELECT * FROM Salespeaple)
Данное ограничение утверждает, что список продавцов не может быть пустым.
Ограничения таблицы и ограничения столбца. Ограничения таблицы и ограничения столбца таблицы входят как часть описания соответственно таблицы или столбца таблицы. Ограничение таблицы может относиться к нескольким столбцам таблицы. Ограничение столбца относится только к одному столбцу таблицы. Любое ограничение столбца можно описать как ограничение таблицы, но не наоборот.
Ограничения таблицы или столбца могут иметь наименования, при помощи которого в дальнейшем можно отменять это ограничение или менять время его проверки.
Ограничение PRIMARY KEY. Ограничение PRIMARY KEY для таблицы или столбца означает, что группа из одного или нескольких столбцов образуют потенциальный ключ таблицы. Это означает, что комбинация значений в PRIMARY KEY должна быть уникальной для каждой строки таблицы. Дублированные значения или значения, содержащие NULL, будут отвергнуты. Для одной таблицы может быть определено единственное ограничение PRIMARY KEY. В терминах стандарта SQL это называется первичным ключом таблицы.
Ограничение UNIQUE. Ограничение UNIQUE для таблицы или столбца означает, что группа из одного или нескольких столбцов образуют потенциальный ключ таблицы, в котором допускаются значения NULL. Это означает, что две строки, содержащие одинаковые и не равные NULL-значения, считаются нарушающими уникальность и не допускаются. Две строки, содержащие NULL-значения считаются различными и допускаются. Для одной таблицы может быть определено несколько ограничений UNIQUE.
Замечание. С точки зрения реляционной модели данных (см. главу 3, замечание к правилам целостности сущностей и внешних ключей), ограничение типа UNIQUE не определяет потенциальный ключ, т.к. потенциальный ключ не должен содержать NULL-значений.
Ограничения FOREIGN KEY и REFERENCES. Ограничение FOREIGN KEY- REFERENCES- для таблицы и ограничение REFERENCES- для столбца определяют внешний ключ таблицы. Ограничение REFERENCES- для столбца определяет простой внешний ключ, т.е. ключ, состоящий из одной колонки. Ограничение FOREIGN KEY- REFERENCES- для таблицы может определять как простой, так и сложный внешний ключ, т.е. ключ, состоящий из нескольких колонок таблицы. Столбец или группа столбцов таблицы, на которую ссылается внешний ключ, должна иметь ограничения PRIMARY KEY или UNIQUE. Столбцы, на которые ссылается внешний ключ, должны иметь тот же тип данных, что и столбцы, входящие в состав внешнего ключа. Таблица может иметь ссылку на себя. Ограничение внешнего ключа нарушается, если значения, присутствующие во внешнем ключе, не совпадают со значениями соответствующего ключа родительской таблицы ни для одной строки из родительской таблицы. Операции, приводящие к нарушению ограничения внешнего ключа, отвергаются. Как должны совпадать значения внешнего ключа и ключа родительской таблицы, а также, какие действия необходимо выполнить при изменениях ключей в родительской таблице, описаны ниже в ссылочной спецификации.
Ограничение NOT NULL. Ограничение NOT NULL столбца не допускает появления в столбце NULL-значений.
Ссылочная спецификация. Ссылочная спецификация определяет характеристики внешнего ключа таблицы.
Предложение MATCH {FULL | PARTIAL}. Предложение MATCH FULL требует полного совпадения значений внешнего и первичного ключей. Предложение MATCH PARTIAL допускает частичное совпадение значений внешнего и первичного ключей. Предложение MATCH может быть также пропущенным. Для случая MATCH PARTIAL в дочерней таблице могут появиться строки, имеющие значения внешнего ключа, неуникально совпадающие со значениями родительского ключа. Т.е. одна строка дочерней таблицы может иметь неуникальные ссылки не несколько строк родительской таблицы. Это очень сильно отличается от реляционной модели данных, и это отличие провоцируется допущением NULL-значений. Чтобы рассмотреть различные варианты совпадений внешнего и родительского ключей, рассмотрим следующий пример.
Пример 17. Пусть имеется две таблицы:
Синтаксис оператора выборки
Синтаксис оператора выборки
В довольно сильно упрощенном виде оператор выборки данных имеет следующий синтаксис (для некоторых элементов мы дадим не BNF-определения, а словесное описание):
Оператор выборки ::=
Табличное выражение
[ORDER BY
{{Имя столбца-результата [ASC | DESC]} | {Положительное целое [ASC | DESC]}}.,..];
Табличное выражение ::=
Select-выражение
[
{UNION | INTERSECT | EXCEPT} [ALL]
{Select-выражение | TABLE Имя таблицы | Конструктор значений таблицы}
]
Select-выражение ::=
SELECT [ALL | DISTINCT]
{{{Скалярное выражение | Функция агрегирования | Select-выражение} [AS Имя столбца]}.,..}
| {{Имя таблицы|Имя корреляции}.*}
| *
FROM {
{Имя таблицы [AS] [Имя корреляции] [(Имя столбца.,..)]}
| {Select-выражение [AS] Имя корреляции [(Имя столбца.,..)]}
| Соединенная таблица
}.,..
[WHERE Условное выражение]
[GROUP BY {[{Имя таблицы|Имя корреляции}.]Имя столбца}.,..]
[HAVING Условное выражение]
Замечание. Select-выражение в разделе SELECT, используемое в качестве значения для отбираемого столбца, должно возвращать таблицу, состоящую из одной строки и одного столбца, т.е. скалярное выражение.
Замечание. Условное выражение в разделе WHERE должно вычисляться для каждой строки, являющейся кандидатом в результатирующее множество строк. В этом условном выражении можно использовать подзапросы. Синтаксис условных выражений, допустимых в разделе WHERE рассматривается ниже.
Замечание. Раздел HAVING содержит условное выражение, вычисляемое для каждой группы, определяемой списком группировки в разделе GROUP BY. Это условное выражение может содержать функции агрегирования, вычисляемые для каждой группы. Условное выражение, сформулированное в разделе WHERE, может быть перенесено в раздел HAVING. Перенос условий из раздела HAVING в раздел WHERE невозможен, если условное выражение содержит агрегатные функции. Перенос условий из раздела WHERE в раздел HAVING является плохим стилем программирования - эти разделы предназначены для различных по смыслу условий (условия для строк и условия для групп строк).
Замечание. Если в разделе SELECT присутствуют агрегатные функции, то они вычисляются по-разному в зависимости от наличия раздела GROUP BY. Если раздел GROUP BY отсутствует, то результат запроса возвращает не более одной строки. Агрегатные функции вычисляются по всем строкам, удовлетворяющим условному выражению в разделе WHERE. Если раздел GROUP BY присутствует, то агрегатные функции вычисляются по отдельности для каждой группы, определенной в разделе GROUP BY.
Скалярное выражение - в качестве скалярных выражений в разделе SELECT могут выступать либо имена столбцов таблиц, входящих в раздел FROM, либо простые функции, возвращающие скалярные значения.
Функция агрегирования ::=
COUNT (*) |
{
{COUNT | MAX | MIN | SUM | AVG} ([ALL | DISTINCT] Скалярное выражение)
}
Конструктор значений таблицы ::=
VALUES Конструктор значений строки.,..
Конструктор значений строки ::=
Элемент конструктора | (Элемент конструктора.,..) | Select-выражение
Замечание. Select-выражение, используемое в конструкторе значений строки, обязано возвращать ровно одну строку.
Элемент конструктора ::=
Выражение для вычисления значения | NULL | DEFAULT
Синтаксис оператора выборки данных (SELECT)
Синтаксис оператора выборки данных (SELECT)
Синтаксис операторов SQL использующих ограничения
Синтаксис операторов SQL, использующих ограничения
Стандарт SQL описывает следующие операторы, в которых может быть использованы ограничения: CREATE DOMAIN - создать домен ALTER DOMAIN - изменить домен DROP DOMAIN - удалить домен CREATE TABLE - создать таблицу ALTER TABLE - изменить таблицу DROP TABLE - удалить таблицу CREATE ASSERTION - создать утверждение DROP ASSERTION - удалить утверждение COMMIT WORK - зафиксировать транзакцию SET CONSTRAINTS - установить момент проверки ограничений
CREATE DOMAIN Имя домена [AS] Тип данных
[DEFAULT Значение по умолчанию]
[Имя ограничения] Ограничение check [Атрибуты ограничения]
Этот оператор задает домен, на основе которого можно определять колонки таблиц. Т.к. имя колонки, которая будет основана на этом домене заранее неизвестно, то в ограничении CHECK домена для ссылки на значение этого домена используется ключевое слово VALUE. В конкретной таблице СУБД заменит слово VALUE на имя колонки таблицы.
Пример 18. Приведенный ниже оператор создает домен Salary на основе целочисленного типа данных, причем значения из этого домена не могут принимать неположительные значения (но могут принимать значение NULL!). По умолчанию это ограничение проверяется немедленно, но может быть и отложенным: CREATE DOMAIN Salary AS integer CHECK (VALUE > 0) DEFERRABLE INITIALLY IMMEDIATE
ALTER DOMAIN Имя домена
{SET DEFAULT Значение по умолчанию}
| {DROP DEFAULT}
| {ADD [Имя ограничения] Ограничение check [Атрибуты ограничения]}
| {DROP CONSTRAINT Имя ограничения}
Этот оператор изменяет имеющийся домен. Стандарт запрещает вносить несколько изменений одной командой ALTER DOMAIN. Т.е. если требуется удалить ограничение CHECK и добавить значение по умолчанию, то придется выполнить два оператора ALTER DOMAIN.
DROP DOMAIN Имя домена CASCADE | RESTRICT
Этот оператор уничтожает имеющийся домен. Если указана опция RESTRICT, то домен не уничтожается, если имеются ссылки на него из столбцов таблиц. Если указана опция CASCADE, то происходят следующие действия: Тип данных домена передается столбцам, основанным на этом домене. Если столбец не имеет значения по умолчанию, а для домена значение по умолчанию определено, то оно становится значением по умолчанию для столбца. Все ограничения домена становятся ограничениями столбца.
CREATE TABLE Имя таблицы
( {Определение столбца | [Ограничение таблицы]}.,..)
Определение столбца::=
Имя столбца {Имя домена | Тип данных [Размер]}
[Ограничение столбца-]
[DEFAULT Значение по умолчанию]
Этот оператор (синтаксис приведен не полностью - пропущены опции создания временных таблиц) создает таблицу базы данных. В таблице обязано быть не менее одного определения столбца. В таблице может быть определено несколько ограничений (в том числе и ни одного).
Каждый столбец должен иметь имя и быть определен на некотором типе данных или на некотором домене. Ограничения домена становятся ограничениями столбца. Кроме того, столбец может иметь дополнительные ограничения. Если домен имеет значение по умолчанию и в определении столбца определено значение по умолчанию, то значение для столбца перекрывает значение для домена.
Пример 19. CREATE TABLE Salespeaple (Salespeaple_Id Id_Nums PRIMARY KEY, Fam CHAR(20) NOT NULL, Im CHAR(15), BirthDate DATE, Salary Salary_Domain DEFAULT 1000, City_Id INTEGER REFERENCES City ON UPDATE CASCADE ON DELETE RESTRICT, District_Id INTEGER, CONSTRAINT AltKey UNIQUE(Fam, Im, BirthDate), CHECK (City_Id IS NOT NULL OR District_Id IS NOT NULL), FOREIN KEY District_Id REFERENCES District ON UPDATE CASCADE ON DELETE RESTRICT)
Этот оператор создает таблицу Salespeaple с колонками (Salespeaple_Id, Fam, Im, BirthDate, Salary, City_Id, District_Id) и следующими ограничениями: Колонка Salespeaple_Id наследует все ограничения домена Id_Nums. Кроме того, эта колонка образует первичный ключ таблицы (следовательно, не допускает NULL-значений). Колонка Fam не допускает NULL-значений. Колонка Salary наследует все ограничения домена Salary_Domain. Кроме того, эта колонка имеет значения по умолчанию1000. Колонка City_Id является внешним ключом, ссылающимся на первичный ключ таблицы City. При изменении первичного ключа в таблице City соответствующие значения внешнего ключа в таблице Salespeaple будут каскадно изменены. При удалении строки из таблицы City будет выполняться проверка, нет ли ссылок на удаляемую строку из таблицы Salespeaple. Если такие ссылки найдутся, то операция удаления в таблице City будет отвергнута. Колонка District_Id также является внешним ключом, ссылающимся на первичный ключ таблицы District. Этот внешний ключ, в отличие от предыдущего, определен как ограничение таблицы. Действия, определенные по ссылке аналогичны предыдущим. Колонки (Fam, Im, BirthDate) образуют альтернативный ключ таблицы. Это ограничение имеет наименование AltKey. Колонки City_Id и District_Id не могут одновременно принимать NULL-значения (хотя каждая из них по отдельности допускает использование NULL-значений).
ALTER TABLE Имя таблицы
{ADD [COLUMN] Определение столбца}
| {ALTER [COLUMN] Имя столбца {SET DEFAULT Значение по умолчанию | DROP DEFAULT}}
| {DROP [COLUMN] Имя столбца RESTRICT | CASCADE}
| {ADD Ограничение таблицы}
| {DROP CONSTRAINT Имя ограничения RESTRICT | CASCADE}
Этот оператор позволяет изменять имеющуюся таблицу. В таблице можно удалять или добавлять колонки и/или ограничения. Кроме того, для колонок можно менять значение по умолчанию.
DROP TABLE Имя таблицы CASCADE | RESTRICT
Этот оператор позволяет удалять имеющуюся таблицу. Вместе с таблицей удаляются и ограничения, определенные для этой таблицы.
Если указан параметр RESTRICT, то таблица удаляется только если нет никаких ссылок на эту таблицу в других ограничениях или представлениях.
Если указан параметр CASCADE, то удаляются также и все объекты, ссылающиеся на эту таблицу.
CREATE ASSERTION Имя утверждения
Ограничение check
[Атрибуты ограничения]
Этот оператор позволяет создавать утверждения - т.е. ограничения, не являющиеся частью определения домена, колонки или таблицы.
Предикат CHECK, входящий в определение утверждения, может быть достаточно сложным и содержать ссылки на несколько таблиц.
Пример 20. CREATE ASSERTION Check_Pay CHECK (Salespeaple.Salary IS NOT NULL) OR (Salespeaple.Commission IS NOT NULL) DEFERRABLE INITIALLY IMMEDIATE
DROP ASSERTION Имя утверждения
Этот оператор позволяет удалять имеющееся утверждение.
COMMIT WORK
Этот оператор фиксирует транзакцию. При этом проверяются все отложенные до конца транзакции ограничения. Если одно из ограничений не выполняется, то транзакция откатывается.
SET CONSTRAINT {Имя ограничения.,.. | ALL}
{DEFERRED | IMMEDIATE}
Этот оператор позволяет во время выполнения транзакции менять момент проверки всех (ALL) или некоторых ограничений. Этот оператор действует только на ограничения, определенные как DEFERRABLE (потенциально откладываемые). Если ограничение A находилось в состоянии IMMEDIATE (немедленно проверяемое), то оператор SET CONSTRAINT A DEFERRED переводит его в состояние DEFERRED (с отложенной проверкой) и тогда все операции, потенциально могущие нарушить это ограничение, будут выполняться без проверки. Проверка будет произведена в конце транзакции или в момент подачи команды SET CONSTRAINT A IMMEDIATE.
Синтаксис операторов SQL определяющих уровни изоляции
Синтаксис операторов SQL, определяющих уровни изоляции
Уровень изоляции транзакции задается следующим оператором:
SET TRANSACTION {ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE} | {READ ONLY | READ WRITE}}.,..
Этот оператор определяет режим выполнения следующей транзакции, т.е. этот оператор не влияет на изменение режима той транзакции, в которой он подается. Обычно, выполнение оператора SET TRANSACTION выделяется как отдельная транзакция: - (предыдущая транзакция выполняется со своим уровнем изоляции) COMMIT; SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; COMMIT; - (следующая транзакция выполняется с уровнем изоляции REPEATABLE READ)
Если задано предложение ISOLATION LEVEL, то за ним должно следовать один из параметров, определяющих уровень изоляции.
Кроме того, можно задать признаки READ ONLY или READ WRITE. Если указан признак READ ONLY, то предполагается, что транзакция будет только читать данные. При попытке записи для такой транзакции будет сгенерирована ошибка. Признак READ ONLY введен для того, чтобы дать производителям СУБД возможность уменьшать количество блокировок путем использования других методов сериализации (например, метод выделения версий).
Оператор SET TRANSACTION должен удовлетворять следующим условиям: Если предложение ISOLATION LEVEL отсутствует, то по умолчанию принимается уровень SERIALIZABLE. Если задан признак READ WRITE, то параметр ISOLATION LEVEL не может принимать значение READ UNCOMMITTED. Если параметр ISOLATION LEVEL определен как READ UNCOMMITTED, то транзакция становится по умолчанию READ ONLY. В противном случае по умолчанию транзакция считается как READ WRITE.
Синтаксис соединенных таблиц
Синтаксис соединенных таблиц
В разделе FROM оператора SELECT можно использовать соединенные таблицы. Пусть в результате некоторых операций мы получаем таблицы A и B. Такими операциями могут быть, например, оператор SELECT или другая соединенная таблица. Тогда синтаксис соединенной таблицы имеет следующий вид:
Соединенная таблица ::=
Перекрестное соединение
| Естественное соединение
| Соединение посредством предиката
| Соединение посредством имен столбцов
| Соединение объединения
Тип соединения ::=
INNER
| LEFT [OUTER]
| RIGTH [OUTER]
| FULL [OUTER]
Перекрестное соединение ::=
Таблица А CROSS JOIN Таблица В
Естественное соединение ::=
Таблица А [NATURAL] [Тип соединения] JOIN Таблица В
Соединение посредством предиката ::=
Таблица А [Тип соединения] JOIN Таблица В ON Предикат
Соединение посредством имен столбцов ::=
Таблица А [Тип соединения] JOIN Таблица В USING (Имя столбца.,..)
Соединение объединения ::=
Таблица А UNION JOIN Таблица В
Опишем используемые термины.
CROSS JOIN - Перекрестное соединение возвращает просто декартово произведение таблиц. Такое соединение в разделе FROM может быть заменено списком таблиц через запятую.
NATURAL JOIN - Естественное соединение производится по всем столбцам таблиц А и В, имеющим одинаковые имена. В результатирующую таблицу одинаковые столбцы вставляются только один раз.
JOIN - ON - Соединение посредством предиката соединяет строки таблиц А и В посредством указанного предиката.
JOIN - USING - Соединение посредством имен столбцов соединяет отношения подобно естественному соединению по тем общим столбцам таблиц А и Б, которые указаны в списке USING.
OUTER - Ключевое слово OUTER (внешний) не является обязательными, оно не используется ни в каких операциях с данными.
INNER - Тип соединения "внутреннее". Внутренний тип соединения используется по умолчанию, когда тип явно не задан. В таблицах А и В соединяются только те строки, для которых найдено совпадение.
LEFT (OUTER) - Тип соединения "левое (внешнее)". Левое соединение таблиц А и В включает в себя все строки из левой таблицы А и те строки из правой таблицы В, для которых обнаружено совпадение. Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL.
RIGHT (OUTER) - Тип соединения "правое (внешнее)". Правое соединение таблиц А и В включает в себя все строки из правой таблицы В и те строки из левой таблицы А, для которых обнаружено совпадение. Для строк из таблицы В, для которых не найдено соответствия в таблице А, в столбцы, извлекаемые из таблицы А заносятся значения NULL.
FULL (OUTER) - Тип соединения "полное (внешнее)". Это комбинация левого и правого соединений. В полное соединение включаются все строки из обеих таблиц. Для совпадающих строк поля заполняются реальными значениями, для несовпадающих строк поля заполняются в соответствии с правилами левого и правого соединений.
UNION JOIN - Соединение объединения является обратным по отношению к внутреннему соединению. Оно включает только те строки из таблиц А и В, для которых не найдено совпадений. В них используются значения NULL для столбцов, полученных из другой таблицы. Если взять полное внешнее соединение и удалить из него строки, полученные в результате внутреннего соединения, то получится соединение объединения.
Использование соединенных таблиц часто облегчает восприятие оператора SELECT, особенно, когда используется естественное соединение. Если не использовать соединенные таблицы, то при выборе данных из нескольких таблиц необходимо явно указывать условия соединения в разделе WHERE. Если при этом пользователь указывает сложные критерии отбора строк, то в разделе WHERE смешиваются семантически различные понятия - как условия связи таблиц, так и условия отбора строк (см. примеры 13, 14, 15 данной главы).
Синтаксис условных выражений раздела WHERE
Синтаксис условных выражений раздела WHERE
Условное выражение, используемое в разделе WHERE оператора SELECT должно вычисляться для каждой строки-кандидата, отбираемой оператором SELECT. Условное выражение может возвращать одно из трех значений истинности: TRUE, FALSE или UNKNOUN. Строка-кандидат отбирается в результатирующее множество строк только в том случае, если для нее условное выражение вернуло значение TRUE.
Условные выражения имеют следующий синтаксис (в целях упрощения изложения приведены не все возможные предикаты):
Условное выражение ::=
[ ( ] [NOT]
{Предикат сравнения
| Предикат between
| Предикат in
| Предикат like
| Предикат null
| Предикат количественного сравнения
| Предикат exist
| Предикат unique
| Предикат match
| Предикат overlaps}
[{AND | OR} Условное выражение] [ ) ]
[IS [NOT] {TRUE | FALSE | UNKNOWN}]
Предикат сравнения ::=
Конструктор значений строки {= | < | > | <= | >= | <>} Конструктор значений строки
Пример 33. Сравнение поля таблицы и скалярного значения: POSTAV.VOLUME > 100
Пример 34. Сравнение двух сконструированных строк: (PD.PNUM, PD.DNUM) = (1, 25)
Этот пример эквивалентен условному выражению PD.PNUM = 1 AND PD.DNUM = 25
Предикат between ::=
Конструктор значений строки [NOT] BETWEEN
Конструктор значений строки AND Конструктор значений строки
Пример 35. PD.VOLUME BETWEEN 10 AND 100
Предикат in ::=
Конструктор значений строки [NOT] IN
{(Select-выражение) | (Выражение для вычисления значения.,..)}
Пример 36. P.PNUM IN (SELECT PD.PNUM FROM PD WHERE PD.DNUM=2)
Пример 37. P.PNUM IN (1, 2, 3, 5)
Предикат like ::=
Выражение для вычисления значения строки-поиска [NOT] LIKE
Выражение для вычисления значения строки-шаблона [ESCAPE Символ]
Замечание. Предикат LIKE производит поиск строки-поиска в строке-шаблоне. В строке-шаблоне разрешается использовать два трафаретных символа: Символ подчеркивания "_" может использоваться вместо любого единичного символа в строке-поиска, Символ процента "%" может заменять набор любых символов в строке-поиска (число символов в наборе может быть от 0 и более).
Предикат null ::=
Конструктор значений строки IS [NOT] NULL
Замечание. Предикат NULL применяется специально для проверки, не равно ли проверяемое выражение null-значению.
Предикат количественного сравнения ::=
Конструктор значений строки {= | < | > | <= | >= | <>}
{ANY | SOME | ALL} (Select-выражение)
Замечание. Кванторы ANY и SOME являются синонимами и полностью взаимозаменяемы.
Замечание. Если указан один из кванторов ANY и SOME, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает хотя бы с одним значением, возвращаемом в подзапросе (select-выражении).
Замечание. Если указан квантор ALL, то предикат количественного сравнения возвращает TRUE, если сравниваемое значение совпадает с каждым значением, возвращаемом в подзапросе (select-выражении).
Пример 38. P.PNUM = SOME (SELECT PD.PNUM FROM PD WHERE PD.DNUM=2)
Предикат exist ::=
EXIST (Select-выражение)
Замечание. Предикат EXIST возвращает значение TRUE, если результат подзапроса (select-выражения) не пуст.
Предикат unique ::=
UNIQUE (Select-выражение)
Замечание. Предикат UNIQUE возвращает TRUE, если в результате подзапроса (select-выражения) нет совпадающих строк.
Предикат match ::=
Конструктор значений строки MATCH [UNIQUE]
[PARTIAL | FULL] (Select-выражение)
Замечание. Предикат MATCH проверяет, будет ли значение, определенное в конструкторе строки совпадать со значением любой строки, полученной в результате подзапроса.
Предикат overlaps ::=
Конструктор значений строки OVERLAPS Конструктор значений строки
Замечание. Предикат OVERLAPS, является специализированным предикатом, позволяющем определить, будет ли указанный период времени перекрывать другой период времени.
Скорость операций обновления данных (вставка обновление удаление)
Скорость операций обновления данных (вставка, обновление, удаление)
На уровне логического моделирования мы определяем реляционные отношения и атрибуты этих отношений. На этом уровне мы не можем определять какие-либо физические структуры хранения (индексы, хеширование и т.п.). Единственное, чем мы можем управлять - это распределением атрибутов по различным отношениям. Можно описать мало отношений с большим количеством атрибутов, или много отношений, каждое из которых содержит мало атрибутов. Таким образом, необходимо попытаться ответить на вопрос - влияет ли количество отношений и количество атрибутов в отношениях на скорость выполнения операций обновления данных. Такой вопрос, конечно, не является достаточно корректным, т.к. скорость выполнения операций с базой данных сильно зависит от физической реализации базы данных. Тем не менее, попытаемся качественно оценить это влияние при одинаковых подходах к физическому моделированию.
Основными операциями, изменяющими состояние базы данных, являются операции вставки, обновления и удаления записей. В базах данных, требующих постоянных изменений (складской учет, системы продаж билетов и т.п.) производительность определяется скоростью выполнения большого количества небольших операций вставки, обновления и удаления.
Рассмотрим операцию вставки записи в таблицу. Вставка записи производится в одну из свободных страниц памяти, выделенной для данной таблицы. СУБД постоянно хранит информацию о наличии и расположении свободных страниц. Если для таблицы не созданы индексы, то операция вставки выполняется фактически с одинаковой скоростью независимо от размера таблицы и от количества атрибутов в таблице. Если в таблице имеются индексы, то при выполнении операции вставки записи индексы должны быть перестроены. Таким образом, скорость выполнения операции вставки уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Рассмотрим операции обновления и удаления записей из таблицы. Прежде, чем обновить или удалить запись, ее необходимо найти. Если таблица не индексирована, то единственным способом поиска является последовательное сканирование таблицы в поиске нужной записи. В этом случае, скорость операций обновления и удаления существенно увеличивается с увеличением количества записей в таблице и не зависит от количества атрибутов. Но на самом деле неиндексированные таблицы практически никогда не используются. Для каждой таблицы обычно объявляется один или несколько индексов, соответствующий потенциальным ключам. При помощи этих индексов поиск записи производится очень быстро и практически не зависит от количества строк и атрибутов в таблице (хотя, конечно, некоторая зависимость имеется). Если для таблицы объявлено несколько индексов, то при выполнении операций обновления и удаления эти индексы должны быть перестроены, на что тратится дополнительное время. Таким образом, скорость выполнения операций обновления и удаления также уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Можно предположить, что чем больше атрибутов имеет таблица, тем больше для нее будет объявлено индексов. Эта зависимость, конечно, не прямая, но при одинаковых подходах к физическому моделированию обычно так и происходит. Таким образом, можно принять допущение, что чем больше атрибутов имеют отношения, разработанные в ходе логического моделирования, тем медленнее будут выполняться операции обновления данных, за счет затраты времени на перестройку большего количества индексов.
Дополнительные соображения в пользу приведенного тезиса о замедлении выполнения операций обновления данных (влияние журнализации, длины строк таблиц) приведены в работе А.Прохорова [27].
Скорость операций выборки данных
Скорость операций выборки данных
Одно из назначений базы данных - предоставление информации пользователям. Информация извлекается из реляционной базы данных при помощи оператора SQL - SELECT. Одной из наиболее дорогостоящих операций при выполнении оператора SELECT является операция соединение таблиц. Таким образом, чем больше взаимосвязанных отношений было создано в ходе логического моделирования, тем больше вероятность того, что при выполнении запросов эти отношения будут соединяться, и, следовательно, тем медленнее будут выполняться запросы. Таким образом, увеличение количества отношений приводит к замедлению выполнения операций выборки данных, особенно, если запросы заранее неизвестны.
Собственно несовместимый анализ
Собственно несовместимый анализ
Эффект собственно несовместимого анализа также отличается от предыдущих примеров тем, что в смеси присутствуют две транзакции - одна длинная, другая короткая.
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
Собственно несовместимый анализ
Собственно несовместимый анализ
Длинная транзакция выполняет некоторый анализ по всей таблице, например, подсчитывает общую сумму денег на счетах клиентов банка для главного бухгалтера. Пусть на всех счетах находятся одинаковые суммы, например, по $100. Короткая транзакция в этот момент выполняет перевод $50 с одного счета на другой так, что общая сумма по всем счетам не меняется.
Соединение
Соединение
Операция соединения отношений, наряду с операциями выборки и проекции, является одной из наиболее важных реляционных операций.
Обычно рассматривается несколько разновидностей операции соединения: Общая операция соединения

Наиболее важным из этих частных случаев является операция естественного соединения. Все разновидности соединения являются частными случаями общей операции соединения.
Специальные реляционные операторы
Специальные реляционные операторы
Список литературы
Список литературы
Атре Ш. Структурный подход к организации баз данных. - М.: Финансы и статистика, 1983. - 320 с. Беренсон Х., Бернштейн Ф., Грэй Д., Мелтон Д., О"Нил Э., О"Нил П. Критика уровней изолированности в стандарте ANSI SQL //СУБД. - 1996. - ¦2. - С.45-60. Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. - М.: Финансы и стати-стика, 1989. - 351 с. Боуман Д, Эмерсон С., Дарновски М. Практическое руководство по SQL. - Киев: Диалектика, 1997. Васкевич Д. Стратегии клиент/сервер. - Киев: Диалектика, 1997. Гилуа М.М. Множественная модель данных в информационных системах. - М.: Наука, 1992. Голосов А.О. Аномалии в реляционных базах данных //СУБД. - 1986. - ¦3. - С.23-28. Грабер М. Введение в SQL. - М.: Лори, 1996. - 379 с. Грабер М. Справочное руководство по SQL. - М.: Лори, 1997. - 291 с. Дейт К. Руководство по реляционной СУБД DB2. - М.: Финансы и статистика, 1988. - 320 с. Дейт К. Введение в системы баз данных //6-издание. - Киев: Диалектика, 1998. - 784 с. Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ. - М.: Мир, 1991. - 252 с. Диго С.М. Проектирование и использование баз данных. - М.: Финансы и статистика, 1995. - 208 с. Злуф М.М. Query-by-Example: язык баз данных //СУБД. - 1996. - ¦3. - С.149-160. Кириллов В.В. Структуризованный язык запросов (SQL). - СПб.: ИТМО, 1994. - 80 с. Кузнецов С.Д. Введение в системы управления базами данных //СУБД. - 1995. - ¦1,2,3,4, 1996. - ¦1,2,3,4,5. Кузнецов С.Д. Стандарты языка реляционных баз данных SQL: краткий обзор //СУБД. - 1996. - ¦2. - С.6-36. Кузнецов С.Д. Операционные системы для управления базами данных //СУБД. - 1996. - ¦3. - С.95-102. Кузнецов С.Д. Дубликаты, неопределенные значения, первичные и возможные ключи и другие экзотиче-ские прелести языка SQL //СУБД. - 1997. - ¦3. - С.77-80. Кузнецов С.Д. Неопределенная информация и трехзначная логика //СУБД. - 1997. - ¦5. - С.65-67. Ладыженский Г.М. Системы управления базами данных - коротко о главном //СУБД. - 1995. - ¦1,2,3,4. Мартин Д. Планирование развития автоматизированных систем. - М.: Финансы и статистика, 1984. - 196 с. Мейер М. Теория реляционных баз данных. - М.: Мир, 1987. - 608 с. Оззу М.Т., Валдуриз П. Распределенные и параллельные системы баз данных //СУБД. - 1996. - ¦4. - С.4-26. Озкарахан Э. Машины баз данных и управление базами данных. - М.: Мир, 1989. Пржиялковский В. В. Абстракции в проектировании БД //СУБД. - 1998. - ¦1. - С.90-97. Прохоров А, Определение оптимальной структуры базы данных //Informix magazine. Русское издание. - 1998. - Апрель. Нагао М., Катаяма Т., Уэмура С. Структуры и базы данных. - М.: Мир, 1986. - 197 с. Тиори Т., Фрай Д. Проектирование структур баз данных. В 2 кн., - М.: Мир, 1985. Кн. 1. - 287 с.: Кн. 2. - 320 с. Ульман Д. Основы систем баз данных. - М.: Финансы и статистика, 1983. - 334 с. Ульман Д. Базы данных на Паскале. - М.: Машиностроение, 1990. - 386 с. Хаббард Д. Автоматизированное проектирование баз данных. - М.: Мир, 1984. - 294 с. Цаленко М.Ш. Моделирование семантики в базах данных. - М.: Наука, 1988. Цикритизис Д., Лоховски Ф. Модели данных. - М.: Финансы и статистика, 1985. - 344 с. Чамберлин Д.Д., Астрахан М.М., Эсваран К.П., Грифитс П.П., Лори Р.А., Мел Д.В., Райшер П., Вейд Б.В. SEQUEL 2: унифицированный подход к определению, манипулированию и контролю данных //СУБД. - 1996. - ¦1. - С.144-159. Чаудхари С. Методы оптимизации запросов в реляционных системах //СУБД. - 1998. - ¦3. - С.22-36. Чен П. Модель "сущность-связь" - шаг к единому представлению о данных //СУБД. - 1995. - ¦3. - С.137-158. ANSI X3.135-1992, American National Standart for Information Systems - Database Language - SQL, November, 1992. Astrahan M.M., System R: A Relational Approach to Data Base Management //ACM Transactions on Data Base Systems. - 1976. - V1, 97, June. Boyce R.F., Chamberlin D.D., King W.F., Hammer M.M. Specifying Queries as Relational Expressions: The SQUARE Data Sublanguage //Communications ACM. - 1975. V.18, November. - P.621. Chamberlin D.D., Raymond F.B. SEQUEL: A Structured English Query Language. //Proc. ACM-SIGMOD. - 1974. - Workshop, Ann Arbor, Michigan, May. Chamberlin D.D., Gray J.N., Traiger L.L. Views, Authorization and Locking in a Relational Data Base System //Proceedings of AFIPS National Computer Conference, Anaheim, CA, May. - 1975. Codd E.F. Relation Model of Data for Large Shared Data Banks //Comm. ACM. - 1970. - V.13, ¦.6. - P.377-383. (Имеется перевод: Кодд Е.Ф. Реляционная модель данных для больших совместно используемых банков данных //СУБД. - 1995. - ¦1. - С.145-160.) Codd E.F. Normalized Data Base Structure: A Brief Tutorial //Proc. of 1971 ACM-SIGFIDET Workshop on Data Description, Access and Control.- N.-Y.: ACM. - 1971. - P.1-17. Codd E.F. A data base sublanguage founded on the relational calculus //Proc. ACM-SIGFIDET/ - 1971. - Workshop, San Diego, Calif., Nov. P.35-68. Codd E.F. Further Normalization of the Data base Relational Model //Data Base Systems.- N.J.: Prentice-Hall, 1972. - P.33-64. Codd E.F. Recent investigations in relational data base systems //Proc. IFIP Congress. - 1974. - North-Holland Pub. Co., Amsterdam. - P.1017-1021. Codd E.F. Extending the Database Relation Model to Capture More Meaning. //ACM Transaction on Database Systems. 1979.- V.4, ¦4. - P.397-434. (Имеется перевод: Кодд Э.Ф. Расширение реляционной модели для лучщего отражения семантики //СУБД. - 1996. - ¦5-6. - С.163-192.) Eswaran K.P. Chamberlin D.D. Functional specifications of a subsystem for data base integrity //Proc. Very Large Data Base Conf., Framingham, Mass., Sept. - 1975. - P.48-68. Eswaran K.P., Gray J.N., Lorie R.A., Traiger I.L. The Notions of Consistency and Predicate Locks in a Data Base System //CACM. - 1976. - V.19, ¦11. Fagin R.A. Normal Form for Relational Databases That is Based on Domains and Key //ACM Transactions on Database Systems. - 1981. - V.6, ¦3. - P.387-415. Fagin R. Multivalued Dependencies and New Normal Form for Relational Databases //ACM TODS. - 1977. - V.2, ¦3. Gray J., Lorie R., Putzolu G., Traiger I. Granularity of Locks and Degrees of Consistency in a Shared Data Base //in Readings in Database Systems, Second Edition, Chapter 3, Michael Stonebraker, Ed., Morgan Kaufmann. - 1994. Heath I.J. Unacceptable File Operations in Relational Database //Proc. 1971 ACM SIGFIDET Workshop on Data Description, Access, and Control. - San Diego, Calif. - 1971. Held G.D., Stonebraker M.R., Wong E. INGRES: A Relational Data Base System //Proceedings of AFIPS National Computer Conference, Anaheim, CA, May. - 1975. Meiton J., Simon A.R. Understanding The New SQL: A Comlete Guide //Morgan Kaufmann. - 1993. Reisner P., Boyce R.F., Chamberlin D.D. Human Factors Evaluation of Two Data Base Query Languages: SQUARE and SEQUEL //Proceedings of AFIPS National ComputerConference, Anaheim, CA, May. - 1975. Smith J.M., Smith D.C. Database Abstractions: Aggregation and Generalization. //ACM Transactions on Database Systems. - 1977. - V.2, ¦2, June.- P.105-133. (Имеется перевод: Смит Д.М., Смит Д.К. Абстракции баз дан-ных: Агрегация и обобщение //СУБД. - 1996. - ¦2. - С.141-160.) Zloof M.M. Query By Example //Proceedings of AFIPS National Computer Conference, Anaheim, CA, May. - 1975.
Сравнение нормализованных и ненормализованных моделей
Сравнение нормализованных и ненормализованных моделей
Соберем воедино результаты анализа критериев, по которым мы хотели оценить влияние логического моделирования данных на качество физических моделей данных и производительность базы данных:
Ссылочные типы данных
Ссылочные типы данных
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
Стадия 1 Выполнение одиночного оператора SELECT
Стадия 1. Выполнение одиночного оператора SELECT
Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM). Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE). Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY). Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING). Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT). Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2 Выполнение операций UNION EXCEPT INTERSECT
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3 Упорядочение результата
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Стратегии поддержания ссылочной целостности
Стратегии поддержания ссылочной целостности
Существуют две основные стратегии поддержания ссылочной целостности: RESTRICT (ОГРАНИЧИТЬ)- не разрешать выполнение операции, приводящей к нарушению ссылочной целостности. Это самая простая стратегия, требующая только проверки, имеются ли кортежи в дочернем отношении, связанные с некоторым кортежем в родительском отношении. CASCADE (КАСКАДИРОВАТЬ)- разрешить выполнение требуемой операции, но внести при этом необходимые поправки в других отношениях так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи. Изменение начинается в родительском отношении и каскадно выполняется в дочернем отношении. В реализации этой стратегии имеется одна тонкость, заключающаяся в том, что дочернее отношение само может быть родительским для некоторого третьего отношения. При этом может дополнительно потребоваться выполнение какой-либо стратегии и для этой связи и т.д. Если при этом какая-либо из каскадных операций (любого уровня) не может быть выполнена, то необходимо отказаться от первоначальной операции и вернуть базу данных в исходное состояние. Это самая сложная стратегия, но она хороша тем, что при этом не нарушается связь между кортежами родительского и дочернего отношений.
Эти стратегии являются стандартными и присутствуют во всех СУБД, в которых имеется поддержка ссылочной целостности.
Можно рассмотреть дополнительные стратегии поддержания ссылочной целостности: SET NULL (УСТАНОВИТЬ В NULL) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на null-значения. Эта стратегия имеет два недостатка. Во-первых, для нее требуется допустить использование null-значений. Во-вторых, кортежи дочернего отношения теряют всякую связь с кортежами родительского отношения. Установить, с каким кортежем родительского отношения были связаны измененные кортежи дочернего отношения, после выполнения операции уже нельзя. SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - разрешить выполнение требуемой операции, но все возникающие некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию. Достоинство этой стратегии по сравнению с предыдущей в том, что она позволяет не пользоваться null-значеними. Недостатки заключаются в следующем. Во-первых, в родительском отношении должен быть некий кортеж, потенциальный ключ которого принят как значение по умолчанию для внешних ключей. В качестве такого "кортежа по умолчанию" обычно принимают специальный кортеж, заполненный нулевыми значениями (не null-значениями!). Этот кортеж нельзя удалять из родительского отношения, и в этом кортеже нельзя изменять значение потенциального ключа. Таким образом, не все кортежи родительского отношения становятся равнозначными, поэтому приходится прилагать дополнительные усилия для отслеживания этой неравнозначности. Это плата за отказ от использования null-значений. Во-вторых, как и в предыдущем случае, кортежи дочернего отношения теряют всякую связь с кортежами родительского отношения. Установить, с каким кортежем родительского отношения были связаны измененные кортежи дочернего отношения, после выполнения операции уже нельзя.
В некоторых реализация СУБД рассматривается еще одна стратегия поддержания ссылочной целостности: IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
Конечно, это не стратегия, а отказ от поддержки ссылочной целостности. В этом случае в дочернем отношении могут появляться некорректные значения внешних ключей, и вся ответственность за целостность базы данных ложится на пользователя.
В дополнение к приведенным стратегиям пользователь может придумать свою уникальную стратегию поддержания ссылочной целостности.
Структурированные типы данных
Структурированные типы данных
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных: Массивы Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел

называемое множеством индексов. Отображение

из множества

Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов




Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Свойства отношений
Свойства отношений
Свойства отношений непосредственно следуют из приведенного выше определения отношения. В этих свойствах в основном и состоят различия между отношениями и таблицами. В отношении нет одинаковых кортежей. Действительно, тело отношения есть множество кортежей и, как всякое множество, не может содержать неразличимые элементы (см. понятие множества в гл.1.). Таблицы в отличие от отношений могут содержать одинаковые строки. Кортежи не упорядочены (сверху вниз). Действительно, несмотря на то, что мы изобразили отношение "Сотрудники" в виде таблицы, нельзя сказать, что сотрудник Иванов "предшествует" сотруднику Петрову. Причина та же - тело отношения есть множество, а множество не упорядочено. Это вторая причина, по которой нельзя отождествить отношения и таблицы - строки в таблицах упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых строки идут в различном порядке. Атрибуты не упорядочены (слева направо). Т.к. каждый атрибут имеет уникальное имя в пределах отношения, то порядок атрибутов не имеет значения. Это свойство несколько отличает отношение от математического определения отношения (см. гл.1 - компоненты кортежей там упорядочены). Это также третья причина, по которой нельзя отождествить отношения и таблицы - столбцы в таблице упорядочены. Одно и то же отношение может быть изображено разными таблицами, в которых столбцы идут в различном порядке. Все значения атрибутов атомарны. Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц - в ячейки таблиц можно поместить что угодно - массивы, структуры, и даже другие таблицы.
Замечание. Из свойств отношения следует, что не каждая таблица может задавать отношение. Для того, чтобы некоторая таблица задавала отношение, необходимо, чтобы таблица имела простую структуру (содержала бы только строки и столбцы, причем, в каждой строке было бы одинаковое количество полей), в таблице не должно быть одинаковых строк, любой столбец таблицы должен содержать данные только одного типа, все используемые типы данных должны быть простыми.
Замечание. Каждое отношение можно считать классом эквивалентности таблиц, для которых выполняются следующие условия: Таблицы имеют одинаковое количество столбцов. Таблицы содержат столбцы с одинаковыми наименованиями. Столбцы с одинаковыми наименованиями содержат данные из одних и тех же доменов. Таблицы имеют одинаковые строки с учетом того, что порядок столбцов может различаться.
Все такие таблицы есть различные изображения одного и того же отношения.
Теорема Есварана о сериализуемости
Теорема Есварана о сериализуемости
Концепция способности к упорядочению была впервые предложена Есвараном [50].
В этой работе был предложен протокол двухфазной блокировки: Перед выполнение каких-либо операций с некоторым объектом, транзакция должна заблокировать этот объект. После снятия блокировки, транзакция не должна накладывать никаких других блокировок.
Транзакции, используемые в этом протоколе, не различаются по типам и считаются монопольными. Описанные выше протоколы доступа к данным с использованием S- и X-блокировок и протокол преднамеренных блокировок являются модификациями протокола двухфазной блокировки для случая, когда блокировки имеют различные типы.
Есвараном сформулирована следующая теорема:
Теорема Есварана. Если все транзакции в смеси подчиняются протоколу двухфазной блокировки, то для всех чередующихся графиков запуска существует возможность упорядочения.
Протокол называется двухфазным, потому что он характеризуется двумя фазами: 1 фаза - нарастание блокировок. Во время этой фазы накладываются блокировки, и производится работа с заблокированными объектами. 2 фаза - снятие блокировок. Во время этой фазы блокировки только снимаются. Работа с ранее заблокированными данными может продолжаться.
Работа транзакции может выглядеть приблизительно, как на рисунке:

Рисунок 1 Работа транзакции по протоколу двухфазной блокировки
На следующем рисунке показан пример транзакции, не подчиняющийся протоколу двухфазной блокировки:

Рисунок 2 Транзакция, не подчиняющаяся протоколу двухфазной блокировки
На практике, как правило, вторая фаза сводится к одной операции завершения транзакции (или отката транзакции) с одновременным снятием всех блокировок.
Если некоторая транзакция A не подчиняется протоколу двухфазной блокировки (и, следовательно, состоит не менее чем из двух операция блокирования и разблокирования), то всегда можно построить другую транзакцию B, которая при чередующемся выполнении вместе с A приводит к графику, не подлежащему упорядочению и неверному.
Теоретикомножественные операторы
Теоретико-множественные операторы
Типы данных
Типы данных
Любые данные, используемые в программировании, имеют свои типы данных.
Важно! Реляционная модель требует, чтобы типы используемых данных были простыми.
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы: Простые типы данных. Структурированные типы данных. Ссылочные типы данных.
Типы данных используемые в реляционной модели
Типы данных, используемые в реляционной модели
Собственно, для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым, нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных. Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т.д.
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Например, можно создать новый тип - комплексные числа как запись вида




Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
Тэтасоединение
Тэта-соединение
Определение 9. Пусть отношение


Это частный случай операции общего соединения.
Иногда, для операции

Пример 8. Рассмотрим некоторую компанию, в которой хранятся данные о поставщиках и поставляемых деталях. Пусть поставщикам и деталям присвоен некий статус. Пусть бизнес компании организован таким образом, что поставщики имеют право поставлять только те детали, статус которых не выше статуса поставщика (смысл этого может быть в том, что хороший поставщик с высоким статусом может поставлять больше разновидностей деталей, а плохой поставщик с низким статусом может поставлять только ограниченный список деталей, важность которых (статус детали) не очень высока).
Транзитивное замыкание отношений
Транзитивное замыкание отношений
Введем понятие транзитивного замыкания, связанное с бинарными отношениями, которое понадобится в дальнейшем.
Определение 11. Пусть отношение






Очевидно, что

Пример 7. Пусть множество
причем некоторые из деталей и конструкций могут использоваться при сборке других конструкций. Взаимосвязь деталей описывается отношением
Трехзначная логика (3VL)
Трехзначная логика (3VL)
Т.к. null-значение обозначает на самом деле тот факт, что значение неизвестно, то любые алгебраические операции (сложение, умножение, конкатенация строк и т.д.) должны давать также неизвестное значение, т.е. null. Действительно, если, например, вес детали неизвестен, то неизвестно также, сколько весят 10 таких деталей.
При сравнении выражений, содержащих null-значения, результат также может быть неизвестен, например, значение истинности для выражения

Учебное пособие
Учебное пособие
Учебное пособие было опубликовано в 1999 г. в двух частях издательством Башкирского государственного университета.
Выходные данные:
УДК 519.6
ББК 32.973-018.2
Пушников А.Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: Учебное пособие/Изд-е Башкирского ун-та. - Уфа, 1999. - 108 с. - ISBN 5-7477-0350-1.
Пушников А.Ю. Введение в системы управления базами данных. Часть 2. Нормальные формы отношений и транзакции: Учебное пособие/Изд-е Башкирского ун-та. - Уфа, 1999. - 138 с. - ISBN 5-7477-0351-X.
Рецензенты: канд.тех.н., доц. Мартынов В.В. (Уфимский государственный авиационный техни-ческий университет); кафедра автоматизированных систем управления УГАТУ.
В настоящий момент автор работает в Уфимском представительстве компании АйТи (web page: www.it.ru, www.itc.ufanet.ru).
Связаться с автором можно:
Раб.тел.: (3472) 25-37-71, 25-38-11, 25-38-53
Дом.тел.: (3472) 54-90-84
E-mail: apushnik@itc.ufanet.ru, apushnik@mail.ru
UPDATE обновление строк в таблице
UPDATE - обновление строк в таблице
Пример 3. Обновление нескольких строк в таблице: UPDATE P SET PNAME = "Пушников" WHERE P.PNUM = 1;
Уровни изоляции
Уровни изоляции
Стандарт SQL не предусматривает понятие блокировок для реализации сериализуемости смеси транзакций. Вместо этого вводится понятие уровней изоляции. Этот подход обеспечивает необходимые требования к изолированности транзакций, оставляя возможность производителям различных СУБД реализовывать эти требования своими способами (в частности, с использованием блокировок или выделением версий данных).
Стандарт SQL предусматривает 4 уровня изоляции: READ UNCOMMITTED - уровень незавершенного считывания. READ COMMITTED - уровень завершенного считывания. REPEATABLE READ - уровень повторяемого считывания. SERIALIZABLE - уровень способности к упорядочению.
Если все транзакции выполняются на уровне способности к упорядочению (принятом по умолчанию), то чередующееся выполнение любого множества параллельных транзакций может быть упорядочено. Если некоторые транзакции выполняются на более низких уровнях, то имеется множество способов нарушить способность к упорядочению. В стандарте SQL выделены три особых случая нарушения способности к упорядочению, фактически именно те, которые были описаны выше как проблемы параллелизма: Неаккуратное считывание ("Грязное" чтение, незафиксированная зависимость). Неповторяемое считывание (Частный случай несовместного анализа). Фантомы (Фиктивные элементы - частный случай несовместного анализа).
Потеря результатов обновления стандартом SQL не допускается, т.е. на самом низком уровне изолированности транзакции должны работать так, чтобы не допустить потери результатов обновления.
Различные уровни изоляции определяются по возможности или исключению этих особых случаев нарушения способности к упорядочению. Эти определения описываются следующей таблицей:
Виды восстановления данных
Виды восстановления данных
Восстановление базы данных может производиться в следующих случаях: Индивидуальный откат транзакции. Откат индивидуальной транзакции может быть инициирован либо самой транзакцией путем подачи команды ROLLBACK, либо системой. СУБД может инициировать откат транзакции в случае возникновения какой-либо ошибки в работе транзакции (например, деление на нуль) или если эта транзакция выбрана в качестве жертвы при разрешении тупика. Мягкий сбой системы (аварийный отказ программного обеспечения). Мягкий сбой характеризуется утратой оперативной памяти системы. При этом поражаются все выполняющиеся в момент сбоя транзакции, теряется содержимое всех буферов базы данных. Данные, хранящиеся на диске, остаются неповрежденными. Мягкий сбой может произойти, например, в результате аварийного отключения электрического питания или в результате неустранимого сбоя процессора. Жесткий сбой системы (аварийный отказ аппаратуры). Жесткий сбой характеризуется повреждением внешних носителей памяти. Жесткий сбой может произойти, например, в результате поломки головок дисковых накопителей.
Во всех трех случаях основой восстановления является избыточность данных, обеспечиваемая журналом транзакций.
Как и страницы базы данных, данные из журнала транзакций не записываются сразу на диск, а предварительно буферизируются в оперативной памяти. Таким образом, система поддерживает два вида буферов - буферы страниц базы данных и буферы журнала транзакций.
Страницы базы данных, содержимое которых в буфере (в оперативной памяти) отличается от содержимого на диске, называются "грязными" (dirty) страницами. Система постоянно поддерживает список "грязных" страниц - dirty-список. Запись "грязных" страниц из буфера на диск называется выталкиванием страниц во внешнюю память. Очевидно, необходимо предусмотреть такие правила выталкивания буферов базы данных и буферов журнала транзакций, которые обеспечивали бы два требования: Максимальную скорость выполнения транзакций. Для этого необходимо выталкивать страницы как можно реже. В идеале, если оперативная память была бы бесконечной, и сбои никогда бы не происходили, наилучшим выходом была бы загрузка всей базы данных в оперативную память, работа с данными только в оперативной памяти, и запись измененных страниц на диск только в момент завершения работы всей системы. Гарантию, что при возникновении сбоя (любого типа), данные завершенных транзакций можно было бы восстановить, а данные незавершенных транзакций бесследно удалить, т.е. обеспечение восстановления последнего согласованного состояния базы данных. Для этого что-то выталкивать на диск все-таки необходимо, даже если мы обладали бы бесконечной оперативной памятью.
Таким образом, имеется две причины для периодического выталкивания страниц во внешнюю память - недостаток оперативной памяти и возможность сбоев.
Основным принципом согласованной политики выталкивания буфера журнала и буферов страниц базы данных является то, что запись об изменении объекта базы данных должна попадать во внешнюю память журнала раньше, чем измененный объект оказывается во внешней памяти базы данных. Соответствующий протокол журнализации (и управления буферизацией) называется Write Ahead Log (WAL) - "пиши сначала в журнал", и состоит в том, что если требуется вытолкнуть во внешнюю память измененный объект базы данных, то перед этим нужно гарантировать выталкивание во внешнюю память журнала записи о его изменении. Это означает, что если во внешней памяти базы данных содержится объект, к которому применена некоторая команда модификации, то во внешней памяти журнала транзакций содержится запись об этой операции. Обратное неверно - если во внешней памяти журнала содержится запись о некотором изменении объекта, то во внешней памяти базы данных может и не быть самого измененного объекта.
Дополнительное условие на выталкивание буферов накладывается тем требованием, что каждая успешно завершившаяся транзакция должна быть реально зафиксирована во внешней памяти. Какой бы сбой не произошел, система должна быть в состоянии восстановить состояние базы данных, содержащее результаты всех зафиксированных к моменту сбоя транзакций.
Третьим условием выталкивания буферов является ограниченность объемов буферов базы данных и журнала транзакций. Периодически или при наступлении определенного события (например, количество страниц в dirty-списке превысило определенный порог, или количество свободных страниц в буфере уменьшилось и достигло критического значения) система принимает так называемую контрольную точку. Принятие контрольной точки включает выталкивание во внешнюю память содержимого буферов базы данных и специальную физическую запись контрольной точки, которая представляет собой список всех осуществляемых в данный момент транзакций.
Оказывается, что минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является выталкивание при фиксации транзакции во внешнюю память журнала всех записей об изменении базы данных этой транзакцией. При этом последней записью в журнал, производимой от имени данной транзакции, является специальная запись о конце этой транзакции.
Внешние ключи
Внешние ключи
Различные объекты предметной области, информация о которых хранится в базе данных, всегда взаимосвязаны друг с другом. Например, накладная на поставку товара содержит список товаров с количествами и ценами, сотрудник предприятия имеет детей, числится в подразделении и т.д. Термины "содержит", "имеет", "числится" отражают взаимосвязи между понятиями "накладная" и "список товаров", "сотрудник" и "дети", "сотрудник" и "подразделение". Такие взаимосвязи отражаются в реляционных базах данных при помощи внешних ключей, связывающих несколько отношений.
Рассмотрим пример с поставщиками и поставками деталей. Предположим, что нам требуется хранить информацию о наименовании поставщиков, наименовании и количестве поставляемых ими деталей, причем каждый поставщик может поставлять несколько деталей и каждая деталь может поставляться несколькими поставщиками. Можно предложить хранить данные в следующем отношении:
Восстановление данных и стандарт SQL
Восстановление данных и стандарт SQL
Стандарт языка SQL не содержит требований к восстановимости данных, оставляя эти вопросы на усмотрение разработчиков СУБД.
Восстановление после мягкого сбоя
Восстановление после мягкого сбоя
Несмотря на протокол WAL, после мягкого сбоя не все физические страницы базы данных содержат измененные данные, т.к. не все "грязные" страницы базы данных были вытолкнуты во внешнюю память.
Последний момент, когда гарантированно были вытолкнуты "грязные" страницы - это момент принятия последней контрольной точки. Имеется 5 вариантов состояния транзакций по отношению к моменту последней контрольной точки и к моменту сбоя:

Рисунок 1 Пять вариантов транзакций
Последняя контрольная точка принималась в момент tc. Мягкий сбой системы произошел в момент tf. Транзакции T1-T5 характеризуются следующими свойствами: T1 - транзакция успешно завершена до принятия контрольной точки. Все данные этой транзакции сохранены в долговременной памяти - как записи журнала, так и страницы данных, измененные этой транзакцией. Для транзакции T1 никаких операций по восстановлению не требуется. T2 - транзакция начата до принятия контрольной точки и успешно завершена после контрольной точки, но до наступления сбоя. Записи журнала транзакций, относящиеся к этой транзакции вытолкнуты во внешнюю память. Страницы данных, измененные этой транзакцией, только частично вытолкнуты во внешнюю память. Для данной транзакции необходимо повторить заново те операции, которые были выполнены после принятия контрольной точки. T3 - транзакция начата до принятия контрольной точки и не завершена в результате сбоя. Такую транзакцию необходимо откатить. Проблема, однако, в том, что часть страниц данных, измененных этой транзакцией, уже содержится во внешней памяти - это те страницы, которые были обновлены до принятия контрольной точки. Следов изменений, внесенных после контрольной точки в базе данных нет. Записи журнала транзакций, сделанные до принятия контрольной точки, вытолкнуты во внешнюю память, те записи журнала, которые были сделаны после контрольной точки, отсутствуют во внешней памяти журнала. T4 - транзакция начата после принятия контрольной точки и успешно завершена до сбоя системы. Записи журнала транзакций, относящиеся к этой транзакции вытолкнуты во внешнюю память журнала. Изменения в базе данных, внесенные этой транзакцией, полностью отсутствуют во внешней памяти базы данных. Такую транзакцию необходимо повторить целиком. T5 - транзакция начата после принятия контрольной точки и не завершена в результате сбоя. Никаких следов этой транзакции нет ни во внешней памяти журнала транзакций, ни во внешней памяти базы данных. Для такой транзакции никаких действий предпринимать не нужно, ее как бы и не было вовсе.
Восстановление системы после мягкого сбоя осуществляется как часть процедуры перезагрузки системы. При перезагрузке системы транзакции T2 и T4 необходимо частично или полностью повторить, транзакцию T3 - частично откатить, для транзакций T1 и T5 никаких действий предпринимать не нужно. При перезагрузке система выполняет следующие действия: Создается два списка транзакций UNDO (отменить) и REDO (повторить). В список UNDO заносятся все транзакции из последней записи контрольной точки (т.е. все транзакции, выполнявшиеся в момент принятия контрольной точки). Список REDO остается пустым. В нашем случае будет: UNDO = {T2, T3}, REDO = { }. Начиная с записи контрольной точки просматривается вперед журнал транзакций. Если в журнале транзакций обнаруживается запись о начале транзакции, то эта транзакция добавляется в список UNDO. В нашем случае будет: UNDO = {T2, T3, T4}, REDO = { }. Заметим, что следов транзакции T5 в журнале транзакций нет. Если в файле регистрации обнаруживается запись COMMIT об окончании транзакции, то эта транзакция добавляется в список REDO. В нашем случае будет: UNDO = {T2, T3, T4}, REDO = {T2, T4}. Заметим, что записи о конце этих транзакций имеются во внешней памяти журнала транзакций в соответствии с минимальным требованием выталкивания записей журнала при фиксации транзакции. Когда достигается конец журнала транзакций, оба списка анализируются. При этом из списка UNDO удаляются те транзакции, которые попали в список REDO. В нашем случае будет: UNDO = {T3}, REDO = {T2, T4}. После этого система просматривает журнал транзакций назад, начиная с момента контрольной точки и откатывая все транзакции из списка UNDO. В нашем случае будут откатываться те операции транзакции T3, которые были выполнены до принятия контрольной точки. Окончательно, система просматривает журнал транзакций вперед, начиная с момента контрольной точки, и повторно выполняет все операции транзакций из списка REDO. В нашем случае, система выполнит повторно все операции транзакции T4 и те операции транзакции T2, которые были выполнены после принятия контрольной точки.
Восстановление после жесткого сбоя
Восстановление после жесткого сбоя
При жестком сбое база данных на диске нарушается физически. Основой восстановления в этом случае является журнал транзакций и архивная копия базы данных. Архивная копия базы данных должна создаваться периодически, а именно с учетом скорости наполнения журнала транзакций.
Восстановление начинается с обратного копирования базы данных из архивной копии. Затем выполняется просмотр журнала транзакций для выявления всех транзакций, которые закончились успешно до наступления сбоя. (Транзакции, закончившиеся откатом до наступления сбоя, можно не рассматривать). После этого по журналу транзакций в прямом направлении повторяются все успешно законченные транзакции. При этом нет необходимости отката транзакций, прерванных в результате сбоя, т.к. изменения, внесенными этими транзакциями, отсутствуют после восстановления базы данных из резервной копии.
Наиболее плохим случаем является ситуация, когда разрушены физически и база данных, и журнал транзакций. В этом случае единственное, что можно сделать - это восстановить состояние базы данных на момент последнего резервного копирования. Для того чтобы не допустить возникновение такой ситуации, базу данных и журнал транзакций обычно располагают на физически разных дисках, управляемых физически разными контроллерами.
Основное назначение данного учебного пособия
Введение
Основное назначение данного учебного пособия - дать систематическое введение в основы реляционной модели данных и принципы функционирования реляционных баз данных.
Реляционная модель описывает, какие данные могут храниться в реляционных базах данных, а также способы манипулирования такими данными. В упрощенном виде основная идея реляционной модели состоит в том, что данные должны храниться в таблицах и только в таблицах. Эта, кажущаяся тривиальной, идея оказывается вовсе не простой при рассмотрении вопроса, а что, собственно, представляет собой таблица? В данный момент существуем много различных систем обработки данных, оперирующих понятием "таблица", например, всем известные, электронные таблицы, таблицы текстового редактора MS Word, и т.п. Ячейки электронной таблицы могут хранить разнотипные данные, например, числа, строки текста, формулы, ссылающиеся на другие ячейки. Собственно, на одном листе электронной таблицы можно разместить несколько совершенно независимых таблиц, если под таблицей понимать прямоугольную область, расчерченную на клеточки и заполненную данными. Таблицы текстовых редакторов вообще могут иметь совершенно произвольную структуру, например, как на рисунке:
ВВЕДЕНИЕ В СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
ВВЕДЕНИЕ В СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
Выборка (ограничение селекция)
Выборка (ограничение, селекция)
Определение 6. Выборкой (ограничением, селекцией) на отношении

В простейшем случае условие



Синтаксис операции выборки:

или

Пример 6. Пусть дано отношение
Вычитание
Вычитание
Определение 4. Вычитанием двух совместимых по типу отношений
Синтаксис операции вычитания:

Пример 4. Для тех же отношений
это неопределяемое понятие, представляющее некоторую
Выводы
Множество- это неопределяемое понятие, представляющее некоторую совокупность данных. Элементы множества можно отличать друг от друга, а также определять, принадлежит ли данный элемент данному множеству. Над множествами можно выполнять операции объединения, пересечения, разности и дополнения.
Новые множества можно строить при помощи понятия декартового произведения (конечно, есть и другие способы, но они нас в данный момент не интересуют). Декартово произведение нескольких множеств - это множество кортежей, построенный из элементов этих множеств.
Отношение- это подмножество декартового произведения множеств. Отношения состоят из однотипных кортежей. Каждое отношение имеет предикат отношения и каждый n-местный предикат задает n-арное отношение.
Отношение является математическим аналогом понятия "таблица".
Отношения обладают степенью и мощностью. Степень отношения - это количество элементов в каждом кортеже отношения (аналог количества столбцов в таблице). Мощность отношения - это мощность множества кортежей отношения (аналог количества строк в таблице).
В математике чаще всего используют бинарные отношения (отношения степени 2). В теории баз данных основными являются отношения степени

Реляционная модель данных состоит из
Выводы
Реляционная модель данных состоит из трех частей:
Структурной части. Целостной части. Манипуляционной части.
В классической реляционной модели используются только простые (атомарные) типы данных. Простые типы данных не обладают внутренней структурой.
Домены - это типы данных, имеющие некоторый смысл (семантику). Домены ограничивают сравнения - некорректно, хотя и возможно, сравнивать значения из различных доменов.
Отношение состоит из двух частей - заголовка отношения и тела отношения. Заголовок отношения - это аналог заголовка таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения. Тело отношения - это аналог тела таблицы. Тело отношения состоит из кортежей. Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения.
Отношение обладает следующими свойствами:
В отношении нет одинаковых кортежей. Кортежи не упорядочены (сверху вниз). Атрибуты не упорядочены (слева направо). Все значения атрибутов атомарны.
Реляционной базой данных называется набор отношений.
Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных.
Отношение находится в Первой Нормальной Форме (1НФ), если оно содержит только скалярные (атомарные) значения.
данные часто бывают неполными или
Выводы
Современные СУБД допускают использование null-значений, т.к. данные часто бывают неполными или неизвестными. Споры о допустимости использования null-значений ведутся до сих пор. Использование null-значения связано с применением трехзначной логики (three-valued logic, 3VL).
Средством, позволяющим однозначно идентифицировать кортежи отношения, являются потенциальные ключи отношения.
Потенциальный ключ отношения - это набор атрибутов отношения, обладающий свойствами уникальности и неизбыточности. Доступ к конкретному кортежу можно получить, лишь зная значение потенциального ключа для этого кортежа.
Традиционно один из потенциальных ключей объявляется первичным ключом, остальные - альтернативными ключами.
Потенциальный ключ, состоящий из одного атрибута, называется простым. Потенциальный ключ, состоящий из нескольких атрибутов, называется составным.
Отношения связываются друг с другом при помощи внешних ключей.
Внешний ключ отношения - это набор атрибутов отношения, содержащий ссылки на потенциальный ключ другого (или того же самого) отношения. Отношение, содержащее потенциальный ключ, на который ссылается некоторый внешний ключ, называется родительским отношением. Отношение, содержащее внешний ключ, называется дочерним отношением.
Внешний ключ не обязан обладать свойством уникальности. Поэтому, одному кортежу родительского отношения может соответствовать несколько кортежей дочернего отношения. Такой тип связи между отношениями называется "один-ко-многим".
Связи типа "много-ко-многим" реализуются использованием нескольких отношений типа "один-ко-многим".
В любой реляционной базе данных должны выполняться два ограничения:
Целостность сущностей Целостность внешних ключей
Правило целостности сущностей состоит в том, что атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений.
Правило целостности внешних ключей состоит в том, что внешние ключи не должны ссылаться на отсутствующие в родительском отношении кортежи, т.е. внешние ключи должны быть корректны.
Ссылочную целостность могут нарушить операции, изменяющие состояние базы данных. Такими операциями являются операции вставки, обновления и удаления кортежей.
Для поддержания ссылочной целостности обычно используются две основные стратегии:
RESTRICT (ОГРАНИЧИТЬ) - не разрешать выполнение операции, приводящей к нарушению ссылочной целостности. CASCADE (КАСКАДИРОВАТЬ) - разрешить выполнение требуемой операции, но внести каскадные изменения в другие отношения так, чтобы не допустить нарушения ссылочной целостности.
Дополнительными стратегиями поддержания ссылочной целостности являются:
SET NULL (УСТАНОВИТЬ В NULL) - все некорректные значения внешних ключей изменять на null-значения. SET DEFAULT (УСТАНОВИТЬ ПО УМОЛЧАНИЮ) - все некорректные значения внешних ключей изменять на некоторое значение, принятое по умолчанию.
В реальных СУБД можно также отказаться от использования какой-либо стратегии поддержания ссылочной целостности:
IGNORE (ИГНОРИРОВАТЬ) - выполнять операции, не обращая внимания на нарушения ссылочной целостности.
Пользователь может разработать свою уникальную стратегию поддержания ссылочной целостности.
к реляционным данным возможен при
Выводы
Доступ к реляционным данным возможен при помощи операторов реляционной алгебры. Реляционная алгебра представляет собой набор операторов, использующих отношения в качестве аргументов, и возвращающие отношения в качестве результата. Реляционная алгебра замкнута таким образом, что результаты одних реляционных выражений можно использовать в других выражениях.
Традиционно определяют восемь реляционных операторов, объединенных в две группы.
Теоретико-множественные операторы: объединение, пересечение, вычитание, декартово произведение.
Специальные реляционные операторы: выборка, проекция, соединение, деление.
Для выполнения некоторых реляционных операторов требуется, чтобы отношения были совместимы по типу.
Не все операторы реляционной алгебры являются независимыми - некоторые из них выражаются через другие реляционные операторы. Операторы соединения, пересечения и деления можно выразить через другие реляционные операторы, т.е. эти операторы не являются примитивными. Оставшиеся реляционные операторы (объединение, вычитание, декартово произведение, выборка, проекция) являются примитивными операторами - их нельзя выразить друг через друга.
Имеется несколько типов запросов, которые нельзя выразить средствами реляционной алгебры. К ним относятся запросы, требующие дать в ответе список атрибутов, удовлетворяющих определенным условиям, построение транзитивного замыкания отношений, построение кросс-таблиц. Для получения ответов на подобные запросы приходится использовать процедурные расширения реляционных языков.
в настоящее время стал язык
Выводы
Фактически стандартным языком доступа к базам данных в настоящее время стал язык SQL (Structured Query Language).
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например, вместо "отношений" используются "таблицы", вместо "кортежей" - "строки", вместо "атрибутов" - "колонки" или "столбцы".
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее.
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям:
Операторы DDL (Data Definition Language) - операторы определения объектов базы данных. Операторы DML (Data Manipulation Language) - операторы манипулирования данными. Операторы защиты и управления данными, и др.
Одним из основных операторов DML является оператор SELECT, позволяющий извлекать данные из таблиц и получать ответы на различные запросы. Оператор SELECT содержит в себе все возможности реляционной алгебры. Это означает, что любой оператор реляционной алгебры может быть выражен при помощи подходящего оператора SELECT. Этим доказывается реляционная полнота языка SQL.
Различают концептуальную схему выполнения оператора SELECT и фактическую схему его выполнения. Концептуальная схема описывает, в какой логической последовательности должны выполняться операции, чтобы получить результат. При реальном выполнении оператора SELECT на первый план выступает достижение максимальной скорости выполнения запроса. Для этого используется оптимизатор, который, анализируя различные планы выполнения запроса, выбирает наилучший из них.
При разработке базы данных можно
Выводы
При разработке базы данных можно выделить несколько уровней моделирования:
Сама предметная область Модель предметной области Логическая модель данных Физическая модель данных Собственно база данных и приложения
Ключевые решения, определяющие качество будущей базы данных закладываются на этапе разработки логической модели данных. "Хорошие" модели данных должны удовлетворять определенным критериям:
Адекватность базы данных предметной области Легкость разработки и сопровождения базы данных Скорость выполнения операций обновления данных (вставка, обновление, удаление) Скорость выполнения операций выборки данных
Первая нормальная форма (1НФ) - это обычное отношение. Отношение в 1НФ обладает следующими свойствами:
В отношении нет одинаковых кортежей. Кортежи не упорядочены. Атрибуты не упорядочены. Все значения атрибутов атомарны.
Отношения, находящиеся в 1НФ являются "плохими" в том смысле, что они не удовлетворяют выбранным критериям - имеется большое количество аномалий обновления, для поддержания целостности базы данных требуется разработка сложных триггеров.
Отношение
Отношения в 2НФ "лучше", чем в 1НФ, но еще недостаточно "хороши" - остается часть аномалий обновления, по-прежнему требуются триггеры, поддерживающие целостность базы данных.
Отношение
Отношения в 3НФ являются самыми "хорошими" с точки зрения выбранных нами критериев - устранены аномалии обновления, требуются только стандартные триггеры для поддержания ссылочной целостности.
Переход от ненормализованных отношений к отношениям в 3НФ может быть выполнен при помощи алгоритма нормализации. Алгоритм нормализации заключается в последовательной декомпозиции отношений для устранения функциональных зависимостей атрибутов от части сложного ключа (приведение к 2НФ) и устранения функциональных зависимостей неключевых атрибутов друг от друга (приведение к 3НФ).
Корректность процедуры нормализации (декомпозиция без потери информации) доказывается теоремой Хеза.
Обобщением 3НФ на случай, когда
Выводы
Обобщением 3НФ на случай, когда отношение имеет более одного потенциального ключа, является нормальная форма Бойса-Кодда.
Отношение
Нормализация отношений вплоть до нормальной формы Бойса-Кодда основывалась на понятии функциональной зависимости и теореме Хеза, гарантировавшей, что декомпозиция будет происходить без потерь информации.
Дальнейшая нормализация связана уже с обобщением понятия функциональной зависимости.
Атрибуты (множества атрибутов)


Корректность дальнейшей декомпозиции основывается на теореме Фейджина, которая говорит о том, что декомпозиция отношения на две проекции является декомпозицией без потерь тогда и только тогда, когда в отношении имеется некоторая многозначная зависимость.
Если в отношении имеется функциональная зависимость, то автоматически имеется и тривиальная многозначная зависимость, определяемая этой функциональной зависимостью.
Многозначная зависимость


Отношение
Имеют место зависимости специального вида, когда отношение не может быть подвергнуто декомпозиции без потерь на две проекции, но может быть декомпозировано на большее число проекций. Такие зависимости называются зависимостями соединения и являются обобщением понятия многозначной зависимости.
Отношение
Реальным средством моделирования данных является
Выводы
Реальным средством моделирования данных является не формальный метод нормализации отношений, а так называемое семантическое моделирование.
В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER - Entity-Relationship).
Диаграммы сущность-связь позволяют использовать наглядные графические обозначения для моделирования сущностей и их взаимосвязей.
Различают концептуальные и физические ER-диаграммы. Концептуальные диаграммы не учитывают особенностей конкретных СУБД. Физические диаграммы строятся по концептуальным и представляют собой прообраз конкретной базы данных. Сущности, определенные в концептуальной диаграмме становятся таблицами, атрибуты становятся колонками таблиц (при этом учитываются допустимые для данной СУБД типы данных и наименования столбцов), связи реализуются путем миграции ключевых атрибутов родительских сущностей и создания внешних ключей.
При правильном определении сущностей, полученные таблицы будут сразу находиться в 3НФ. Основное достоинство метода состоит в том, модель строится методом последовательных уточнений первоначальных диаграмм.
В данной главе, являющейся иллюстрацией к методам ER-моделирования, не рассмотрены более сложные аспекты построения диаграмм, такие как подтипы, роли, исключающие связи, непереносимые связи, идентифицирующие связи и т.п.
с точки зрения воздействия на
Выводы
Транзакция - это неделимая, с точки зрения воздействия на СУБД, последовательность операций манипулирования данными, выполняющаяся по принципу "все или ничего", и переводящая базу данных из одного целостного состояния в другое целостное состояние.
Транзакция обладает четырьмя важными свойствами, известными как свойства АСИД:
(А) Атомарность. (С) Согласованность. (И) Изоляция. (Д) Долговечность.
База данных находится в согласованном состоянии, если для этого состояния выполнены все ограничения целостности.
Ограничение целостности - это некоторое утверждение, которое может быть истинным или ложным в зависимости от состояния базы данных.
Ограничения целостности классифицируются несколькими способами:
По способам реализации. По времени проверки. По области действия.
По способам реализации различают:
Декларативную поддержку ограничений целостности - средствами языка определения данных (DDL). Процедурную поддержку ограничений целостности - посредством триггеров и хранимых процедур.
По времени проверки ограничения делятся на:
Немедленно проверяемые ограничения. Ограничения с отложенной проверкой.
По области действия ограничения делятся на:
Ограничения домена. Ограничения атрибута. Ограничения кортежа. Ограничения отношения. Ограничения базы данных.
Стандарт языка SQL поддерживает только декларативные ограничения целостности, реализуемые как:
Ограничения домена. Ограничения, входящие в определение таблицы. Ограничения, хранящиеся в базе данных в виде независимых утверждений (assertion).
Проверка ограничений допускается как после выполнения каждого оператора, могущего нарушить ограничение, так и в конце транзакции. Во время выполнения транзакции можно изменить режим проверки ограничения.
Современные многопользовательские системы допускают одновременную
Выводы
Современные многопользовательские системы допускают одновременную работу большого числа пользователей. При этом если не предпринимать специальных мер, транзакции будут мешать друг другу. Этот эффект известен как проблемы параллелизма.
Имеются три основные проблемы параллелизма:
Проблема потери результатов обновления. Проблема незафиксированной зависимости (чтение "грязных" данных, неаккуратное считывание). Проблема несовместимого анализа.
График запуска набора транзакций называется последовательным, если транзакции выполняются строго по очереди. Если график запуска набора транзакций содержит чередующиеся элементарные операции транзакций, то такой график называется чередующимся. Два графика называются эквивалентными, если при их выполнении будет получен один и тот же результат, независимо от начального состояния базы данных. График запуска транзакции называется верным (сериализуемым), если он эквивалентен какому-либо последовательному графику.
Решение проблем параллелизма состоит в нахождении такой стратегии запуска транзакций, чтобы обеспечить сериализуемость графика запуска и не слишком уменьшить степень параллельности.
Одним из методов обеспечения сериальности графика запуска является протокол доступа к данным при помощи блокировок. В простейшем случае различают S-блокировки (разделяемые) и X-блокировки (монопольные). Протокол доступа к данным имеет вид:
Прежде чем прочитать объект, транзакция должна наложить на этот объект S-блокировку. Прежде чем обновить объект, транзакция должна наложить на этот объект X-блокировку. Если транзакция уже заблокировала объект S-блокировкой (для чтения), то перед обновлением объекта S-блокировка должна быть заменена X-блокировкой. Если блокировка объекта транзакцией B отвергается оттого, что объект уже заблокирован транзакцией A, то транзакция B переходит в состояние ожидания. Транзакция B будет находиться в состоянии ожидания до тех пор, пока транзакция A не снимет блокировку объекта. X-блокировки, наложенные транзакцией A, сохраняются до конца транзакции A.
Если все транзакции в смеси подчиняются протоколу доступа к данным, то проблемы параллелизма решаются (почти все, кроме "фантомов"), но появляются тупики. Состояние тупика (dead locks) характеризуется тем, что две или более транзакции пытаются заблокировать одни и те же объекты, и бесконечно долго ожидают друг друга.
Для разрушения тупиков система периодически или постоянно поддерживает графа ожидания транзакций. Наличие циклов в графе ожидания свидетельствует о возникновении тупика. Для разрушения тупика одна из транзакций (наиболее дешевая с точки зрения системы) выбирается в качестве жертвы и откатывается.
Для решения проблемы "фантомов", а также для уменьшения накладных расходов, вызываемых большим количеством блокировок, применяются более сложные методы. Одним из таких методов являются преднамеренные блокировки, блокирующие объекты разной величины - строки, страницы, таблицы, файлы и др.
Альтернативным является метод предикатных блокировок
Имеются также методы сериализации, не использующие блокировки. Это метод временных меток и механизм выделения версий. Механизм выделения версий удобен тем, что он позволяет одновременно, и читать, и изменять одни и те же данные разными транзакциями. Это увеличивает степень параллельности, и общую производительность системы.
Стандарт SQL не предусматривает понятие блокировок. Вместо этого вводится понятие уровней изоляции. Стандарт предусматривает 4 уровня изоляции:
READ UNCOMMITTED - уровень незавершенного считывания. READ COMMITTED - уровень завершенного считывания. REPEATABLE READ - уровень повторяемого считывания. SERIALIZABLE - уровень способности к упорядочению.
Транзакции могут запускаться с различными уровнями изоляции.
Главное требование долговечности данных транзакций
Выводы
Главное требование долговечности данных транзакций состоит в том, что данные зафиксированных транзакций должны сохраняться в системе, даже если в следующий момент произойдет сбой системы. Избыточность хранения данных, позволяющую восстановить систему после сбоя обычно обеспечивает журнал транзакций.
Восстановление базы данных может производиться в следующих случаях:
Индивидуальный откат транзакции. Мягкий сбой системы (аварийный отказ программного обеспечения). Жесткий сбой системы (аварийный отказ аппаратуры).
Страницы базы данных и журнала транзакций не записываются сразу на диск, а предварительно буферизируются в оперативной памяти. Страницы базы данных, содержимое которых в буфере отличается от содержимого на диске, называются "грязными" (dirty) страницами. Запись "грязных" страниц из буфера на диск называется выталкиванием страниц во внешнюю память.
Основным принципом согласованной политики выталкивания буфера журнала и буферов страниц базы данных является протокол журнализации Write Ahead Log (WAL) - "пиши сначала в журнал".
Минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является выталкивание при фиксации транзакции во внешнюю память журнала всех записей об изменении базы данных этой транзакцией.
Индивидуальный откат транзакции выполняется при помощи журнала транзакций.
Восстановление системы после мягкого сбоя осуществляется как часть процедуры перезагрузки системы. При перезагрузке системы транзакции проходят процедуру идентификации для выявления завершившихся и прерванных в результате сбоя транзакций. Транзакции, успешно завершившиеся до наступления сбоя, и данные о которых отсутствуют в базе данных, повторяются заново. Транзакции, не успевшие завершиться к моменту сбоя, и данные о которых имеются в базе данных, откатываются.
Восстановление системы после жесткого сбоя выполняется при помощи архивной копии базы данных и журнала транзакций.
Замечания к правилам целостности сущностей и внешних ключей
Замечания к правилам целостности сущностей и внешних ключей
На самом деле приведенные правила целостности сущностей и внешних ключей прямо следуют из определений понятий "потенциальный ключ" и "внешний ключ".
Действительно, в определении потенциального ключа требуется, чтобы потенциальный ключ обладал свойством уникальности. Это фактически означает, что мы должны уметь различать значения потенциальных ключей, т.е. при сравнении двух значений потенциального ключа мы всегда должны получать значения либо ИСТИНА, либо ЛОЖЬ. Но любое сравнение, в которое входит null-значение, принимает значение U - НЕИЗВЕСТНО, откуда следует, что атрибуты потенциального ключа не могут содержать null-значений.
Для внешних ключей правило целостности фактически входит в определение (п. 2 определения 2).
Таким образом, с точки зрения реляционной теории, явная формулировка правил целостности является излишней - они автоматически вытекают из определений понятий ключа и внешнего ключа.
Тем не менее, явная формулировка правил целостности имеет определенный практический смысл. В большинстве серьезных СУБД за выполнением этих ограничений следит сама СУБД, если, конечно, пользователь явно объявил потенциальные и внешние ключи. Но, во-первых, для некоторых систем можно допустить, чтобы эти ограничения не выполнялись, а во-вторых, некоторые системы просто не поддерживают понятия целостности, например, некоторые "настольные" СУБД типа FoxPro 2.5. В этих случаях за целостностью данных должен следить сам пользователь, или программист, разрабатывающий приложение для пользователя.
Явная формулировка правил целостности помогает четко понять, какие опасности несет в себе пренебрежение этими правилами.
Замкнутость реляционной алгебры
Замкнутость реляционной алгебры
Реляционная алгебра представляет собой набор операторов, использующих отношения в качестве аргументов, и возвращающие отношения в качестве результата. Таким образом, реляционный оператор


Реляционная алгебра является замкнутой, т.к. в качестве аргументов в реляционные операторы можно подставлять другие реляционные операторы, подходящие по типу:

Таким образом, в реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
Каждое отношение обязано иметь уникальное имя в пределах базы данных. Имя отношения, полученного в результате выполнения реляционной операции, определяется в левой части равенства. Однако можно не требовать наличия имен от отношений, полученных в результате реляционных выражений, если эти отношения подставляются в качестве аргументов в другие реляционные выражения. Такие отношения будем называть неименованными отношениями. Неименованные отношения реально не существуют в базе данных, а только вычисляются в момент вычисления значения реляционного оператора.
Традиционно, вслед за Коддом [43], определяют восемь реляционных операторов, объединенных в две группы.
Теоретико-множественные операторы: Объединение Пересечение Вычитание Декартово произведение
Специальные реляционные операторы: Выборка Проекция Соединение Деление
Не все они являются независимыми, т.е. некоторые из этих операторов могут быть выражены через другие реляционные операторы.
Запросы невыразимые средствами реляционной алгебры
Запросы, невыразимые средствами реляционной алгебры
Несмотря на мощь языка реляционной алгебры, имеется ряд типов запросов, которые принципиально нельзя выразить только при помощи операторов реляционной алгебры. Это вовсе не означает, что ответы на эти запросы нельзя получить вообще. Просто, для получения ответов на подобные запросы приходится применять процедурные расширения реляционных языков.
Зависимые реляционные операторы
Зависимые реляционные операторы
Как было сказано в начале главы, не все операторы реляционной алгебры являются независимыми - некоторые из них выражаются через другие реляционные операторы.
