Декартово произведение отношений
Операция декартова произведения выполняется над двумя произвольными отношениями А и В. Результатом операции декартова произведения является отношение С, степень которого равна сумме степеней исходных отношений, а мощность - произведению мощностей исходных отношений. Таким образом, декартово произведение отношений можно представить с помощью декартова произведения множеств:

Пример. Операция "декартово произведение". Выполним операцию декартова произведения отношений СЛУЖАЩИЕ и МЕДОСМОТР.
Исходные отношения: СЛУЖАЩИЕ (#, Фамилия, Пол) МЕДОСМОТР (Процедура, Дата)
| 1 | Иванов | М | ЭКГ | 17.08 | |
| 5 | Антонова | Ж | Анализ крови | 20.08 | |
| Терапевт | 23.08 |
Результирующее отношение:
РЕЗУЛЬТАТЫ_МЕДОСМОТРА ( #, Фамилия, Пол, Процедура, Дата ) =
СЛУЖАЩИЙ Х МЕДОСМОТР
| 1 | Иванов | м | ЭКГ | 17.08 |
| 1 | Иванов | м | Анализ крови | 20.08 |
| 1 | Иванов | м | Терапевт | 23.08 |
| 5 | Антонова | ж | ЭКГ | 17.08 |
| 5 | Антонова | ж | Анализ крови | 20.08 |
| 5 | Антонова | ж | Терапевт | 23.08 |
Деление отношений
Операция деления выполняется над двумя отношениями А и В, где А - отношение-делимое, а B - отношение-делитель. При этом атрибуты B должны являться подмножеством атрибутов A. Результатом выполнения операции деления является отношение С, которое включает в себя атрибуты отношения А, отличные от атрибутов отношения В, и только те кортежи, декартовы произведения которых с отношением В дают отношение А:

Представление частного отношений через другие алгебраические операции может быть получено следующим образом. Предположим, что





Пример. Деление отношений. Выполним операцию деления отношения РЕЗУЛЬТАТЫ_МЕДОСМОТРА на отношение МЕДОСМОТР.
Исходные отношения:
РЕЗУЛЬТАТЫ_МЕДОСМОТРА (#, Фамилия, Пол, Процедура, Дата)
МЕДОСМОТР (Процедура, Дата )
| 1 | Иванов | М | ЭКГ | 17.08 |
| 1 | Иванов | М | Анализ крови | 20.08 |
| 1 | Иванов | М | Терапевт | 23.08 |
| 5 | Антонова | Ж | ЭКГ | 17.08 |
| 5 | Антонова | Ж | Анализ крови | 20.08 |
| 5 | Антонова | Ж | Терапевт | 23.08 |
Результирующее отношение:
| ЭКГ | 17.08 |
| Анализ крови | 20.08 |
| Терапевт | 23.08 |
СЛУЖАЩИЙ (#, Фамилия, Пол) = РЕЗУЛЬТАТЫ_МЕДОСМОТРА / МЕДОСМОТР
| 1 | Иванов | М |
| 5 | Антонова | Ж |
Формы представления отношений
Как мы уже упоминали выше, отношения можно представлять в виде таблиц. Но в табличном представлении сложно показывать некоторые свойства отношений. Например, неоднозначность трактовки домена колонки. Поэтому предпринимаются попытки строить более четкие схемы описания отношений в реляционных базах данных. Ниже представлен фрагмент такого описания в виде примера схемы базы данных "КАДРЫ":
СХЕМА "ОТДЕЛ_КАДРОВ"
ДОМЕН Т_Табельный_номер ТИП целое ДОМЕН Т_ФИО ТИП символьное ДОМЕН Т_Зарплата ТИП десятичное с фиксированной точкой ..... ОТНОШЕНИЕ Служащий ( Табельный-номер / КЛЮЧ / ДОМЕН = Т_Табельный-номер, ФИО / ДОМЕН = Т_ФИО, .... ) .... КОНЕЦ ОПИСАНИЯ СХЕМЫ.
Подобное описание не прижилось среди проектировщиков баз данных. На практике прибегают к такому описанию крайне редко.
Для дальнейшего изложения нам понадобится одно из самых важных понятий обработки данных - понятие ключа.
Ключом или ключевым полем называется уникальное значение, которое позволяет тем или иным способом идентифицировать сущность или часть сущности предметной области, т.е. ключ - это значение некоторого атрибута или атрибутов в кортеже отношения, который представляет экземпляр сущности в реляционной модели данных.
Внимание! На данном этапе изложения мы не проводим особого различия между понятиями "ключ отношения" и "ключ сущности" предметной области, хотя далее мы будем эти ключи различать.
Заметим, что в определении ключа не требуется однозначной идентификации сущности предметной области базы данных. Ключ отношения - это не уникальный идентификатор сущности предметной области. Однако последний есть возможный кандидат на ключ отношения, иначе говорят, возможный ключ.
Принято различать первичные ключи и частичные ключи. Математически первичным ключом отношения R со схемой r является подмножество сужения декартового произведения, которое позволяет однозначно идентифицировать кортеж. Если первичный ключ содержит несколько атрибутов, то он называется составным ключом, в противном случае - атомарным.
Частичным ключом называется атрибут составного ключа, если он однозначно определяет совокупность неключевых атрибутов отношения. Атрибут кортежа, который является первичным ключом другого отношения, называется внешним (иногда посторонним) ключом.
Из определения отношения следует следующее важное свойство реляционной модели данных: каждое отношение должно иметь первичный ключ. Отсутствие первичного ключа в отношении может привести к приобретению кортежей, которые не определены текущим состоянием предметной области, или к потере уже существующих кортежей при выполнении теоретико-множественных операций. Причина подобных казусов лежит в механизме построения декартова произведения.
Заметим, что ключ в контексте модели предметной области базы данных всегда отражает ту или иную степень связи между атрибутами сущностей предметной области, т.е. семантически ключ есть средство моделирования связей в модели.
Пример: рассмотрим предложение "Гражданин Иванов проживал в городе Москве 10 лет". Возможными атрибутами в отношении Место_жительства являются фамилия гражданина, название города проживания и время проживания. Фамилия гражданина может выступать в качестве первичного ключа этого отношения, так как личность однозначно определяет время ее проживания в конкретном городе. Таким образом, в этом отношении моделируется связь "проживал" между атрибутами "фамилия" и "город".
Отношения в реляционной модели данных, как правило, представляются с помощью функциональной формы записи (так как мы записывает функции нескольких переменных в математическом анализе), при этом атрибуты первичного ключа подчеркиваются:
ИМЯ_ОТНОШЕНИЯ (Атрибуты первичного ключа, неключевые атрибуты).
Пример. Представление связи отношением. Представим связь между личностью и местом ее проживания через отношение ПРОЖИВАЕТ (Кл. личность, Кл. населенный_пункт, время)
Описание личности:
ЛИЧНОСТЬ (Кл. личность, ФИО, возраст, пол)
Описание населенного пункта:
НАСЕЛЕННЫЙ_ПУНКТ (Кл.населенный_пункт, география, население)
Однако наибольшее распространение получило представление отношений в виде графических диаграмм, например ER-диаграмм, о которых мы говорили в первой лекции. Преимуществами такого представления являются наглядность диаграмм и возможность их построения в ряде CASE-средств проектирования баз данных. Обычно CASE-средства позволяют поддерживать несколько уровней представления отношений. Так, например, ErWin поддерживает уровень логической и физической моделей базы данных.
Отметим, что представление фрагментов реального мира через отношения даже в рамках одной модели данных не характеризуется единственностью. Например, зададимся вопросом: "Что есть цвет автомобиля? Связь, объект или атрибут?" Если за объект принять автомобиль, то цвет может выступать в качестве атрибута автомобиля. Если рассматривать зависимость отражательной способности покрытия автомобиля от его цвета, то цвет можно считать объектом. Если рассматривать взаимосвязь между цветом модели автомобиля и ее номером, то цвет можно считать связью.
В любом случае при представлении какого-либо качества реального мира в модели следует четко понимать, какие запросы в рамках создаваемой модели данных должны быть разрешимыми. Рассмотрим отношение КРАСНЫЙ (модель). При использовании такого отношения на вопрос: "Является ли модель X красного цвета?" может быть получен ответ: "Да" или "Нет". Вопрос: "Какой цвет у модели Х?" ответа не имеет, так как в отношении отсутствует атрибут "цвет".
В итоге сформулируем основные свойства реляционной модели данных, которые следуют из понятия отношения как множества.
Все кортежи одного отношения должны иметь одно и то же количество атрибутов.Значение каждого из атрибутов должно принадлежать некоторому определенному домену.Каждое отношение должно иметь первичный ключ.Никакие два кортежа не могут иметь полностью совпадающих наборов значений.Каждое значение атрибутов должно быть атомарными, т.е. не должно иметь внутренней структуры и содержать в качестве компонента другое отношение.Реляционная модель данных должна быть непротиворечивой, в частности должен выполняться 1) принцип ссылочной целостности - связи между отношениями должны быть замкнутыми, 2) значения колонок должны принадлежать одному и тому же определенному для них домену.Порядок следования кортежей в отношении не имеет значения.Порядок есть в большей степени свойство хранения данных, чем свойство непосредственно самой реляционной модели данных.
Объединение отношений
Пусть Qa, Qb, Qc - множество кортежей отношений А, B, С соответственно. Операция объединения выполняется над двумя совместными отношениями A и B. Результатом операции объединения является отношение C, которое включает в себя все кортежи отношения А и кортежи отношения B, отличные от кортежей отношения A. Таким образом, объединение отношений можно представить с помощью теоретико-множественной операции объединения:

Пример. Объединение отношений. Выполним операцию объединения отношений КЛИЕНТ_1 и КЛИЕНТ_2.
Исходные отношения:
КЛИЕНТ_1 (#, Фамилия, Возраст) и КЛИЕНТ_2 (#, Фамилия, Возраст)
| 1 | Иванов | 20 | 1 | Иванов | 20 | |
| 3 | Петров | 23 | 2 | Исаев | 30 | |
| 4 | Фролов | 49 |
Результирующее отношение:
КЛИЕНТ (#, Фамилия, Возраст) = КЛИЕНТ_1 " КЛИЕНТ_2
| 1 | Иванов | 20 |
| 3 | Петров | 23 |
| 4 | Фролов | 49 |
| 2 | Исаев | 30 |
Пересечение отношений
Операция пересечения выполняется над двумя совместными отношениями А и В. Результатом операции пересечения является отношение С, которое включает в себя кортежи отношения А, полностью совпадающие с кортежами отношения В. Таким образом, пересечение отношений можно представить с помощью теоретико-множественной операции пересечения:

Пример. Пересечение отношений. Выполним операцию пересечения отношений КЛИЕНТ_1 и КЛИЕНТ_2.
Исходные отношения:
КЛИЕНТ_1 (#, Фамилия, Возраст) и КЛИЕНТ_2 (#, Фамилия, Возраст)
| 1 | Иванов | 20 | 1 | Иванов | 20 | |
| 3 | Петров | 23 | 2 | Исаев | 30 | |
| 4 | Фролов | 49 |
Результирующее отношение:
КЛИЕНТ (#, Фамилия, Возраст) = КЛИЕНТ_1 " КЛИЕНТ_2
| 1 | Иванов | 20 |
Понятие отношения
Реляционная модель данных была предложена Е.Ф. Коддом в 1970 году и получила к настоящему времени широкое распространение и популярность. Этому способствовали два ее существенных достоинства: 1) однородность представления данных в модели, которая обусловливает простоту восприятия ее конструкций пользователями базы данных, и 2) наличие развитой математической теории реляционных баз данных, которая обусловливает корректность ее применения.
В основе реляционной модели данных лежит понятие отношения, которое задается списком своих элементов и перечислением их значений. Рассмотрим пример на рис. 4.1. На нем представлено расписание движения автобусов по маршруту "Москва - Черноголовка - Москва". Налицо определенная структура. Каждый включенный в расписание рейс имеет свой номер, время отправления и время в пути. Расписание может быть представлено таблицей. Заголовки колонок таблицы носят название атрибутов. Список их имен носит названия схемы отношения. Каждый атрибут определяет тип представляемых им данных, который вместе с областью его значений называется доменом. Вся таблица целиком называется отношением, а каждая строка таблицы носит название кортежа отношения. Таким образом, отношение можно представить в виде двумерной таблицы.

Рис. 4.1. Расписание движения автобусов по маршруту "Москва - Черноголовка - Москва" как отношение
Подходы к определению понятия отношения могут быть различными. Математически отношение может быть определено как множество кортежей, являющейся подмножеством декартова произведения фиксированного числа областей (доменов). В результате получаем, что в каждом кортеже должно быть одинаковое число компонент (атрибутов) и значение каждого из них выбирается из некоторого определенного домена.
Введем ряд математических определений, связанных с понятием отношения.
Определение 1. Декартово произведение Пусть D1, D2, ..., Dn - произвольные конечные множества, не обязательно различные. Декартовым произведением этих множеств


Пример:

Определение 2. Схема отношения
Пусть


Определение 3. Отношение
Отношением со схемой r на конeчных множествах D1, D2,…, Dn называется подмножество R декартового произведения

Элементы отношения (d1, d2, ..., dn), как уже упоминалось выше, называются кортежами. О каждом отношении, являющимся подмножеством декартового произведения

Табличная форма представления отношения была введена в целях популяризации модели среди неподготовленных пользователей баз данных. Трактовка реляционной теории на уровне таблиц скрывает ряд определений, важных для понимания как теории реляционных баз данных, так и языка манипулирования данными, моментов.
Во-первых, атрибуты разных отношений могут быть определены на одном домене, так же как и атрибуты одного отношения. Это очень важное обстоятельство, позволяющее устанавливать связи по значению между отношениями. Во-вторых, множество математически по своему определению не может иметь совпадающих элементов, и, следовательно, кортежи в отношении можно различить лишь по значению их компонент. Это тоже очень важное для модели обстоятельство: никакие два кортежа не могут иметь полностью совпадающих компонент. Таким образом, в реляционной модели полностью исключается дублирование данных о сущностях реального мира! В-третьих, заметим, что схема отношения также есть множество, что позволяет работать с ними с помощью теоретико-множественных операций. Это является важным моментом для построения теории проектирования реляционных схем баз данных.
Существует определенное различие между математическим определением отношения и действительным хранением отношений в памяти компьютера. По определению, отношение не может иметь два идентичных кортежа. Однако СУБД, поддерживающие реляционную модель данных, хранят отношения в файлах операционной системы компьютера. Размещение отношений в файлах операционной системы допускает хранение идентичных кортежей. Если не используется специальная техника (контроль целостности по первичному ключу), то обычно большинство промышленных СУБД допускают хранение двух идентичных кортежей в базе данных.
С математической точки зрения однородность реляционной модели, о которой упоминалось выше, состоит в том, что схема отношения является постоянной, иначе говоря, каждая строка таблицы имеет один и тот же формат. С другой стороны, предполагается, что каждая строка таблицы представляет некую сущность реального мира или связь между ними. Обладают ли сущности реального мира такой однородной структурой, является вопросом, на который должен ответить аналитик или эксперт-пользователь. Решение о пригодности использования реляционной модели для моделирования данных конкретной предметной области решается руководителем ИТ-проекта и аналитиками.
Проекция отношения
Операция проекции выполняется над одним отношением А. Результатом выполнения операции проекции над отношением А является отношение С, которое включает в себя все кортежи отношения А, но только с теми атрибутами, на которые выполняется проекция. Операцию проекции отношения можно представить следующим образом:

Для обозначения проекции в теории реляционных баз данных принято использовать греческую букву

Таким образом, операция проекции заключается в удалении некоторых атрибутов в исходном отношении Qa и упорядочивании оставшихся атрибутов.
Пример. Проекция отношения. Выполним операцию проекции отношения СОТРУДНИК на атрибуты ОТДЕЛ и ДОЛЖНОСТЬ.
Исходное отношение: СОТРУДНИК (#, Фамилия, Отдел, Должность)
| 1 | Иванов | 12 | Инженер |
| 2 | Исаев | 11 | Гл.специалист |
| 3 | Петров | 11 | Инженер |
| 4 | Фролов | 11 | Инженер |
| 5 | Антонова | 12 | Конструктор |
Результирующее отношение:
ДОЛЖНОСТЬ (Отдел, Должность) = p (Отдел, Должность)
Разность отношений
Операция разности выполняется над двумя совместными отношениями А и В. Результатом операции разности является отношение С, которое включает в себя кортежи отношения А, отличные от кортежей отношения В. Таким образом, разность отношений можно представить с помощью теоретико-множественной операции разности:

Отметим для дальнейшего, что пересечение отношений можно представить через разность отношений как Qa - (Qa - Qb).
Пример. Разность отношений. Выполним операцию разности отношений КЛИЕНТ_1 и КЛИЕНТ_2.
Исходные отношения:
КЛИЕНТ_1 (#, Фамилия, Возраст) и КЛИЕНТ_2 (#, Фамилия, Возраст)
| 1 | Иванов | 20 | 1 | Иванов | 20 | |
| 3 | Петров | 23 | 2 | Исаев | 30 | |
| 4 | Фролов | 49 |
Результирующее отношение:
КЛИЕНТ (#, Фамилия, Возраст) = КЛИЕНТ_1 - КЛИЕНТ_2
| 3 | Петров | 23 |
| 4 | Фролов | 49 |
Реляционные операции
Классическая реляционная модель данных предусматривает использование восьми реляционных операций манипулирования данными: объединение, пересечение, разность, декартово произведение, деление, проекция, соединение и выбор. К операциям модели можно также отнести и операцию переименования кортежей в отношении.
Рассмотрим каждую из операций. Отметим, что операции выполняются над отношением в целом, а не над отдельным кортежем отношения. Введем несколько вспомогательных определений.
Определение 4. Степень отношения есть число входящих в него атрибутов или мощность схемы отношения (как множества).
Определение 5. Мощность отношения есть число входящих кортежей или кардинальное число отношения (как множества).
Определение 6. Два отношения называются совместными, если они имеют совместные схемы (совпадают схемы отношений и домены соответствующих атрибутов).
Соединение отношений
Операция q-соединения выполняется над двумя отношениями А и В. Результатом выполнения операции

Операция соединения отношений может быть представлена следующим образом:

где n - степень отношения Q_a;
Рассмотрим частные случаи
Если
Различают еще естественное соединение, когда оба отношения имеют набор одинаковых по именам и типам атрибутов. Соединение выполняется по всему набору совпадающих атрибутов. Пусть R1 (A1, A2,..., An, B1, ...) и R2 (A1, A2, ..., An, C1, ...) - исходные отношения, тогда естественное соединение может быть вычислено следующим образом для одного атрибута:
вычислим


Пример. Соединение отношений. Выполним операцию естественного соединения отношений ЭКЗАМЕН_ВЕДОМОСТЬ и ГРУППА по атрибуту "Группа".
Исходные отношения:
ЭКЗАМЕН_ВЕДОМОСТЬ (Студент, Дисциплина, Оценка, Группа)
| Иванов | Математика | 5 | 12 |
| Петров | Математика | 3 | 10 |
| Исаев | Математика | 4 | 1 |
| Антонова | Математика | 3 | 12 |
ГРУППА (Курс, Группа, Наименование)
| 5 | 10 | АСУ |
| 5 | 11 | Прикладная математика |
Результирующее отношение:
РЕЗУЛЬТАТ (Студент, Дисциплина, Оценка, Группа, Курс, Наименование)
| Петров | Математика | 3 | 10 | 5 | АСУ |
| Исаев | Математика | 4 | 11 | 5 | Прикладная математика |
Литература: [1], [2], [3], [4], [5], [6], [11], [14], [15], [16], [20], [37], [39], [42], [43], [44], [45], [47].
Выбор из отношения
Операция выбора (селекции) выполняется над одним отношением А. Результатом выполнения операции выбора является отношение С, которое включает в себя кортежи отношения А, удовлетворяющие заданному условию (критерию выбора). Операция выбора из отношения может быть представлена следующим образом:

где s обозначает операцию выбора, F - критерий выбора на множестве атрибутов в форме логического выражения, образованного с помощью определенных операндов (константы, имена атрибутов, арифметические операции сравнения, логические операции).
Пример. Селекция отношения. Произведем выбор из отношения СЛУЖАЩИЕ по критерию "Возраст >= 30".
Исходное отношение:
СЛУЖАЩИЕ (#, Фамилия, Возраст)
| 1 | Иванов | 20 |
| 2 | Исаев | 30 |
| 3 | Петров | 23 |
| 4 | Фролов | 49 |
| 5 | Антонова | 25 |
Критерий выбора: Возраст >= 30
Результирующее отношение:
СЛУЖАЩИЕ (#, Фамилия, Возраст)
| 2 | Исаев | 30 |
| 4 | Фролов | 49 |
Аксиомы вывода функциональных зависимостей
Известно, что функции могут образовывать пространства, и в пространствах выполняются различные операции. В нашем случае для каждой базы данных на множестве ее отношений можно рассмотреть все возможные, допустимые в семантическом смысле функциональные зависимости. Для каждого отношения существует вполне определенное множество ФЗ между его атрибутами. На практике число рассматриваемых атрибутов и ФЗ конечно (!).
Поскольку ФЗ являются высказываниями об атрибутах сущностей предметной области, то над ними могут быть определены операции, позволяющие логически получать одну зависимость из другой (или устанавливать между ними эквивалентность). Это позволяет определить для данной схемы базы данных базовый набор ФЗ, из которого может быть выведено все множество ФЗ, присущих этой схеме. Данное утверждение является третьей (3) конструктивной идеей в теории проектирования реляционных баз данных.
Математически эту задачу можно поставить следующим образом. Пусть U {A1, A2, ..., An} - универсальное множество атрибутов, т.е. полный набор атрибутов отношения базы данных. Совокупность пар (X, Y), таких, что

Например, транзитивную ФЗ в отношении r можно логически вывести из





Такие рассуждения позволяют ввести следующие определения.
Определение 7. Пусть F - множество ФЗ для схемы отношения r,
В примере выше мы видели, что если F содержит ФЗ из
Определение 8. Пусть F - множество ФЗ для схемы отношения r. Тогда замыканием F+ множества ФЗ F называется множество ФЗ, которое логически следует из F. F называется полным семейством ФЗ, если F+ = F.
Пример (без доказательства). Пусть

X содержит A, т.е.





Теперь можно уточнить понятие ключа отношения. Предполагается, что для сущностей предметной области существует множество атрибутов, которое уникально определяет каждую из этих сущностей. Понятие замыкания позволяет дать формальное определение ключу отношения.
Определение 9. Пусть F - множество ФЗ для схемы отношения R(A1, A2, ..., An). Подмножество атрибутов X называется ключом отношения R, если ФЗ:



Таким образом, заданный аналитиком ключ некоторого набора сущностей предметной области только тогда является ключом отношения, представляющего эти сущности в реляционной базе данных, когда он является минимальным ключом, т.е. содержит минимальное подмножество ключевых атрибутов. При определении ключа сущности предметной обычно невозможно установить свойство минимальности ввиду отсутствия формальной разработки для этой процедуры. На практике существует несколько наборов атрибутов сущности предметной области в качестве кандидатов на ключ отношения. Проектировщик базы данных может выбрать любой из них для идентификации отношения. Для того чтобы выделять ситуацию множественности в выборе ключа, для обозначения ключа сущности пользуйтесь термином возможный ключ.
Пример. Многозначность при выборе ключа
Легко убедиться, что оба множества атрибутов {город, адрес} и {адрес, почтовый_индекс} являются ключами отношения. Какой из них выбрать, решает проектировщик базы данных.
Для того чтобы определить ключи отношений и логические следствия ФЗ для заданной схемы отношения, необходимо вычислить F+ или для заданного F уметь определять, принадлежит ли данная ФЗ его замыканию F+. Для этого необходимо иметь набор правил - операций над ФЗ, позволяющих ими манипулировать.
Набор правил вывода должен быть полным, т.е. давать возможность вывести все зависимости из F+, и надежным, т.е. не позволять вывести зависимость из F, не принадлежащую F+. Таким образом, правила вывода, называемые также аксиомами вывода функциональных зависимостей, должны позволять вывести множество функциональных зависимостей, присущих рассматриваемой схеме отношения R(A1, A2, ..., Am) на заданном универсальном множестве атрибутов U по заданному множеству ФЗ F = {F1, F2, ..., Fk}.
Далее представлены восемь аксиом вывода функциональных зависимостей.
Рефлексивность. Если

















Используя три первых аксиомы вывода, покажем, что пара атрибутов {адрес, почтовый_индекс} из примера выше являются ключом отношения (город, адрес, почтовый_индекс), иначе имеет место ФЗ адрес, почтовый_индекс

Тогда по аксиоме транзитивности получаем адрес, почтовый_индекс
Можно доказать утверждение о том, что настоящие правила вывода позволяют по заданному множеству ФЗ F построить все зависимости, допускаемые на U. Таким образом, система правил вывода ФЗ 1-6 является надежной и полной.
Покажем, как можно доказать утверждение о полноте и надежности аксиом вывода. Аксиомы 1, 2 и 3 составляют независимое подмножество среди всех шести аксиом и называются аксиомами Армстронга. Из них можно вывести все остальные аксиомы. Поэтому надежность и полноту достаточно установить только для первых трех аксиом.
Надежность аксиом заключается в том, что если ФЗ

Для доказательства полноты аксиом вывода введем понятие замыкания множества атрибутов X относительно множества ФЗ F.
Определение 10. Пусть F - множество ФЗ на множестве атрибутов U и


Нетрудно показать, что ФЗ



Теперь, для того чтобы показать полноту аксиом 1-3, покажем, что если при заданном F ФЗ
Рассмотрим отношение R с двумя кортежами:
| 1 1 … 1 | 1 1 … 1 |
| 1 1 … 1 | 0 0 … 0 |


На основе аксиом вывода можно уточнить понятие замыкания множества ФЗ

Вычисление замыкания конечного множества ФЗ является трудоемкой задачей, так как необходимо перебрать множество всех подмножеств, а таких множеств, как известно, 2n, где n - число элементов исходного множества. Однако вычислить замыкание X+ для данного множества атрибутов несложно. Алгоритм вычисления приведен ниже. Можно показать, что этот алгоритм корректно вычисляет замыкание X+.
Алгоритм вычисления X+
Input: U - конечное множество атрибутов, множество ФЗ F на U, множество

Output: X+
Х0 есть Х.Xi+1 есть Xi плюс множество атрибутов А, для которых в F существует ФЗ

Условие завершения. Так как U - конечно и

Пример. Вычислим Х+
Пусть






Минимальные покрытия множеств функциональных зависимостей
Попытаемся теперь выяснить, какова роль F-зависимостей в реляционных базах данных. Как показали исследования, класс F-зависимостей оказывает существенное влияние на построение согласованных схем реляционных баз данных, определяет механизмы согласованности данных и целостности баз данных.
Одной из основных целей создания базы данных является сохранение всех данных и взаимосвязей между ними из предметной области в вычислительной среде. Табличное представление отношений в реляционных базах данных позволяет выдвинуть следующую гипотезу хранения данных - каждой ФЗ по отношению. Другой целью создания базы данных является надежность и целостность сохраняемых данных. Можно предположить, что табличное представление породит ряд проблем, связанных с восстанавливаемостью данных, и вступит в противоречие с требованием производительности базы данных. Поэтому меньшее число F-зависимостей означает меньший объем использования памяти компьютера и меньшее число проверок при операциях модификации.
В начале проектирования реляционных баз данных всегда возникает задача представления множеств F-зависимостей. Чем меньшим числом отношений их можно представить, тем лучше. Формализация решения этой задачи строится на понятии покрытия ФЗ. Построение покрытий множеств ФЗ является четвертой (4) конструктивной идеей в теории проектирования реляционных баз данных. Введем ряд определений.
Определение 11. Два множества F-зависимостей F и G над схемой r отношения R эквивалентны, если их замыкания совпадают, т.е. F+ = G+.
Эквивалентность двух множеств ФЗ F и G устанавливается следующим образом: для каждой ФЗ
Следствием введения понятия эквивалентности является следующий важный факт: каждое множество ФЗ покрывается некоторым множеством ФЗ, в которых ни одна из правых частей не имеет более одного атрибута (правила декомпозиции и объединения).
Таким образом, существует набор эквивалентных схем для каждой исходной схемы отношений реляционной базы данных.
Теория проектирования реляционных баз данных дает возможность построения более коротких представлений ФЗ. Для рассмотрения таких процедур введем понятия неизбыточных ФЗ и минимального покрытия множеств ФЗ.
Определение 12. Множество F-зависимостей F неизбыточно, если у него нет собственного подмножества, эквивалентного ему самому.
Определение 13. Множество F-зависимостей F минимально, если оно содержит не больше F-зависимостей, чем любое эквивалентное ему множество.
Минимальное покрытие (МП) не может содержать избыточных зависимостей. Понятие МП F можно детализировать следующим образом:
правая часть каждой ФЗ в F содержит один атрибут;ни для какой ФЗ




Доказано, что для каждого множества ФЗ F существует эквивалентное ему минимальное покрытие. Для заданного F может существовать несколько минимальных покрытий. Ниже приведены общие алгоритмы проверки избыточности и построения минимальных покрытий.
Алгоритмы проверки избыточности
Алгоритм REDUNDANT ( F ) input: Множество F output: True, если F избыточно 1. temp = false for any X
Алгоритм NONREDUN ( G ) input: Множество ФЗ G output: Неизбыточное покрытие G 1. F = G for any X
Основные классы функциональных зависимостей
Анализ связей между сущностями в предметных областях позволяет выделить различные классы функциональных зависимостей.
Для определения ФЗ предметной области часто бывает недостаточно определить все возможные ключи отношения. Значения атрибутов могут зависеть от ключа по-разному. Различают классы полных и частичных ФЗ. ФЗ может быть частичной, когда значение неключевого атрибута зависит от значений некоторых атрибутов составного ключа, и полной, когда значения неключевого атрибута зависят от значений всех атрибутов составного ключа.
Введем определение.
Определение 3. Говорят, что неключевой атрибут функционально полно зависит от составного ключа, если он функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа. Если неключевой атрибут зависит от части составного ключа, то говорят о частичной ФЗ.
Пример. Частичные и полные ФЗ
ПРЕПОДАВАТЕЛЬ_ПРЕДМЕТ (Личный номер, Предмет, Фамилия, Должность, Оклад, Часы)
| 1. | Иванов | доцент | 25000 | Математика | 40 |
| 2. | Исаев | доцент | 25000 | Физика | 50 |
| 3. | Фролов | профессор | 50000 | Химия | 30 |
Первичным ключом отношения ПРЕПОДАВАТЕЛЬ_ПРЕДМЕТ является пара атрибутов Личный_номер-Предмет. Значения атрибута Количество_часов зависят от значения атрибута Предмет, т.е. имеем частичную ФЗ Предмет
Рассмотрим проблему избыточности данных с точки зрения существования определенных функциональных зависимостей. Избыточность данных может проявляться в виде дублирования значений некоторых атрибутов. Так, например, если несколько преподавателей находятся на одной и той же должности, то их оклады могут совпадать. Атрибут Оклад частично зависит от ключа отношения, но однозначно определяется атрибутом Должность. Разделение исходного отношения на два новых отношения позволит исключить дублирование данных.
Таким образом, выявление определенных функциональных зависимостей в отношениях базы данных позволяет преобразовать их с целью исключения избыточности и повышения надежности данных.
Разбиение исходных отношений в соответствии с функциональными зависимостями - это вторая (2) конструктивная идея в теории проектирования реляционных баз данных. Формирование схем отношений путем разбиения исходных отношений по их атрибутам с учетом функциональных зависимостей является одним из способов создания хороших схем реляционных баз данных.
Каким образом можно использовать это наблюдение с учетом семантики данных для конструирования отношений? Имеет смысл разбить все возможные зависимости на определенные типы ФЗ, и на основе этой классификации проанализировать, какие типы ФЗ к каким аномалиям в выполнении реляционных операций приводят. Такой анализ может стать основой для построения алгоритмов проектирования реляционной базы данных.
Анализ связей между сущностями в предметных областях позволяет определить, наряду с частичной и полной ФЗ, еще несколько классов ФЗ. Одним из таких классов является класс транзитивных ФЗ.
Определение 4. Пусть X, Y, Z - атрибуты отношения R. Если при этом имеются ФЗ



Пример. Транзитивные ФЗ
Личный номер преподавателя определяет его должность, т.е. имеет место ФЗ Личный_номер
Очевидно, что семантическая связь между атрибутами отношения может носить неоднозначный характер, это порождает существование класса многозначных зависимостей (MV-зависимостей). Например, один преподаватель может преподавать несколько предметов, а один предмет может преподаваться несколькими преподавателями. Многозначная зависимость может быть следующих типов: 1:N (один ко многим), M:1 (многие к одному) и M:N (многие ко многим).
Определение 5. Пусть r - некоторая схема отношения, X и Y - подмножества атрибутов r.
Если при заданных значениях атрибутов из {X} существует некоторое множество, состоящее из нуля или более взаимосвязанных значений атрибутов из {Y}, никак не связанных со значениями других атрибутов этого отношения r - X - Y, то говорят о существовании многозначной зависимости между атрибутами X и Y:

Формально многозначная зависимость означает, что если в отношении

w[X] = v[X] = t[X] = s[X],w[Y] = t[Y], w[r - X - Y] = s[r - X - Y],v[Y] = s[Y], v[r - X - Y] = t[r - X - Y].
Фактически многозначная зависимость означает, что значения атрибутов из Y в кортежах t и s можно поменять местами и получить два новых кортежа, также принадлежащих отношению R.
Разделение установленных функциональных зависимостей по различным отношениям может привести к нарушению принципа замкнутости реляционных операций, потере некоторых существующих кортежей или появлению мнимых кортежей. Это обстоятельство приводит к необходимости выделения еще одного класса функциональных зависимостей - класса зависимостей по соединению (J-зависимостей). Этот класс ФЗ требует от ФЗ наличия свойства восстанавливаемости по своим проекциям с помощью естественного соединения.
Пусть U - универсальное отношение, полученное объединением всех атрибутов сущностей предметной области в одно отношение.
Определение 6. Пусть r = {r_1, …, r_p} - множество схем на U. Отношение R \subset U удовлетворяет зависимости по соединению, если R разлагается без потерь на r как

Процесс выделения новых классов функциональных зависимостей может быть продолжен. Он аналогичен классификации чисел в школьном курсе алгебры: натуральные числа
Однако для практических целей проектирования реляционных баз данных достаточно знания рассмотренных классов ФЗ. Даже зависимость по соединению встречается очень редко.
Понятие функциональной зависимости в данных
Оставим пока в стороне ответ на вопрос, почему проекты реляционных баз данных бывают плохими, т.е. зачем нужно проектировать реляционную базу данных. Попытаемся сначала ответить на вопросы "В чем заключается проектирование реляционных баз данных? и "Что лежит в основе процедур проектирования реляционных баз данных?"
Как известно, основной единицей представления данных в реляционной модели является отношение, которое математически задается списком имен атрибутов, иначе - схемой отношения. На стадии логического проектирования реляционной базы данных проектировщик определяет и выстраивает схемы отношений в рамках некоторой предметной области, а именно - представляет сущности, группирует их атрибуты, выявляет основные связи между сущностями. Так, в самом общем смысле проектирование реляционной базы данных заключается в обоснованном выборе конкретных схем отношений из множества различных альтернативных вариантов схем.
На практике построение логической модели базы данных, независимо от используемой модели данных, выполняется с учетом двух основных требований: исключить избыточность и максимально повысить надежность данных. Эти требования вытекают из требования коллективного использования данных группой пользователей. Формальных средств описания данных, необходимых для проверки правильности заполнения конструкций моделей, явно недостаточно. Выбор сущностей, атрибутов и фиксация взаимосвязей между сущностями зависит от семантики предметной области и выполняется системным аналитиком субъективно в соответствии с его личным пониманием специфики прикладной задачи. Разные люди определяют и представляют данные по-разному.
Поэтому любое априорное знание об ограничениях предметной области, накладываемых на взаимосвязи между данными и значения данных, и знания об их свойствах и взаимоотношениях между ними может сыграть определенную роль в соблюдении указанных выше требований. Формализация таких априорных знаний о свойствах данных предметной области базы данных нашла свое отражение в концепции функциональной зависимости данных, т.е.
Такая ФЗ обозначается как

Как видно из определения, функциональная зависимость инвариантна к изменению состояний базы данных во времени.
Пример. Понятие функциональной зависимости Продемонстрируем понятие функциональной зависимости на примере графика полетов аэропорта. ГРАФИК_ПОЛЕТОВ (Пилот, Рейс, Дата_вылета, Время_вылета)
| Иванов | 100 | 8.07 | 10:20 |
| Иванов | 102 | 9.07 | 13:30 |
| Исаев | 90 | 7.07 | 6:00 |
| Исаев | 100 | 11.07 | 10:20 |
| Исаев | 103 | 10.07 | 19:30 |
| Петров | 100 | 12.07 | 10:20 |
| Петров | 102 | 11.07 | 13:30 |
| Фролов | 90 | 8.07 | 6:00 |
| Фролов | 90 | 12.07 | 6:00 |
| Фролов | 104 | 14.07 | 13:30 |
каждому рейсу соответствует определенное время вылета;для каждого пилота, даты и времени вылета возможен только один рейс;на определенный день и рейс назначается определенный пилот.
Следовательно:
"Время_вылета" функционально зависим от "Рейс": "Рейс"
Важной задачей при выявлении функциональных зависимостей на атрибутах отношения, которое по определению является множеством, является выяснение, какой из атрибутов выступает как аргумент, а какой - как значение ФЗ. Наиболее подходящими кандидатами в аргументы ФЗ являются возможные ключи, так как кортежи представляют экземпляры сущности, которые идентифицируются значениями атрибутов своего ключа. Нестрого говоря, функциональная зависимость имеет место на отношении, когда значения кортежа на одном множестве атрибутов однозначным образом определяют значения кортежа на другом множестве атрибутов. Это рабочее определение ФЗ не содержит в себе тех формальных элементов, которые позволяют ответить на вопрос "А как проверить наличие ФЗ между атрибутами отношения?" Необходимый для этого формализм дает нам использование реляционных операций.
Для получения формального (строгого) определения н аличия ФЗ в отношении обратимся к реляционным операциям.
Определение 2. Пусть имеется отношение R со схемой r, X и Y - два подмножества R. ФЗ


Как видно из определения, формальная проверка наличия ФЗ
Алгоритм, который проверяет, удовлетворяет ли отношение R ФЗ
Ясно, что если семантика предметной области базы данных сложна, то проверить кортежи на принадлежность к ФЗ достаточно сложно. Сложно вообще установить наличие самой функциональной зависимости, отвечающей природе рассматриваемых данных. С помощью такого формального метода можно выявить ФЗ, которые не являются реальными и носят случайный характер. Проектировщику реляционных баз данных следует знать о таком методе проверки наличия ФЗ, но при проектировании новой базы данных его применение малоэффективно. Он может быть полезен при реинжиниринге существующей базы данных.
Функциональные зависимости фактически представляют собой утверждения обо всех отношениях предметной области. Эти отношения могут являться значениями схемы r и, в сущности, не могут быть получены формальными методами. Единственный способ установления функциональных зависимостей для схемы отношения r - это исследование семантики атрибутов сущностей предметной области. Являясь высказываниями о сущностях предметной области, они не могут быть доказаны. Это обстоятельство по существу порождает неединственность представления предметной области отношениями реляционной БД.
Здесь уместно высказать гипотезу о том, почему бывают хорошие и плохие проекты баз данных.Во-первых, в силу субъективности подходов к анализу предметной области аналитики могут упустить важные ФЗ. Это может привести к тому, что, работая на множестве заведомо неэквивалентных схем, проектировщик создаст неудовлетворительный проект базы данных. Во-вторых, неединственность представления предметной области отношениями приводит к проблеме выбора из множества альтернатив. При этом схема базы данных, выбранная из набора эквивалентных схем, является правильной, но может организовывать данные для пользователя непривычным образом. В-третьих, можно определить ("накроить") схемы баз данных таким образом, что в результате операций с ФЗ будут потеряны и ФЗ, и сами данные.
ограничений на возможные взаимосвязи между данными, которые могут быть текущими значениями схемы отношений.
Кортежи отношений могут представлять экземпляры сущности предметной области или фиксировать их взаимосвязь. Но даже если эти кортежи определены правильно, т.е. отвечают схеме отношения и выбраны из допустимых доменов, не всякий из них может быть текущим значением некоторого отношения. Например, возраст человека редко бывает более 120 лет, или один и тот же пилот не может одновременно выполнять два различных рейса. Такие ограничения семантики домена практически не влияют на выбор той или иной схемы отношений. Они представляют собой ограничения на типы данных.
Априорные ограничения предметной области на взаимосвязь значений отдельных атрибутов оказывают наибольшее влияние на процесс проектирования схем реляционных баз данных. Соответствие по значению определенных атрибутов различных отношений базы данных, т.е. зависимость их значений друг от друга, определяет показатели надежности и корректности сохраняемых данных при их коллективном и согласованном использовании.
Вспомним определение функции как соответствия множества аргументов определенным значениям из множества определения функции и способы задания функций: формула, график и перечисление (таблица). Нетрудно понять, что функциональную зависимость (ФЗ) можно определить на довольно широком классе объектов. Определение функции не накладывает никаких ограничений на множество аргументов и множество значений функции, кроме их существования и наличия соответствия между их элементами. Поскольку ФЗ можно задать таблично, а таблица есть форма представления отношения, то становится очевидной связь между ФЗ и отношением. Отношение может задавать ФЗ. Это утверждение является первой (1) конструктивной идеей, которая положена в основу теории проектирования реляционных баз данных.
Определение 1. Пусть r (A1, A2, ..., An) - схема отношения R, a X и Y - подмножества r. Говорят, что Х функционально определяет Y, если каждому значению атрибутов кортежа отношения из Х соответствует не более одного значения атрибутов того же кортежа отношения из Y.
Такая ФЗ обозначается как
Как видно из определения, функциональная зависимость инвариантна к изменению состояний базы данных во времени.
Пример. Понятие функциональной зависимости Продемонстрируем понятие функциональной зависимости на примере графика полетов аэропорта. ГРАФИК_ПОЛЕТОВ (Пилот, Рейс, Дата_вылета, Время_вылета)
| Иванов | 100 | 8.07 | 10:20 |
| Иванов | 102 | 9.07 | 13:30 |
| Исаев | 90 | 7.07 | 6:00 |
| Исаев | 100 | 11.07 | 10:20 |
| Исаев | 103 | 10.07 | 19:30 |
| Петров | 100 | 12.07 | 10:20 |
| Петров | 102 | 11.07 | 13:30 |
| Фролов | 90 | 8.07 | 6:00 |
| Фролов | 90 | 12.07 | 6:00 |
| Фролов | 104 | 14.07 | 13:30 |
каждому рейсу соответствует определенное время вылета;для каждого пилота, даты и времени вылета возможен только один рейс;на определенный день и рейс назначается определенный пилот.
Следовательно:
"Время_вылета" функционально зависим от "Рейс": "Рейс"
Важной задачей при выявлении функциональных зависимостей на атрибутах отношения, которое по определению является множеством, является выяснение, какой из атрибутов выступает как аргумент, а какой - как значение ФЗ. Наиболее подходящими кандидатами в аргументы ФЗ являются возможные ключи, так как кортежи представляют экземпляры сущности, которые идентифицируются значениями атрибутов своего ключа. Нестрого говоря, функциональная зависимость имеет место на отношении, когда значения кортежа на одном множестве атрибутов однозначным образом определяют значения кортежа на другом множестве атрибутов. Это рабочее определение ФЗ не содержит в себе тех формальных элементов, которые позволяют ответить на вопрос "А как проверить наличие ФЗ между атрибутами отношения?" Необходимый для этого формализм дает нам использование реляционных операций.
Для получения формального (строгого) определения н аличия ФЗ в отношении обратимся к реляционным операциям.
Определение 2. Пусть имеется отношение R со схемой r, X и Y - два подмножества R. ФЗ
Как видно из определения, формальная проверка наличия ФЗ
Алгоритм, который проверяет, удовлетворяет ли отношение R ФЗ
Ясно, что если семантика предметной области базы данных сложна, то проверить кортежи на принадлежность к ФЗ достаточно сложно. Сложно вообще установить наличие самой функциональной зависимости, отвечающей природе рассматриваемых данных. С помощью такого формального метода можно выявить ФЗ, которые не являются реальными и носят случайный характер. Проектировщику реляционных баз данных следует знать о таком методе проверки наличия ФЗ, но при проектировании новой базы данных его применение малоэффективно. Он может быть полезен при реинжиниринге существующей базы данных.
Функциональные зависимости фактически представляют собой утверждения обо всех отношениях предметной области. Эти отношения могут являться значениями схемы r и, в сущности, не могут быть получены формальными методами. Единственный способ установления функциональных зависимостей для схемы отношения r - это исследование семантики атрибутов сущностей предметной области. Являясь высказываниями о сущностях предметной области, они не могут быть доказаны. Это обстоятельство по существу порождает неединственность представления предметной области отношениями реляционной БД.
Здесь уместно высказать гипотезу о том, почему бывают хорошие и плохие проекты баз данных.Во-первых, в силу субъективности подходов к анализу предметной области аналитики могут упустить важные ФЗ. Это может привести к тому, что, работая на множестве заведомо неэквивалентных схем, проектировщик создаст неудовлетворительный проект базы данных. Во-вторых, неединственность представления предметной области отношениями приводит к проблеме выбора из множества альтернатив. При этом схема базы данных, выбранная из набора эквивалентных схем, является правильной, но может организовывать данные для пользователя непривычным образом. В-третьих, можно определить ("накроить") схемы баз данных таким образом, что в результате операций с ФЗ будут потеряны и ФЗ, и сами данные.
Четвертая нормальная форма
Отношение находится в четвертой нормальной форме (4НФ), если оно находится в 3НФ или НФБК и все независимые многозначные ФЗ разнесены в отдельные отношения с одним и тем же ключом. Иными словами, 4НФ применяется при наличии в отношении более чем одной многозначной ФЗ и требует, чтобы отношение не содержало независимых многозначных ФЗ.
Пример. Приведение к 4НФ
Рассмотрим отношение, содержащее сведения о кораблях (Ship), совершаемых ими рейсах (Voyage) и капитанах (Captain) (задано таблицей 6.3). Отношение представлено в таблице ниже и на рис. 6.6.
| Акбар | Иванов | Санкт-Петербург - Калининград |
| Акбар | Петров | Санкт-Петербург - Калининград |
| Акбар | Ивлев | Санкт-Петербург - Калининград |
| Акбар | Прохоров | Санкт-Петербург - Калининград |
| Акбар | Лазарев | Санкт-Петербург- Лондон |
| Акбар | Прохоров | Санкт-Петербург- Лондон |
| Жучка | Петров | Санкт-Петербург - Марсель |
| Жучка | Фролов | Санкт-Петербург - Стокгольм |
| Жучка | Ивлев | Санкт-Петербург - Стокгольм |

Рис. 6.6. Отношение с многозначными зависимостями
Отношение находится в НФБК и содержит только многозначные ФЗ. Однако имеет место аномалия удаления: если капитан Петров уйдет в отставку и все кортежи о нем будут удалены, то будут потеряны сведения о том, что корабль Жучка совершает рейсы Санкт-Петербург - Марсель. Если добавить новый рейс, то, возможно, придется ввести несколько кортежей в наше отношение.
Приведение отношения к 4НФ заключается в выделении для каждой многозначной ФЗ своего отношения, как показано на рис. 6.7.

Рис. 6.7. Отношение в 4НФ
Таким образом, процедура приведения отношения к 4НФ сводится к выполнению нескольких проекций, в данном случае двух проекций.
Нормализация отношений
Нормализация отношений информационной модели предметной области является механизмом создания логической модели реляционной базы данных.
Заметим, что с математической точки зрения задача построения как информационной модели предметной области, так и логической модели реляционной базы данных является результатом решения следующих комбинаторных задач:
группировка атрибутов в отношении предметной области;распределение атрибутов по отношениям базы данных.
Такие задачи имеют решения, допускающие большое число вариантов, и приводят к проблеме выбора рационального варианта из множества альтернативных вариантов схем отношений. Выбор наиболее рационального варианта обусловлен соблюдением различного рода соглашений и требований.
Перечень наиболее важных требований приведен ниже.
Первичные ключи отношений должны быть минимальными (требование минимальности первичных ключей).Число отношений базы данных должно по возможности давать наименьшую избыточность данных (требование надежности данных).Число отношений базы данных не должно приводить к потере производительности системы (требование производительности системы).Данные не должны быть противоречивыми, т.е. при выполнении операций включения, удаления и обновления данных их потенциальная противоречивость должна быть сведена к минимуму (требования непротиворечивости данных).Схема отношений базы данных должна быть устойчивой, способной адаптироваться к изменениям при ее расширении дополнительными атрибутами (требование гибкости структуры базы данных). Разброс времени реакции на различные запросы к базе данных не должен быть большим (требование производительности системы).Данные должны правильно отражать состояние предметной области базы данных в каждый конкретный момент времени (требование актуальности данных).
Создание системы, одновременно удовлетворяющей всем вышеназванным требованиям, представляет собой сложную оптимизационную задачу, которая подчас не имеет однозначного решения. Многие из требований находятся в противоречии друг к другу.
Так, например, требование производительности находится в противоречии к требованию гибкости. Требование минимизировать число отношений в базе данных находится в противоречии к требованию надежности данных.
В процессе эксплуатации реляционной базы данных происходит модификация данных: в отношениях добавляются или удаляются кортежи, в результате определенных событий изменяются значения некоторых атрибутов кортежей и т.п. После манипулирования данными значения некоторых атрибутов могут дублироваться, порождая избыточность данных, значения некоторых атрибутов могут удаляться, исчезая из базы данных, хотя потребность в этих значениях остается, некоторые значения атрибутов не могут быть добавлены, поскольку их значения неизвестны, т.е. данные в базе данных с течением времени становятся несогласованными и противоречивыми. Потенциальная противоречивость (или аномалии) при выполнении операций манипулирования данными в базе данных зависит как от типа ФЗ между атрибутами, так и от группировки этих атрибутов по отношениям.
Рассмотрим типичные примеры аномалий, возникающих при выполнении операций включения, удаления и модификации данных.
Пример. Аномалии операций над базой данных
ПОСТАВКИ (Поставщик, Адрес, Товар, Количество, Стоимость)
Обновление. Если Поставщик поставляет несколько видов товара, то значение атрибута Адрес повторяется для каждого кортежа и, следовательно, при изменении адреса поставщика необходимо изменить значение этого атрибута во всех этих кортежах. Иначе будет нарушена целостность данных базы данных.
Удаление. Если Поставщик прекращает поставку товаров на некоторое время, то кортежи со всеми его поставками удаляются. При этом происходит потеря реквизитов поставщика - Адреса и Наименования.
Вставка. Если договор на поставку уже заключен, а поставка еще не произведена, то невозможно включить в рассматриваемое отношение значения атрибутов Поставщик и Адрес, поскольку нет сведений о поставках (проблема интерпретации нуль-значений).
Подобные аномалии в данных лишь отчасти дают ответ на вопрос, почему логическая структура реляционной БД может быть неудовлетворительной.
Некоторые проблемы избыточности данных можно разрешить, заменив, например, исходное отношение ПОСТАВКИ на два новых отношения - отношение ПОСТАВЩИК (Поставщик, Адрес) и отношение ПОСТАВКА (Поставщик, Товар, Количество, Стоимость). Однако в целом остается ряд вопросов, на которые теория реляционных баз данных не дает удовлетворительных ответов: quot;Как найти хорошую замену для плохой схемы отношений? Как определить, является ли выбранная замена выгодной? Как создать схему, обеспечивающую наилучшую производительность?quot;
Например, для того чтобы выполнить запрос, использующий данные из двух таблиц, необходимо построить соединение этих таблиц, которое является дорогостоящей операцией с физической базой данных с точки зрения числа выполняемых операций ввода/вывода.
Теория функциональных зависимостей позволяет установить определенные требования к схемам отношений в реляционной базе данных. Эти требования формулируются в терминах свойств отношений и называются нормальными формами схем отношений. Каждая нормальная форма отношений связана с определенным классом ФЗ, которые представлены в отношениях. Понятно, что одним из очевидных способов устранения потенциальной противоречивости данных в отношениях логической модели реляционной базы данных является их разбиение на два или более отношений, в каждом из которых присутствует только одна ФЗ.
Это возможно, поскольку теория ФЗ утверждает, что существует минимальное покрытие множества ФЗ базы данных, т.е. минимальный набор ФЗ, из которых можно вывести все остальные. Каждой ФЗ из минимального покрытия можно отвести по самостоятельному отношению. Однако, во-первых, для заданного множества ФЗ может существовать несколько минимальных покрытий (выбор среди возможных альтернатив), и, во-вторых, для практики важно иметь наглядный способ построения минимального покрытия.
Процесс устранения потенциальной противоречивости и избыточности данных в отношениях реляционной базы данных называется нормализацией исходных схем отношений. Нормализация отношений заключается в выполнении декомпозиции или синтеза отношений, назначении ключей отношений в соответствии с определенными правилами, гарантирующими целостность отношений базы данных.
Требование минимальности числа отношений, т.е. построения минимального покрытия ФЗ обычно является опциональным. На минимальном покрытии, как правило, не может быть достигнута высокая производительность обработки запросов.
Почему нормализация схем отношений важна для проектирования реляционных баз данных? Многочисленные испытания показали, что нормализация схем отношений дает наилучший результат при моделировании предметной области с использованием реляционной модели данных; при этом не вводится большого числа ограничений, не искажаются данные. Таким образом, нормализация отношений является методом удаления из отношения ФЗ, которые приводят к аномалиям модификации данных. Иными словами, нормализация отношений помогает проектировать реляционную базу данных, которая не содержит избыточных данных и гарантирует их целостность.
Язык нормальных форм констатирует наличие или отсутствие определенных ФЗ в отношениях реляционной базы данных и указывает на уровень избыточности и надежности данных в нормализованных отношениях. Методы нормализации отношений основываются на применении понятия ФЗ и способов манипулирования ими. При выполнении реляционных операций над отношениями в базе данных каждый тип ФЗ может порождать определенный тип аномалий, который будет нарушать целостность данных в базе данных. Нормальная форма (НФ) представляет собой ограничение на схему базы данных, вводимое с целью устранения определенных нежелательных свойств при выполнении реляционных операций.
Различают несколько типов нормальных форм. Каждая из них ограничивает присутствие определенного класса ФЗ в отношении и устраняет присущие этому классу ФЗ аномалии в выполнении реляционных операций.
Примечание. Глагол quot;ограничиваетquot; в терминологии баз данных означает набор процедур, направленных на достижение определенных свойств объекта путем сужения области его действия.
Нормальная форма Бойса-Кодда
3НФ упрощает решение проблем контроля избыточности данных, интерпретации нуль-значений, контроля за операциями модификации данных, только если в отношениях отсутствуют какие-либо другие ФЗ, в частности обратные ФЗ неключевого атрибута на один из атрибутов составного первичного ключа или многозначные ФЗ. В противном случае вышеперечисленные проблемы остаются неразрешенными. Для устранения таких проблем, связанных с существованием обратных ФЗ неключевых атрибутов на часть составного ключа, была предложена усиленная 3НФ или НФ Бойса-Кодда.
Отношение находится в нормальной форме Бойса-Кодда (НФБК), если оно находится в 3НФ, и в нем отсутствовали зависимости ключевых атрибутов от неключевых атрибутов. Иными словами, НФБК допускает наличие только таких нетривиальных ФЗ, в которых ключ определяет один или более других атрибутов:

Таким образом, схема отношения в НФБК обладает теми же достоинствами, что и схема в 3НФ, но устраняет некоторые дополнительные аномалии, не устраняемые 3НФ. Например, в отношение (Город, Адрес, Почтовый_индекс), находящееся в 3НФ, невозможно записать кортеж для города с известным почтовым индексом, если не известен адрес с этим почтовым индексом. Данное отношение не находится в НФБК, так как имеет место ФЗ Почтовый_индекс
Замечание. В отличие от 3НФ, исходные отношения не всегда могут быть приведены в НФБК. Пример. Приведение отношения к НФБК
Продолжим рассмотрение примеров из области судоходства.
Допустим, что экипаж судна разделен на команды, каждая из которых отвечает за разные виды работ. Члены экипажа могут входить в разные команды, но в каждую команду входит только один руководитель. Команда может иметь несколько руководителей. Каждый член экипажа может руководить только одной командой. Отношение задается таблицей 6.1 ниже:
| Иванов | Наблюдение | Прохоров |
| Иванов | Питание | Макаров |
| Петров | Наблюдение | Леонтьев |
| Модин | Наблюдение | Прохоров |
| Васин | Питание | Лазарев |
| Фролов | Обслуживание | Сидоров |
| Ивлев | Обслуживание | Сидоров |
Отношение находится в 3НФ, однако содержит аномалию удаления. Если Петрова удалить из команды наблюдения, то будет потеряна информация о том, что Леонтьев является руководителем команды наблюдения, и при назначении нового члена экипажа в команду наблюдения не будет известно, что у нее есть еще один руководитель, кроме Прохорова.
Заметим, что в предыдущих случаях разбиение отношений происходило без создания избыточности данных из-за обратной зависимости атрибута на часть ключа. Приведение отношения к НФБК заключается в создании дополнительного отношения, содержащего сведения о руководителях команд (таблица 6.2).
| Наблюдение | Прохоров |
| Питание | Макаров |
| Наблюдение | Леонтьев |
| Питание | Лазарев |
| Обслуживание | Сидоров |

Рис. 6.5. Отношение в НФБК
Первая нормальная форма
Отношение находится в первой нормальной форме (1НФ), если все атрибуты отношения являются простыми (требование атомарности атрибутов в реляционной модели), т.е. не имеют компонентов. Иными словами, домен атрибута должен состоять из неделимых значений и не может включать в себя множество значений из более элементарных доменов. Так, например, дата не может считаться простым атрибутом. В большинстве случаев выполнить это требование достаточно просто. Каждый простой атрибут должен иметь свою колонку в таблице. Однако это часто приводит к дублированию данных в отношении.
Типичным примером неатомарности атрибута являются так называемые повторяющиеся группы, представляющие массив значений атрибута.
Пример. Приведение отношения к 1НФ
На рис. 6.1 представлено ненормализованное отношение SHIPMENT (ОТГРУЗКА). Оно содержит повторяющиеся группы, представляющие массив значений, 1st Consignments, 2st Consignments, 3st Consignments (партии грузов). Атрибуты, характеризующие партию грузов (показаны на следующем рисунке), - Consignee (грузополучатель), Insured Value (застрахованная стоимость) и Declared Value (объявленная стоимость), - повторяются для каждой такой партии. Отметим, что для такого отношения следует ввести бизнес-правило, требующее, чтобы груз состоял не более чем из трех партий, поскольку четвертую партию вставить в этом отношении некуда.

Рис. 6.1. Ненормализованное отношение
Использование отношения, представленного не в 1НФ, может породить следующие проблемы:
если груз аннулируется и строка, связанная с грузом, удаляется из отношения, то вместе с ней удаляются все сведения о партиях груза на борту судна;если на склад прибывает новая партия груза, и она еще не включена в состав груза, подлежащего отправке, то сведения о партии заносить некуда;необходимо вводить ограничение: в грузе не может быть более трех партий.
Приведение отношения SHIPMENT к 1НФ заключается в изъятии данных о партиях груза из отношения SHIPMENT и создании для них связанного подчиненного отношения CONSIGNMENT (ПАРТИЯ_ГРУЗА). Результат приведения отношения SHIPMENT к 1НФ представлен на рис. 6.2. Для такого представления сущности SHIPMENT не требуется вводить ограничительное бизнес-правило, о котором упоминалось выше.

Рис. 6.2. Отношение в 1НФ
Таким образом, процедура приведения отношения к 1НФ состоит в вынесении неатомарных атрибутов в отдельное подчиненное отношение, т.е. в выполнении двух проекций.
Пятая нормальная форма
Как можно заметить, нормализация отношений выполнялась путем разложения (декомпозиции) схем отношений. Очевидно, что при таком подходе должен соблюдаться принцип обратимости: соединение проекций должно приводить к исходным отношениям. Это предполагает отсутствие потери кортежей; появление ранее не существовавших кортежей; сохранение ФЗ (семантика взаимосвязей между данными не должна нарушаться).
Декомпозиция схем отношений не всегда гарантирует обратимость. Это обстоятельство связано с существованием класса ФЗ по соединению. Если отношение удовлетворяет ФЗ по соединению, то оно может быть восстановлено по своим проекциям. Отношения, содержащие более трех МФЗ, требуют особого внимания при построении логической модели реляционной базы данных. Также 4НФ не устраняет избыточность данных полностью, поэтому требуется дальнейшая декомпозиция схем отношений.
Отношение находится в пятой нормальной форме (5НФ), если оно находится в 4НФ и удовлетворяет зависимости по соединению относительно своих проекций. 5НФ называют также нормальной формой с проецированием соединений. Она используется для разрешения трех и более отношений, которые связаны более чем тремя ФЗ по типу quot;многие-ко-многимquot;.
Пример. Приведение к 5НФ
Рассмотрим отношение с несколькими многозначными зависимостями, представленное на рис. 6.8.
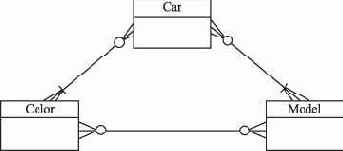
Рис. 6.8. Отношение с несколькими многозначными зависимостями
Рассмотрим сначала это отношение как три изолированных отношения со степенью связи quot;многие-ко-многимquot;:

Каждый автомобиль имеет определенный цвет и модель. Некоторые цвета характерны только для определенных моделей. Такие отношения разрешаются введением связывающих отношений, в данном случае таких отношений три:

Предположим, что клиент желает приобрести автомобиль синего цвета модели С, при этом марка автомобиля роли не играет. Запрос к базе данных на поиск такого автомобиля будет содержать два соединения между тремя таблицами Car, Car Color и Car Model по атрибуту наименование машины и два предиката: цвет = синий и модель = С.
Результат выполнения запроса будет удивителен: есть и Волга, и Жигули! Однако из таблицы Model Color видно, что автомобиля синего цвета модели С не существует. Появляется несуществующий кортеж. Такое явление представляет собой аномалию проецирования соединений и пример нарушения 5НФ.
Приведение отношения к 5НФ заключается во введении еще одного отношения, связывающего три исходных отношения, как показано на рис. 6.9.

Рис. 6.9. Отношение в 5НР
Таким образом, процедура приведения отношения, содержащего многозначные ФЗ, к 5НФ состоит в построении связывающего отношения, позволяющего исключить появление в соединениях ложных кортежей.
Следовательно, каждая нормальная форма ограничивает определенный тип ФЗ и устраняет аномалии обработки данных. Нормальные формы характеризуются следующими свойствами:
1НФ - все атрибуты отношения простые;2НФ - отношение находится в 1НФ и не содержит частичных ФЗ;3НФ - отношение находится во 2НФ и не содержит транзитивных ФЗ от ключа;НФБК - отношение находится в 3НФ и не содержит ФЗ ключей от неключевых атрибутов;4НФ, применяется при наличии более чем одной многозначной ФЗ - отношение находится в НФБК или 3НФ и не содержит независимых многозначных ФЗ;5НФ - отношение находится в 4НФ и не содержит ФЗ по соединению.
Литература: [2], [3], [15], [14], [16], [20], [31], [37], [39], [43], [44], [45].
Понятие о логической модели реляционной базы данных
Теперь, когда определены понятия отношения и операции над отношениями, уточним интуитивно используемое определение реляционной базы данных и ее схемы.
Определение 1. Под реляционной базой данных принято понимать совокупность экземпляров конечных отношений. Совокупность схем отношений образует схему реляционной базы данных.
Схема реляционной базы данных является логической моделью реляционной базы данных.
Как уже было сказано в лекции 2 - "Предметная область базы данных и ее модели", - на основе информационной модели в процессе проектирования создаются логическая и физическая модели данных. Информационная модель данных отражает потребности системы в данных и связи между данными с точки зрения их потребителей - пользователей; логическая модель данных является независимым логическим представлением данных; физическая модель данных содержит определения всех реализуемых объектов в конкретной базе данных для конкретной СУБД.
На практике часто рассматривают только две модели - логическую и физическую модели данных. При этом информационная и логическая модели данных не различаются и считаются синонимами. В рамках такого подхода некоторые специалисты в области баз данных считают, что информационная модель данных должна быть нормализована. Это означает, что проектировщики баз данных должны требовать от аналитиков, чтобы они приводили информационную модель данных к третьей нормальной форме! Такой подход имеет ряд недостатков. Во-первых, аналитики, являясь экспертами в предметной области, как правило, не представляют, что такое нормализация данных. Во-вторых, информационная модель данных должна быть независимой от физической модели данных, в рамках которой она будет реализовываться. Для реализации информационной модели данных может быть выбрана не реляционная, а, например, сетевая (СУБД ADABAS) или многомерная (СУБД Teradata) модели данных, тогда нормализация отношений модели не столь актуальна. В-третьих, проектировщики базы данны х должны иметь логическое представление данных, посредством которого, с одной стороны, общаться с аналитиками и пользователями в понятных для них терминах, и, с другой стороны, превращать полученные логические отношения в физические объекты базы данных.
Поэтому в настоящем курсе рассматривается три уровня моделей данных, а процесс нормализации информационной модели данных считается составной частью процесса создания логической модели данных, которую предполагается реализовать на реляционной СУБД.
На практике при построении логической модели реляционной базы данных особое значение для решения задачи формирования отношений базы данных имеет понятие функциональной зависимости (ФЗ). Установление ФЗ и получение наилучшего с точки зрения минимальности представления множества ФЗ позволят построить наиболее оптимальный вариант базы данных, обеспечивающий надежность хранения и обработки данных на основе методов эквивалентных преобразований схем отношений реляционной базы данных.
Процесс решения такой задачи называется нормализацией отношений информационной модели предметной области и заключается в превращении ее объектов в логические таблицы базы данных.
Третья нормальная форма
Отношение находится в третьей нормальной форме (3НФ), если оно находится во 2НФ, и все неключевые атрибуты отношения зависят только от первичного ключа. Иными словами, 3НФ требует, чтобы отношение не содержало транзитивных ФЗ неключевых атрибутов от ключа.
Формально это требование можно сформулировать следующим образом: схема отношения R находится в 3НФ, если не существует ключа Х для R, множества атрибутов


ФЗ представляют не только ограничения целостности, налагаемые на отношения, но и связи между атрибутами, если они (связи) сохраняются в базе данных. Если отношение содержит частичную зависимость

Наличие транзитивной зависимости

Пример. Приведение отношения к 3НФ
Вновь обратимся к рассмотрению отношения SHIPMENT, представленного на рис. 6.3. Оно содержит транзитивную ФЗ: атрибут Customs Declaration (таможенная декларация) является по своей сути свойством атрибутов Origin (пункт отправления) и Destination (пункт назначения). Результат приведения отношения SHIPMENT к 3НФ представлен на рис. 6.4.

Рис. 6.4. Отношение в 3НФ
Таким образом, процедура приведения отношения к 3НФ состоит в выполнении двух проекций: проекции по правой части транзитивной ФЗ и проекции по левой части транзитивной ФЗ.
Вторая нормальная форма
Будем считать атрибут отношения ключевым, если он является элементом какого-либо ключа отношения. В противном случае атрибут будет считаться неключевым атрибутом. Так в отношении (Город, Адрес, Почтовый_индекс) все атрибуты являются ключевыми, поскольку при заданных ФЗ город, адрес
Отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ, и все неключевые атрибуты отношения функционально полно зависят от составного ключа отношения. Иными словами, 2НФ требует, чтобы отношение не содержало частичных ФЗ.
Пример. Приведение отношения ко 2НФ
Вновь обратимся к рассмотрению отношения SHIPMENT, представленного на рис. 6.2. Оно содержит частичную ФЗ: неключевой атрибут Ship Capacity (грузоподъемность корабля) не зависит от ключевого атрибута Departure Date (даты убытия), а зависит от ключевого атрибута Ship Registration Number (регистрационный номер корабля).
Использование отношения, представленного не во 2НФ, может породить следующие проблемы:
невозможно занести в базу данных название и грузоподъемность корабля, который не доставил еще ни одного груза, - можно только ввести для него фиктивный груз;если удалить кортеж из отношения Shipment после отправки груза, то потеряются все данные о кораблях, для которых в настоящее время нет груза;невозможно отразить факт переоборудования корабля и получения им новой грузоподъемности; если переписать все предыдущие кортежи об этом корабле, то получится, что он в прошлом плавал недогруженным или перегруженным.
Приведение отношения SHIPMENT ко 2НФ заключается в изъятии атрибутов частичной ФЗ из отношения SHIPMENT и создании для нее связанного подчиненного отношения SHIP. Результат приведения отношения SHIPMENT ко 2НФ представлен на рис. 6.3.

Рис. 6.3. Отношения во 2НФ
Таким образом, процедура приведения отношения ко 2НФ состоит в выполнении двух проекций: проекции без атрибутов частичной ФЗ и проекции на часть составного ключа и те атрибуты, которые от него зависят.
Алгоритм метода декомпозиции отношений
Теперь нам известно, с чего начать нормализацию - с универсального отношения; что проверить - нахождение исходного отношения в НФБК; что предпринять - декомпозицию исходного отношения на два других отношения; и когда остановиться - все отношения базы данных в НФБК. Таким образом, можно сформулировать общий алгоритм проектирования логической модели реляционной базы данных методом декомпозиции:
Алгоритм метода декомпозиции отношений
Алгоритм
Разработка универсального отношения для базы данных.Определение всех ФЗ между атрибутами отношения.Определение, находится ли отношение в НФБК. Если да, то завершить проектирование; в противном случае отношение должно быть разбито на два других отношения.Повторение пунктов 2 и 3 для каждого нового отношения, полученного в результате декомпозиции.
Уточним некоторые аспекты метода декомпозиции.
Во-первых, как выполнить декомпозицию отношения на два отношения. Пусть отношение R(A, B, C, D, ...) содержит ФЗ

Во-вторых, каков критерий выбора ФЗ для выполнения проекции (далее мы увидим, насколько это может быть существенно). Понятно, что в качестве кандидатов для осуществления проекции следует отбирать ФЗ с детерминантами в левой части. Однако зависимости с детерминантами могут носить транзитивный характер, и здесь полезно применить первое эмпирическое правило выбора ФЗ для выполнения проекции - "правило цепочки". Правило цепочки состоит в следующем:
Если

Алгоритм метода синтеза отношений
В данном разделе приводится лишь некоторый обзор алгоритма синтеза отношений.
Мы уже рассматривали примеры декомпозиции с потерей ФЗ. Причиной потери ФЗ является некоторая ФЗ

На пути решения этой проблемы было бы неплохо усилить все ФЗ, связав их с уникальными ключами, скажем, описывая для них уникальные индексы. Тогда можно контролировать целостность базы данных. Для этого нужно усилить минимальное покрытие. Грубо говоря, усиливаемость минимального покрытия означает, что выделено множество первичных ключей и все ФЗ из минимального покрытия пересмотрены в призме этого множества с точки зрения выводимости ФЗ рассматриваемой базы данных.
Введем определение.
Определение 4. Реляционная база данных называется полной, если: все ФЗ усилены ключами;все отношения находятся в 3НФ;не существует варианта базы данных с меньшим числом схем, удовлетворяющим вышеперечисленным свойствам.
Почти всегда в предметной области базы данных можно выделить набор отношений, обладающих свойством полноты. Доказана теорема [Мейер], что существует алгоритм, который выводит полную базу данных из множества заданных ФЗ.
Поскольку такой алгоритм строит схему базы данных непосредственно из заданного набора ФЗ, он называется алгоритмом синтеза базы данных. При этом на первый план выступает проблема правильного представления отношения с заданной схемой своими проекциями, т.е. соединения по результирующей схеме базы данных могут оказаться ложными. Однако если минимальное покрытие исходного набора ФЗ будет усилено, то подобного явления можно избежать.
Пример. Универсальный ключ и ложные соединения

Пусть отношение R имеет кортежи:
| 1 1 1 1 | 4 1 2 2 |
Случай 1.
Отсутствие ложных соединений
Разбиение на отношения
R1=ABC и R2=BCD
Случай 2. Наличие ложных соединений
Разбиение на отношения
R1 = AB и R2= BCD
ABCD
| 1 1 1 1 | 1 1 2 2 |
| 4 1 1 1 | 4 1 2 2 |

AC
Заметим, что атрибут А выступает в качестве ключа практически во всех ФЗ. Выделенный или добавленный атрибут, обладающий подобным свойством, называется универсальным ключом. Таким образом, решение проблемы ложных соединений заключается в добавлении подсхемы, которая содержит универсальный ключ, и выполнении соединения с ее использованием.
Теперь можно перейти к обзору алгоритма синтеза реляционной базы данных.
Теоретически показано, что для того, чтобы синтезировать полную базу данных, необходимо построить кольцевое минимальное покрытие для исходного набора ФЗ.
Введем некоторые обозначения. Составной ФЗ называется ФЗ:


В принятых обозначениях основные этапы алгоритма синтеза отношений приведены ниже.
Алгоритм поэтапного синтеза отношений
Вход: F - множество ФЗ предметной области базы данных
Выход: схема полной базы данных
Этап 1. Нахождение неизбыточного покрытия F1 для F
Для каждой ФЗ из F проверяется, может ли данная ФЗ быть выведена из оставшихся ФЗ. Если да, то ФЗ удаляется. Этап завершается после перебора всех ФЗ из F. В результате выполнения этапа получается множество ФЗ F1.
Этап 2. Сокращение слева элементов F1
Удаляются последовательно один за другим атрибуты из левых частей ФЗ F1; проверяется, может ли полученная ФЗ быть выведена из исходных ФЗ F1. Если да, то исходная ФЗ заменяется на новую ФЗ. Этап завершается после перебора всех ФЗ F1.
В результате получается множество ФЗ F2.
Этап 3. Сокращение справа элементов F2
Удаляются последовательно один за другим атрибуты ФЗ из правых частей ФЗ F2; проверяется, может ли исходная ФЗ быть выведена из полученной ФЗ и имеющихся ФЗ F2. Если да, то исходная ФЗ заменяется на новую ФЗ. Этап завершается после перебора всех ФЗ F2. В результате получается множество ФЗ F3.
На этом сокращение ФЗ закончено. Избыточность отсутствует. Необходимо приступать к построению минимального покрытия.
Этап 4. Разделение F3 на классы эквивалентности по правым частям
Строится разбиение F3 на группы: две ФЗ принадлежат одной и той же группе тогда и только тогда, когда их правые части эквивалентны. В результате получается множество классов эквивалентности ФЗ

Этап 5. Удаление в классах эквивалентности избыточных ФЗ
Для всех пар ФЗ fdi и fdj из одной и той же группы проверяется, может ли ФЗ левой стороны fdj от правой стороны fdj быть выведена из этой группы ФЗ. Если да, то из fdj ФЗ удаляется и добавляется в правую часть этой ФЗ к правой fdi. Новая ФЗ будет находиться в той же группе, что и исходная ФЗ. В результате получается минимальное число ФЗ F5, покрывающих F3.
Этап 6. Получение классов эквивалентности по левым частям F5 и составных ФЗ C1
Для каждого множества ФЗ с эквивалентными левыми частями из F5 создается составная ФЗ

Этап 7. Удаление избыточных зависимостей из С1
Для каждой составной ФЗ из С1 и для каждого атрибута Xi из левой части С сдвигаются атрибуты в правую часть. В результате получается множество составных ФЗ С'. Если fd(C') эквивалентно fd(C1), то С1 заменяется на С'. В результате получается множество ФЗ С2.
Этап 8. Формирование кольцевого минимального покрытия
Для каждой составной ФЗ c из С2 и каждого атрибута A из правой части c удаляется атрибут А. В результате получается С', состоящее из с'. Если fd(C') эквивалентно fd(C2), то С2 заменяется на С'.В результате получается множество ФЗ С3.
Этап 9. Формирования схемы полной базы данных
Для каждой составной ФЗ с из С3 формируется таблица атрибутов, которые появляются в с. Ключами для этой таблицы являются Хi из левой части с. Таблица послужит для усиления ФЗ в F.
Алгоритм поэтапного синтеза отношений обладает хорошей сходимостью, его целесообразно использовать в запрограммированном виде. Для этого можно воспользоваться уже готовой программой, или написать свою программу с учетом специфики своих задач, обратившись к монографии Д. Мейера [3].
В результате получается множество ФЗ С3.
Этап 9. Формирования схемы полной базы данных
Для каждой составной ФЗ с из С3 формируется таблица атрибутов, которые появляются в с. Ключами для этой таблицы являются Хi из левой части с. Таблица послужит для усиления ФЗ в F.
Алгоритм поэтапного синтеза отношений обладает хорошей сходимостью, его целесообразно использовать в запрограммированном виде. Для этого можно воспользоваться уже готовой программой, или написать свою программу с учетом специфики своих задач, обратившись к монографии Д. Мейера [3].
Пример. Применение алгоритма синтеза
Пример иллюстрирует работу алгоритма на каждом из его этапов.
Если

































Выводы
В рамках теории реляционных баз данных предлагается два основных подхода к построению логических моделей баз данных: метод декомпозиции и метод синтеза схем отношений.Метод декомпозиции основывается на разбиении некоторого универсального отношения на два или более отношений с помощью реляционной операции проекции.Метод синтеза основывается на обработке исходного множества ФЗ предметной области базы данных.Метод декомпозиции нагляден, достаточно просто реализуется в инструментальных CASE-средствах проектирования, но имеет ряд потенциальных недостатков, связанных с потерей данных при соединениях и с потерей ФЗ.Метод синтеза не приводит к потерям ФЗ, но имеет ряд потенциальных угроз потери информации при соединениях и обладает высокой вычислительной стоимостью.Предлагается ряд технических приемов по преодолению потенциальных недостатков в обоих подходах, позволяющих строить эффективные логические модели данных.На практике при построении логической модели реляционной базы данных целесообразно комбинировать оба подхода, отдавая предпочтение методу декомпозиции.
Создание логической модели реляционной базы данных методом декомпозиции: преобразование ER-диаграмм в отношения базы данных
Практика проектирования реляционных баз данных методом декомпозиции отношений показала ряд его недостатков, связанных с потерей данных при соединениях и с потерей ФЗ. Однако метод декомпозиции достаточно прост для понимания, нагляден, легко реализуется в инструментальных CASE-средствах проектирования и в настоящее время является наиболее часто применяемым при проектировании баз данных.
Для построения логических моделей реляционных баз данных методом декомпозиции сформулирован ряд правил, получивших название правила преобразования ER-диаграмм в отношения базы данных. Правила позволяют исключить потенциальные недостатки метода декомпозиции и нацелены на приведения схемы отношений базы данных к нормальным формам.
Рассмотрим правила преобразования на примере базы данных о преподавателях, читающих лекции в институте. Сущность Преподаватель соотносится с сущностью Предмет посредством связи Читает. При этом возможны следующие варианты поведения данной предметной области:
каждый преподаватель читает только один курс, и каждый курс читается только одним преподавателем, т.е. классы принадлежности обеих сущностей являются обязательными;каждый преподаватель читает только один курс, и каждый курс читается не более чем одним преподавателем, т.е. класс принадлежности первой сущности является обязательным, а второй сущности - необязательным;каждый преподаватель читает не более одного курса, и каждый курс читается не более чем одним преподавателем, т.е. классы принадлежности обеих сущностей не являются обязательными;каждый преподаватель читает не более одного курса, а каждый курс читается только одним преподавателем.
Возможны варианты с иной степенью связи, например когда каждый преподаватель может читать несколько курсов.
Каждый из этих вариантов может быть представлен ER-диаграммой. Однако следует помнить, что каждая ER-диаграмма представляет свой собственный набор правил поведения предметной области и только одна из них может быть истинной в каждый момент времени.
Если степень бинарной связи определена, то предварительные отношения могут быть получены путем просмотра нескольких альтернатив и выбора варианта, наиболее подходящего с точки зрения правил предметной области и личных предпочтений проектировщика. Определяющими признаками выбора одного из альтернативных вариантов представления отношения являются степень связи и класс принадлежности сущности.
Сформулируем первое правило.
Правило 1. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей является обязательным, то требуется построение только одного отношения. При этом первичным ключом отношения может быть ключ любой сущности.
Исходное отношение является одновременно и конечным отношением.
Пример.
ПРЕПОДАВАТЕЛЬ (Табельный_номер, Фамилия, Предмет, Количество_часов)
Это правило может быть применено для первого варианта поведения предметной области, когда исходное отношение не требует декомпозиции, так как не содержит избыточных данных и нуль-значений.
Сформулируем второе правило.
Правило 2. Если степень бинарной связи 1:1 и класс принадлежности одной сущности является обязательным, а другой сущности - не обязательным, то требуется построение двух отношений - по одному на каждую сущность. При этом первичным ключом каждого отношения является ключ его сущности, а ключ сущности с необязательным классом принадлежности добавляется в отношение для сущности с обязательным классом принадлежности в качестве атрибута (миграция ключа). Пример.
Исходное отношение:
ПРЕПОДАВАТЕЛЬ_1 (Табельный_номер, Фамилия, Предмет, Количество_часов)
Результирующие отношения:
ПРЕПОДАВАТЕЛЬ_2 (Табельный_номер, Фамилия, Предмет) ПРЕДМЕТЫ (Предмет, Количество_часов)
Это правило может быть применено во втором варианте, когда исходное отношение уже требует декомпозиции. Исходное отношение ПРЕПОДАВАТЕЛЬ_1 содержит проблему нуль-значений: данные о предметах, которые не читаются в данный момент, не могут быть внесены в базу данных.
Результирующее отношение ПРЕПОДАВАТЕЛЬ_2 не имеет проблемы нуль-значений.
В результирующем отношении ПРЕДМЕТЫ эта проблема исключается: для предмета, который в данный момент не читается, определяется специальное непустое значение по умолчанию. Миграция ключа необходима для восстановления исходного отношения. Таким образом, миграция ключа в методе декомпозиции представляет собой перенос первичного ключа одного отношения в другое отношение для предотвращения потери данных при соединении.
Сформулируем третье правило.
Правило 3. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей не является обязательным, то требуется построение трех отношений - по одному на каждую объектную сущность и одному для связывающего отношения. При этом ключ каждой сущности является первичным ключом соответствующего отношения и одного отношения для связи, с первичным ключом, составленным из ключей объектных сущностей.Пример.
Исходное отношение:
ПРЕПОДАВАТЕЛЬ_1 (Табельный_номер, Фамилия, Предмет, Количество_часов)
Результирующие отношения:
ПРЕПОДАВАТЕЛЬ_2 (Табельный_номер, Фамилия) ПРЕДМЕТЫ (Предмет, Количество_часов) ЧИТАЕТ (Табельный_номер, Предмет)
Это правило можно применить в третьем варианте поведения предметной области, когда исходное отношение необходимо разбить на три отношения. Разбиение на два отношения не позволит исключить проблему нуль-значений. В случае трех отношений такая проблема исключается: в отношение ПРЕДМЕТЫ для предмета, который в данный момент не читается, определяется непустое значение по умолчанию.
Сформулируем четвертое правило.
Правило 4. Если степень бинарной связи 1:N, и класс принадлежности n-связной сущности является обязательным, то достаточно построить два отношения - по одному на каждую сущность. При этом ключ каждой сущности является первичным ключом соответствующего отношения, а ключ 1-связной сущности добавляется в отношение для n-связной сущности в качестве атрибута.
Пример.
Исходное отношение:
ПРЕПОДАВАТЕЛЬ_1 (Табельный_номер, Фамилия, Предмет, Количество_часов)
Результирующие отношения:
ПРЕПОДАВАТЕЛЬ_2 (Табельный_номер, Фамилия) ПРЕДМЕТЫ (Предмет, Количество_часов, Табельный_номер)
Сформулируем пятое правило.
Правило 5. Если степень бинарной связи 1:N и класс принадлежности n-связной сущности не является обязательным, то необходимо построить три отношения - по одному на каждую сущность. При этом ключ каждой сущности является первичным ключом соответствующего отношения и одного отношения для связи. Ключи сущностей должны быть атрибутами последнего отношения. Пример.
Исходное отношение:
ПРЕПОДАВАТЕЛЬ_1 (Табельный_номер, Фамилия, Предмет, Количество_часов)
Результирующие отношения:
ПРЕПОДАВАТЕЛЬ_2 (Табельный_номер, Фамилия) ПРЕДМЕТЫ (Предмет, Количество_часов) ЧИТАЕТ (Предмет, Табельный_номер)
Отметим, что если степень бинарной связи 1:N, то фактором, определяющим выбор одного из правил (правила 4, 5), является класс принадлежности n-связной сущности. Класс принадлежности 1-связной сущности не влияет на конечный результат декомпозиции. В ситуации правила 4 имеет место проблема нуль-значений по атрибуту Предмет, в ситуации правила 5 имеет место проблема нуль-значений по атрибутам Предмет и Преподаватель. Поэтому во избежание дублирования и нуль-значений в ситуации правил 4 и 5 необходимо строить два и три результирующих отношения соответственно. Миграция ключа 1-связной сущности выполняется для восстановления исходного отношения при соединении.
Если степень бинарной связи N:M, то во избежание дублирования и нуль-значений необходимо всегда строить три отношения. Сформулируем шестое правило.
Правило 6. Если степень бинарной связи M:N, то необходимо построить три отношения - по одному для каждой сущности и одно отношение для связи. При этом ключ каждой сущности является первичным ключом соответствующего отношения, и входит в составной первичный ключ отношения для связи. Пример.
Исходное отношение:
ПРЕПОДАВАТЕЛЬ_1 (Табельный_номер, Фамилия, Предмет, Количество_часов)
Результирующие отношения:
ПРЕПОДАВАТЕЛЬ_2 (Табельный_номер, Фамилия) ПРЕДМЕТЫ (Предмет, Количество_часов) ЧИТАЕТ (Предмет, Табельный_номер)
Для отношения с трех- и более сторонней связью во избежание избыточности и нуль-значений требуется построение не менее четырех отношений.
Сформулируем седьмое правило.
Правило 7. Если связь является трехсторонней, необходимо построить четыре отношения - по одному на каждую сущность. При этом ключ каждой сущности является первичным ключом соответствующего отношения и одного отношения для связи. Ключи сущностей должны быть атрибутами последнего отношения.
Аналогично для отношения с n-сторонней связью требуется построение n+1 отношений.
Отметим, что все вышесформулированные правила построены по одному общему принципу: каждому неключевому атрибуту - свое отношение, т.е. миграция неключевых атрибутов запрещена.
Следует помнить, что после предварительного разбиения исходного отношения необходимо показать, используя ФЗ и ключи отношений, что полученная схема реляционной базы данных находится в НФ Бойса-Кодда (НФБК) (или 3НФ). Только тогда полученная схема отношений может считаться окончательной. Обычно проектировщики баз данных при использовании метода декомпозиции не выполняют таких действий, так как в большинстве случаев (но не всегда!) применение правил преобразования дает НФБК.
В некоторых случаях может оказаться, что для создания логической модели предметной области базы данных недостаточно имеющихся сущностей и связей. Одним из них является ситуация, когда экземпляры одной сущности играют разные роли (супертип/подтип) в предметной области базы данных. Это обусловливается наличием между экземплярами сущности отношения иерархии или агрегации по включению. При этом сущность представляет собой множество с отношением порядка на экземплярах, что приводит к наличию классов эквивалентности, имеющих различную семантическую интерпретацию в предметной области.
Так, например, база данных кафедры института содержит две категории служащих - преподаватели и заведующий кафедрой. Заведующий кафедрой также может читать лекции по предметам, но получает обычно фиксированный оклад; преподаватели имеют почасовую ставку оплаты. Попробуем представить информацию о служащих кафедры более подходящим образом. Выделим для каждой категории служащих кафедры отдельную сущность и рассмотрим ER-диаграмму Зав.
кафедрой Руководит Преподавателями.
При этом ключом каждой сущности будет являться табельный номер служащего. Поскольку связь Руководит имеет степень 1:N, и класс принадлежности обеих сущностей является обязательным, то согласно правилу 4 достаточно построить два предварительных отношения. Поскольку неключевые атрибуты Фамилия и Адрес_служащего помещены в оба предварительных отношения, то согласно общему принципу правил преобразования они должны быть переопределены для одного из отношений. Переименование атрибутов в одном из отношений порождает проблему ответа на запрос: для того чтобы найти домашний телефон конкретного служащего, необходимо пересмотреть оба отношения и построить объединение результатов просмотра. Таким образом, переименование атрибутов, к которому иногда поспешно прибегают проектировщики, не является хорошим решением.
Рассмотрим иной вариант представления данных о служащих кафедры. Будем считать заведующего кафедрой и преподавателей служащими, и представим их функции как роли, которые данный служащий может играть. Тогда Отношение СЛУЖАЩИЙ представляет собой родительское отношение - супертип для двух подчиненных отношений - подтипов ЗАВ. КАФЕДРОЙ и ПРЕПОДАВАТЕЛЬ, которые соединяются связью Руководит (см. рис. 7.1).

Рис. 7.1. Отношение "супертип/подтип"
Родительское отношение - супертип - содержит общие с подчиненными отношениями-подтипами атрибуты. Подчиненные отношения - подтипы содержат специфическую для их ролей информацию. Каждое порождаемое ролью отношение связано с общим отношением через атрибут общего домена, в данном случае табельный номер. Окончательный набор отношений будет состоять из трех отношений.
Результирующие отношения:
СЛУЖАЩИЙ (#служащий, общие атрибуты для всех служащих) ЗАВЕДУЮЩИЙ (#заведующий, .... ) ПРЕПОДАВАТЕЛЬ (#преподаватель, ..., #заведующий)
Заметим, что связь, которая соединяет две роли одной исходной сущности, называется рекурсивной (служащие руководят служащими). Связь, которая соединяет роли двух различных сущностей, не является рекурсивной.
Чтобы избежать поиска с целью выявления типа работы служащего, можно ввести в родовое отношение дополнительный атрибут, определяющий, кем является служащий. Несмотря на то, что с точки зрения теории реляционных баз данных такой прием приводит к избыточности данных, к нему прибегают в целях увеличения производительности системы.
Сформулируем восьмое правило.
Правило 8. Исходная сущность служит источником генерации одного отношения. Ключ сущности есть ключ отношения. Подчиненные сущности (ролевые элементы) и связи, соединяющие их, порождают такое количество отношений, которое определяется набором правил 1-7, причем каждый ролевой элемент трактуется как обычная сущность.
Декомпозиция схем отношений, свойства соединения без потерь и сохранения ФЗ
Одной из целей проектирования реляционной базы данных является построение декомпозиции (разбиения) универсального отношения на совокупность отношений, удовлетворяющих требованиям нормальных форм.
Введем определение декомпозиции схемы отношения.
Определение 1. Декомпозицией схемы отношений



Прежде чем перейти к изучению метода декомпозиции схем отношений, рассмотрим проблему соединения отношений при разбиении универсального отношения. Когда мы заменяем исходное отношение на два других взаимосвязанных отношения, правомерно предположить, что эти отношения будут представлять собой проекции исходного отношения на соответствующие атрибуты. Единственный способ выяснить, содержат ли полученные проекции ту же информацию, что и исходное отношение, - восстановить ее, выполнив естественное соединение полученных проекций. Если отношение, полученное в результате выполнения соединения, не будет совпадать с исходным отношением, то невозможно сказать, какое из них является первоначальным отношением для данной схемы. Таким образом, проблема заключается в том, что при соединении можно потерять существующие или приобрести ранее не существовавшие ложные кортежи. Рассмотрим пример декомпозиции с потерей информации.
Пример. Декомпозиция с потерей информации
Атрибуты А и В не зависят функционально от атрибута С.

Говорят, что декомпозиция


Пусть


Эти свойства следуют из определения естественного соединения. Первое свойство используется при проверке, обладает ли декомпозиция свойством соединения без потерь относительно некоторого множества ФЗ.
Рассмотрим алгоритм проверки свойства соединения без потерь.
Алгоритм. Проверка декомпозиции на свойство соединения без потерь
input: схема отношения R(A1, A2, ..., Ak), множество ФЗ F, декомпозиция d={R1, R2, ..., Rk}.
output: Булева переменная истина или ложь.
Алгоритм
Построим таблицу с n столбцами и k строками, где столбец j соответствует атрибуту Аj, а строка i - схеме отношения Ri. На пересечении строки i и столбца j поместим символ aj, если атрибут Aj принадлежит Ri. В противном случае поместим символ bij.Многократно просматриваем каждую ФЗ из F, до тех пор, пока внесение изменений в таблицу станет невозможным. Просматривая зависимость
Приведенный алгоритм позволяет корректно определить, обладает ли декомпозиция свойством соединения без потерь.
Рассмотрим пример применения алгоритма, используя отношение ПОСТАВКИ (Поставщик, Адрес, Товар, Стоимость). Обозначим его атрибуты как: А - поставщик, В - адрес, C - товар, D - стоимость, при этом имеют место ФЗ

Пример. Проверка декомпозиции на свойство соединения без потерь
Схема отношения

| a1 | a2 | b13 | b14 |
| a1 | b22 | a3 | b4 |
| a1 | a2 | b13 | b14 |
| a1 | a2 | a3 | a4 |
При декомпозиции одной схемы отношения на две другие схемы отношений используется более простая проверка: декомпозиция обладает свойством соединения без потерь, если только

Свойство соединения без потерь гарантирует, что любое отношение может быть восстановлено из его проекций. Понятно, что при декомпозиции ФЗ исходной схемы отношения распределяются по новым отношениям. Поэтому важно, чтобы при декомпозиции множество ФЗ F для схемы отношения r было выводимым из проекций на схемы Ri.
output: Булева переменная истина или ложь.
Алгоритм
Построим таблицу с n столбцами и k строками, где столбец j соответствует атрибуту Аj, а строка i - схеме отношения Ri. На пересечении строки i и столбца j поместим символ aj, если атрибут Aj принадлежит Ri. В противном случае поместим символ bij.Многократно просматриваем каждую ФЗ из F, до тех пор, пока внесение изменений в таблицу станет невозможным. Просматривая зависимость
Приведенный алгоритм позволяет корректно определить, обладает ли декомпозиция свойством соединения без потерь.
Рассмотрим пример применения алгоритма, используя отношение ПОСТАВКИ (Поставщик, Адрес, Товар, Стоимость). Обозначим его атрибуты как: А - поставщик, В - адрес, C - товар, D - стоимость, при этом имеют место ФЗ
Пример. Проверка декомпозиции на свойство соединения без потерь
Схема отношения
| a1 | a2 | b13 | b14 |
| a1 | b22 | a3 | b4 |
| a1 | a2 | b13 | b14 |
| a1 | a2 | a3 | a4 |
При декомпозиции одной схемы отношения на две другие схемы отношений используется более простая проверка: декомпозиция обладает свойством соединения без потерь, если только
Свойство соединения без потерь гарантирует, что любое отношение может быть восстановлено из его проекций. Понятно, что при декомпозиции ФЗ исходной схемы отношения распределяются по новым отношениям. Поэтому важно, чтобы при декомпозиции множество ФЗ F для схемы отношения r было выводимым из проекций на схемы Ri.
Некоторые проблемы метода декомпозиции
Алгоритм метода декомпозиции отношений не является совершенным. Мир ФЗ очень разнообразен. Он представляет собой хороший рабочий инструмент и, учитывая типы ФЗ, может совершенствоваться. Обратим внимание на две проблемные ситуации, связанные с применением метода декомпозиции. Пусть имеется отношение R(A, B, C, D, ...) из примера выше.
Первая ситуация: в процессе декомпозиции потеряна ФЗ
Вторая ситуация: один атрибут зависит от двух детерминантов - один возможный ключ {A, C} и два детерминанта А и С. Эта ситуация является более критичной. Отношение не находится в НФБК; в отношении отсутствуют цепочки ФЗ, и правило цепочек к нему неприменимо. Эта проблема не разрешается с помощью стандартного метода декомпозиции. Решением является разложение исходного отношения на два отношения, в основе которого лежит утверждение о том, что все ФЗ с одинаковыми детерминантами необходимо выделять в отдельные группы и каждой такой группе отводить свое собственное отношение. Полученные отношения следует проверять на соответствие НФБК. Такой подход к проектированию логической модели реляционной базы данных получил название метода синтеза. Метод синтеза может использоваться как самостоятельно, так и в сочетании с методом декомпозиции по проекции. Приведенные примеры позволяют понять ряд потенциальных недостатков декомпозиции как метода проектирования лог ических моделей реляционных баз данных.
Прежде чем перейти к изучению метода синтеза, рассмотрим использование элементов синтеза в декомпозиции. Как можно было заметить, декомпозиция осложняется при наличии транзитивных ФЗ. Особенностью транзитивной ФЗ является ее избыточность. ФЗ принято считать избыточной, если она содержит в себе информацию, которая может быть получена из других ФЗ базы данных. Исключение избыточной транзитивной ФЗ из базы данных может быть выполнено без отрицательного воздействия на ее результаты. Избыточность присуща не только транзитивным ФЗ и, следовательно, избыточные ФЗ желательно исключать до применения алгоритма декомпозиции.
Понятие о методах декомпозиции отношений
Предположим, что схема базы данных содержит F-зависимости. Из положений теории о F-зависимостях следует, что если отношения базы данных находятся в нормальной форме Бойса-Кодда (НФБК), то проектирование логической модели базы данных можно считать завершенным в этом классе зависимостей. Как видно, теория дает полезный (!) критерий останова проектирования.
Сформулируем наглядный критерий, позволяющий определить, находится ли отношение в НФБК. Для этого введем следующее вспомогательное понятие.
Определение 3. Пусть дана ФЗ:
Детерминантами в отношениях являются атрибуты левых частей ФЗ. Возможные ключи (см. учебный элемент "Реляционная модель данных") идентифицируются путем нахождения минимального множества значений атрибутов, которые определяют значения всех остальных атрибутов в отношении. Напомним понятие возможного ключа отношения как атрибута или атрибутов данного отношения, который (-ые) могут быть в данном отношении выбраны в качестве первичного.
Тогда критерий Кодда, позволяющий определить, находится ли отношение в НФБК, может быть сформулирован следующим образом:
Отношение находится в НФБК тогда и только тогда, когда каждый детерминант отношения является возможным ключом.
Таким образом, при декомпозиции отношений необходимо строить списки возможных ключей и детерминантов и сравнивать их на совпадение. Устранив таким образом большинство потенциальных аномалий, проектирование можно завершить.
Понятие о методах синтеза отношений
Исключить избыточность в исходном наборе ФЗ можно путем применения правил вывода ФЗ (См. учебный элемент "Функциональные зависимости"). Как известно, для класса F-зависимостей достаточно использовать шесть таких правил. При этом критерием останова процедуры исключения может служить получение минимального покрытия исходного набора ФЗ.
Неединственность минимальных покрытий указывает на то, что порядок исключения избыточных ФЗ может оказать влияние на полученные результаты. Отсюда следует эмпирическое правило:
Избыточные ФЗ следует удалять по одной, каждый раз проводя анализ полученного набора ФЗ на избыточность.
В заключение изучения алгоритмов, основанных на декомпозиции отношений, следует подчеркнуть два обстоятельства, первое из которых указывает на преимущество методов, основанных на синтезе отношений, а второе является недостатком обоих подходов.
Первое. Если универсальное отношение содержит большое количество атрибутов, например более трех десятков, то ручное проектирование становится трудоемким и может, с одной стороны, привести к большим временным затратам, а с другой стороны, породить недопустимое для практики число отношений в базе данных. Поэтому в данном случае следует подумать об автоматизации процесса проектирования, т.е. создать программу проектирования схем баз данных.
Второе. Процесс проектирования реляционных баз данных характеризуется сложной математической природой. Показано, что задача проектирования является NP-сложной задачей, т.е. невозможно построить универсальный алгоритм декомпозиции - алгоритм на "все случаи жизни", на выполнение которого затрачивалось бы время, меньшее экспоненциального времени с числом шагов, пропорциональным eN, где N - число атрибутов.
Кроме того, задача приведения исходных отношений к НФБК может оказаться невыполнимой. Такой факт имел место в практике проектирования. Поскольку НФБК может не существовать на заданном наборе ФЗ, то логичным было бы отказаться от требования приведения отношений базы данных к этой форме. Эта ситуация подкрепляется и теоретически: при любом заданном множестве F-зависимостей над схемой r БД можно построить схему БД в 3НФ.
Таким образом, ограничимся поиском 3НФ в ходе применения метода синтеза, при этом остаются проблемы, связанные с выполнением операций над данными.
Пример преобразования ER-диаграмм в отношения базы данных
Продемонстрируем применение метода декомпозиции (без потерь при естественном соединении) для создания логической модели и базы данных для поддержки деятельности небольшой консультационной фирмы. Фирма производит консалтинг и обучение своих постоянных клиентов; данные о клиентах, сохраняемые в базе данных, будут использоваться консультантами фирмы для проведения семинаров, практических занятий и консультаций.
Первый шаг проектирования базы данных заключается в выявлении всех сущностей предметной области, их атрибутов и связей между атрибутами сущностей. Анализ сведений о предметной области данного примера позволяет определить следующие атрибуты универсального отношения и сделать заключение о наличии функциональных зависимостей (ФЗ) между ними:
Каждый клиент имеет свой регистрационный номер (далее - номер). Все номера у клиентов уникальны и различны. Номер однозначно определяет Фамилию, но не наоборот.





Полученное универсальное отношение назовем КОНСУЛЬТАНТ.

Рис. 7.2. Универсальное отношение КОНСУЛЬТАНТ
Перечислим ФЗ предметной области базы данных:






Рассмотрим детерминанты и возможные ключи отношения КОНСУЛЬТАНТ.
| Возможные ключи | Детерминанты |
| {Номер, Тема, Семестр} | {Номер, Тема, Семестр} |
| {Номер} | |
| {Телефон} | |
| {Адрес} |
Согласно критерию Кодда, поскольку не каждый детерминант в отношении есть возможный ключ, то отношение не находится в НФБК.
Выполним декомпозицию отношения КОНСУЛЬТАНТ R0 (Номер, Тема, Семестр, Фамилия, Адрес, Телефон, Рейтинг). Кандидатами на выполнение проекции являются следующие ФЗ:

Внимание! На практике существует неединственность представления отношений базы данных, обусловленная выбором ФЗ при разбиении отношений. Выбор ФЗ для выполнения проекции отношения - очень важный шаг в проектировании логической модели реляционной базы данных. Выбор альтернативных ФЗ для выполнения проекции может привести к различным базам данных!
Выберем ФЗ


Рис. 7.3. Первая итерация декомпозиции отношений
Проверим, находится ли отношение R2 в НФБК.
Отношение R2 находится в НФБК.
Проверим, находится ли отношение R1 в НФБК.
| Возможные ключи | Детерминанты |
| {Номер, Тема, Семестр} | {Номер, Тема, Семестр} |
| {Номер} | |
| {Адрес} |
Отношение R1 не находится в НФБД, необходимо продолжить его декомпозицию. Выберем ФЗ

Рис. 7.4. Вторая итерация декомпозиции отношений
Проверим, находится ли отношение R3 в НФБК.
| Возможные ключи | Детерминанты |
| {Номер, Тема, Семестр} | {Номер, Тема, Семестр} |
Отношение R3 находится в НФБК.
Проверим, находится ли отношение R4 в НФБК.
| Возможные ключи | Детерминанты |
| {Номер} | {Номер} |
Отношение R4 находится в НФБК. Декомпозиция закончена.
Заметим, что если бы изначально в нашем примере в качестве ФЗ для выполнения проекции была выбрана ФЗ

Литература: [1], [11], [15], [20], [31], [43], [44], [45].
Универсальное отношение
Рассмотрим пример отношения, содержащего данные о студенте университета Иванове (таблица 7.1).
| 1000 | Иванов | Математика | /4 | 417 | 51-11 | |
| Компиляторы | Системное программирование | 5/4 | ||||
| Физика | /5 | |||||
| Окисление серы | Химия | 5/5 |
Пример. Универсальное отношение.
Видно, что данные содержат множественные поля, т.е. атрибуты неатомарны. Дублирование данных в атрибутах позволяет представить данные о студенте в форме отношения (таблица 7.2).
| 1000 | Иванов | Нет | Математика | /4 | 417 | 51-11 |
| 1000 | Иванов | Компиляторы | Системное программирование | 5/4 | 417 | 51-11 |
| 1000 | Иванов | Нет | Физика | /5 | 417 | 51-11 |
| 1000 | Иванов | Окисление серы | Химия | 5/5 | 417 | 51-11 |
Если в отношение включены все атрибуты из предметной области базы данных, то его называют универсальным отношением. Универсальное отношение находится в 1НФ. Как известно, отношением в 1НФ порождается множество аномалий в обработке данных (обновление, удаление, добавление, избыточность). Для того чтобы поместить универсальное отношение в базу данных, его необходимо нормализовать - разбить на совокупность более мелких отношений. При этом возникают следующие три вопроса:
распознать отношения, подлежащие разбиению?Как осуществлять разбиение?Когда окончить процесс разбиения?
Анализ аномалий в обработке данных показывает, что решение двух первых вопросов тесно связано с определением первичного ключа, распознавания явлений дублирования и избыточности, дублирования и неизбыточности данных. В основе всех этих явлений лежит концепция ФЗ. С практической точки зрения смысл ФЗ заключается в следующем: если имеет место
Как же распознать ФЗ на практике? ФЗ определяется в каждой конкретной ситуации посредством детального анализа свойств всех атрибутов отношения и формирования заключения о типах их соотношений друг с другом. ФЗ не могут быть выявлены путем просмотра отдельного экземпляра отношения и нахождения двух атрибутов, имеющих одинаковые значения в разных кортежах. ФЗ должны быть получены из собственных свойств атрибутов предметной области базы данных. Просмотр отношения - это формальное определение возможных, но не действительных функциональных связей.
Определив все ФЗ, присущие предметной области базы данных, можно приступать к процессу разбиения отношений, именуемому декомпозицией схем отношений. Декомпозиция схем отношений является одним из основных методов построения логических моделей реляционных баз данных. Использование универсального отношения позволяет иметь отправную точку декомпозиции отношений базы данных. Результатом декомпозиции является нормализованная модель данных.
Арифметические функции
SQL поддерживает полный набор арифметических операций и математических функций для построения арифметических выражений над колонками базы данных (+, -, *, /, ABS, LN, SQRT и т.д.). Список основных встроенных математических функций дан ниже в таблице 8.2.
| ABS(X) | Возвращает абсолютное значение числа Х |
| ACOS(X) | Возвращает арккосинус числа Х |
| ASIN(X) | Возвращает арксинус числа Х |
| ATAN(X) | Возвращает арктангенс числа Х |
| COS(X) | Возвращает косинус числа Х |
| EXP(X) | Возвращает экспоненту числа Х |
| SIGN(X) | Возвращает -1, если Х<0,0, если Х=0, +1, если Х>0 |
| LN(X) | Возвращает натуральный логарифм числа Х |
| MOD(X,Y) | Возвращает остаток от деления Х на Y |
| CEIL(X) | Возвращает наименьшее целое, большее или равное Х |
| ROUND(X,n) | Округляет число Х до числа с n знаками после десятичной точки |
| SIN(X) | Возвращает синус числа Х |
| SQRT(X) | Возвращает квадратный корень числа Х |
| TAN(X) | Возвращает тангенс числа Х |
| FLOOR(X) | Возвращает наибольшее целоеб меньшее или равное Х |
| LOG(a,X) | Возвращает логарифм числа Х по основанию А |
| SINH(X) | Возвращает гиперболический синус числа Х |
| COSH(X) | Возвращает гиперболический косинус числа Х |
| TANH(X) | Возвращает гиперболический тангенс числа Х |
| TRANC(X,n) | Усекает число Х до числа с n знаками после десятичной точки |
| POWER(A,X) | Возвращает значение А, возведенное в степень Х |
Набор встроенных функций может изменяться в зависимости от версии СУБД одного производителя и также в СУБД различных производителей. Так, например, в СУБД SQLBase, Centure Inc. есть функция @ATAN2(X,Y), которая возвращает арктангенс Y/X, но отсутствует функция SIGN(X).
Арифметические выражения необходимы для получения данных, которые непосредственно не сохраняются в колонках таблиц базы данных, но значения которых необходимы пользователю. Допустим, что вам необходим список служащих, показывающий выплату, которую получил каждый служащий с учетом премий и штрафов.
SELECT ENAME, SAL, COMM, FINE, SAL + COMM - FINE FROM EMPLOYEE ORDER BY DEPNO;
Арифметическое выражение SAL + COMM - FINE выводится как новая колонка в результирующей таблице, которая вычисляется в результате выполнения запроса. Такие колонки называют еще производными (вычисляемыми) атрибутами или полями.
Домены и допустимые типы данных
В информационной модели, создаваемой на этапе анализа, среда реализации не учитывается. Аналитик просто определяет атрибуты как строку, число или дату, в идеале он также назначает атрибуту домен. В контексте аналитика домен - это просто тип атрибута, например деньги или рабочий день. Аналитик может включить ряд проверок допустимости или правил обработки, например требование, что значение должно быть положительным, ненулевым и иметь максимум два десятичных разряда (это полезно для сумм долларовых трат, выставляемых банком на другой банк). Использование доменов аналитиком упрощает задачу обеспечения непротиворечивости. При переходе к проектированию физической модели проектировщику необходимо знать возможности выбранной СУБД по назначению типов данных колонок. В логической модели данных значения, которые может принимать атрибут отношения, также задаются доменом, который наследуется из информационной модели. В физической модели базы данных требуется, чтобы каждый атрибут отношения в базе данных обладал рядом свойств, которые диктуют, что в нем может храниться и что не может. Этими свойствами являются тип, размер и ограничения, которые могут еще более ограничивать допустимый набор значений столбца. Задача состоит в преобразовании домена в подходящий тип данных, поддерживаемый СУБД. Таким образом, проектировщик базы данных должен знать, какими типами данных он располагает при решении вышеуказанной задачи.
В контексте проектирования физической модели реляционной базы данных домен - это выражение, определяющее разрешенные значения для колонок (атрибутов) отношения. При описании таблицы реляционной базы данных каждой колонке назначается определенный тип данных. Практически основу определения домена составляет тип данных, содержащихся в колонке, поскольку большинство встроенных типов задают разрешенный интервал значений данных.
Пример. Колонку в базе данных можно описать следующим образом:
amount NUMBER (8,2) NOT NULL CONSTRAINT cc_limit_amnt CHECK (amount > 0)
В этой колонке можно размещать только числовые данные; она должна быть заполнена для каждой таблицы; ее значение должно быть положительным; точность этого значения - два значащих десятичных разряда. Максимальное значение, которое может храниться в этом столбце, - 999999.99. В этом простом определении колонки мы фактически определили ряд неявных правил, проверку которых Oracle принудительно включает при вводе данных в базу данных.
Как видно, дальнейшее определение домена колонки (после присвоения ей типа) выполняется проектировщиком с помощью уточнений правил изменения значений. Такие уточнения поддерживаются в SQL с помощью механизма ограничений в спецификации колонки в таблице (см. далее). В этом разделе мы рассмотрим связь между понятием домена и допустимыми в СУБД типами данных.
В стандарт SQL-92 введено понятие доменов, определенных пользователем. Определение таких доменов базируется на встроенных типах данных СУБД.
Допустимые типы данных
Все допустимые типы данных описаны в стандарте SQL-92, но в большинстве диалектов поддерживается расширенный список типов данных. Однако любой диалект SQL поддерживают три общих типа данных: строковые, числовые и тип для представления даты и времени. Задание типа данных определяет значения и длину данных, а также формат их представления при визуализации.
Для всех типов данных определено так называемое нуль-значение, которое указывает на отсутствие данных в колонке указанного типа, т.е. то обстоятельство, что значение данных в текущий момент времени неизвестно.
Описание типов, данное в таблице ниже, относится к диалекту SQL для СУБД SQLBase, которое имеет существенные отличия от предписаний стандарта SQL. В комментарии уточняются сведения о типах данных, принятые в реализации СУБД Oracle. Жирным шрифтом выделена часть зарезервированного слова для определения типа, которую можно использовать как аббревиатуру при определении типа в спецификации колонки.
Данные строкового типа представляют собой последовательность строк символов. Строковые данные могут быть заданы как с предопределенной длиной (ключевые слова char или varchar (длина строки)), так и без указания длины (ключевое слово long varchar) для представления строк произвольной длины. Тип данных varchar2 определяет строку символов переменной длины, имеющую максимальный размер size. В отличие от строкового типа с предопределенной длиной, со строками long varchar не допускаются операции сравнения, и они не могут быть использованы в выражениях и как аргументы большинства встроенных функций. В Oracle этот тип не может быть использован в определении последовательности. Строки последнего типа могут применяться для сохранения битовых образов. Стандарт SQL-92 не имеет типа long varchar и varchar.
Обратим внимание на тип данных varchar2. Он, так же как и тип данных char, предназначен для представления алфавитно-цифровых данных. Но он имеет формат переменной длины. Последнее означает, что длина колонки такого типа равна числу символов в ней, в то время как колонка типа char использует все определенное для нее пространство.
Сравним две колонки с содержанием 'abc', но с типами varchar2(5) и char(5). Первая занимает действительно 3 байта, а вторая - 5 байт. Оставшиеся два байта заполняются символом "white space", который аналогичен пропуску, возникающему при нажатии на клавиатуре клавиши space bar. Несмотря на то, что колонки содержат одинаковые строки, они не равны, так как первая в 4-й и 5-й позициях содержат null-значение, а вторая в тех же позициях содержит white space. Это может привести к проблемам при соединении таблиц по таким колонкам. Обычно колонки типа varchar2 не планируются для использования в процедурах поиска данных в базе данных. В них хранят текст.
Существует два типа числовых данных.
Целые и вещественные значения (например, сальдо банковского счета или ставка процента). Они являются объектом математической обработки.Строковые числовые данные, в которых единственно допустимыми символами являются цифры (например, номера банковских счетов).
Числовые типы данных предназначены для представления целых чисел, чисел с десятичной точкой и чисел с плавающей точкой. Любое представление чисел задается своей точностью и масштабом. Точность определяет допустимое представлением количество значащих цифр числа, а масштаб - количество значащих цифр после десятичной точки.
Для представления целых чисел используются типы interger (точность 10 значащих цифр) и smallint (точность 5 значащих цифр).
Для представления чисел с фиксированной десятичной точкой используются типы number (точность, масштаб) (для чисел с точностью до 15 значащих цифр) и decimal (точность, масштаб) (для чисел заданной точности до 15 значащих цифр). Если указать для колонки тип number без задания масштаба, максимальное число значащих цифр для Oracle будет 105. Вместо задания точности и масштаба может быть указан символ *. Это будет эквивалентно заданию просто типа number. Различие между этими типами данных состоит в том, что для типа number нет необходимости следить за точностью при выполнении операций.
При выполнении операций с числами этих типов действуют следующие формулы для определения точности и масштаба результата (p - точность, s - масштаб):
сложение/вычитание точность=max{min[15, max(p1-s1, p2-s2)+max(s1, s2)+1]} масштаб=max[s1, s2] деление точность=15 масштаб=15-p1+s1-s2 умножение точность=min{15, p1+p2} масштаб=min{15, s1+s2}
Для представления чисел с плавающей точкой в SQL предусмотрены следующие типы данных:
Double Precision - для чисел с точностью от 22 до 53 значащих цифр;Float (точность) - для представления чисел с точностью от 1 до 21 значащей цифры;Real - для чисел с точностью по умолчанию (зависит от конкретной реализации).
Тип данных для представления даты и времени отсутствует в стандарте SQL. Обычно в конкретных диалектах SQL используются три типа для представления таких данных:
datestamp (timestamp) - для представления даты и времени;date - для представления даты;time - для представления времени.
В СУБД Oracle тип date принимает допустимые значения от 1 января 4712 ВС до 31 декабря 4712 АD. Формат по умолчанию - "ДД-МММ-ГГ".
В СУБД Oracle представлен набор типов данных для хранения объектов большого размера: Long Raw для хранения очень больших по размеру данных цифровой природы и raw для хранения битовых строк сравнительно небольшого размера.
В Oracle есть еще два типа данных для представления метки безопасности операционной системы (secure operating system label): msllabel в виде четырех последовательных байт и raw msllabel - в двоичном формате.
Правила преобразования типов представлены в таблице 8.9 ниже.
| Строковый | Числовой | Значение исходного типа должно быть в форме допустимой для числовых значений |
| Числовой | Строковой | Нет необходимости в одинарных кавычках |
| Дата/время | Числовой | |
| Числовой | Дата/время | |
| Дата/время | Строковой | Нет необходимости в одинарных кавычках |
| Строкой | Дата/время | Значение исходного типа должно быть в форме допустимой для значений даты и время |
Функции для обработки даты
В диалекте SQL СУБД Oracle имеется небольшой набор функций для манипулирования колонками с типом date. Список основных функций обработки даты и времени приведен в таблице 8.6.
| SYSDATE | Возвращает текущую дату и время |
| ROUND(D[,F]) | Округляет значение даты D согласно заданному шаблону |
| TRANC(D[,F]) | Усекает значение даты D согласно заданному шаблону |
| NEXT_DAY(D,S) | Возвращает дату дня, который является первым днем, более поздним, чем текущая дата с названием S |
Если вам потребовался список новых служащих, поступивших за последний квартал в организацию, то вы можете написать запрос в следующем виде:
SELECT ENAME, HIREDATE, HIREDATE + 92 DAYS FROM EMPLOYEE WHERE HIREDATE + 92 DAYS > SYSDATE AND DEPNO=30;
Ключевое слово SYSDATE всегда возвращает текущую дату. В этом примере также показано, как используется арифметический оператор сложения с переменными типа "дата". К переменной типа "дата" можно прибавлять и вычитать из него целое число дней, месяцев, лет, часов, минут, секунд, микросекунд. Для этого используются соответствующие ключевые слова (DAY, MONTH и т.д.), следующие за целой константой (дробная часть игнорируется, если вы указываете число с десятичной точкой). Имеется ограничение на использование скобок в таких выражениях (так, заключение в скобки выражения 1 DAYS + 1 YEARS приведет к ошибке).
Функции обработки строк
SQL предоставляет вам широкий набор функций для манипулирования со строковыми данными (конкатенация строк, CHR, LENGTH, INSTR и другие). Список основных функций для обработки строковых данных приведен в таблице 8.3.
| CHR(N) | Возвращает символ ASCII кода для десятичного кода N |
| ASCII(S) | Возвращает десятичный ASCII код первого символа строки |
| INSTR(S2.S1.pos[,N] | Возвращает позицию строки S1 в строке S2 большую или равную pos.N - число вхождений |
| LENGHT(S) | Возвращает длину строки |
| LOWER(S) | Заменяет все символы строки на прописные символы |
| INITCAP(S) | Устанавливает первый символ каждого слова в строке на заглавный, а остальные символы каждого слова - на прописные |
| SUBSTR(S,pos,[,len]) | Выделяетв строке S подстроку длиной len, начиная с позиции pos |
| UPPER(S) | Преобразует прописные букцвы в строке на заглавные буквы |
| LPAD(S,N[,A]) | Возвращает строку S, дополненную слева симолами A до числа символов N. Символ - наполнитель по умолчанию - пробел |
| Rpad(S,N[,A]) | Возвращает строку S, дополненную справа симолами A до числа символов N. Символ - наполнитель по умолчанию - пробел |
| LTRIM(S,[S1]) | Возвращает усеченную слева строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон S1 (по умолчанию - пробел) |
| RTRIM(S,[S1]) | Возвращает усеченную справа строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон S1 (по умолчанию - пробел |
| TRANSLATE(S,S1,S2) | Возвращает строку S, в которой все вхождения строки S1 замещены строкой S2. Если S1 <> S2, то символы, которым нет соответствия, исключаются из результирующей строки |
| REPLACE(S,S1,[,S2]) | Возвращает строку S, для которой все вхождения строки S1 замещены на подстроку S2. Если S2 не указано, то все вхождения подстроки S1 удаляются из результирующей строки |
| NVL(X,Y) | Если Х есть NULL, то возвращает в Y либо строку, либо число, либо дату в зависимости от исходного типа Y |
Названия одних и тех же функций могут отличаться в различных СУБД.
Так, например, функция СУБД Oracle SUBSTR(S, pos, [, len]) в СУБД SQLBase называется @SUBSTRING(S, pos, len). В СУБД SQLBase имеются функции, которых нет в СУБД Oracle (см. таблицу ниже, где приведен список таких функций).
| @EXACT(S1,S2) | Возвращает результат сравнения двух строк |
| @LEFT(S,len) | Возвращает левую подстроку длиной len |
| LENGTH(S) | Возвращает длину строки |
| @MID(S, pos, len) | Возвращает подстроку указанной длины, начиная с позиции pos |
| @REPEAT(S,n) | Повторяет строку S n раз |
| @REPLACE(S1,pos,len,S2) | Замещает с позиции pos len символов в строке S2 символами строки S1 |
| RIGHT(S,len) | Возвращает правую подстроку S длиной len |
| @SCAN(S,pat) | Возвращает позицию подстроки pat в строке S |
| @STRING(X,scale) | Возвращает символьное представление числа с указанным масштабом scale |
| @TRIM(S) | Удаляет пробелы в строке справа и слева |
| @VALUE(S) | Преобразует символьное представление числа в числовое значение |
SELECT INITCAP(ENAME) FROM EMPLOYEE ORDER BY DEPNO;
Иерархия объектов реляционной базы данных
Одной из главных задач, которые обязан решить проектировщик на стадии проектирования физической модели реляционной базы данных, является задача превращения объектов логической модели реляционной базы данных в объекты реляционной базы данных. Для решения этой задачи проектировщику базы данных необходимо знать: а) какими объектами располагает реляционная база данных в принципе; б) какие объекты поддерживает конкретная СУБД, которая выбрана для реализации базы данных.
Таким образом, мы предполагаем, что решение о выборе СУБД уже принято руководителем ИТ-проекта, и согласовано с заказчиком базы данных, т.е. СУБД задана. Проектировщик базы данных должен ознакомиться с документацией, в которой описан диалект SQL, поддерживаемый выбранной СУБД. В настоящей лекции предполагается, что была выбрана СУБД Oracle 9i, хотя подавляющая часть материала охватывает объекты в любой промышленной реляционной СУБД.
Замечание. О выборе СУБД. Выбор СУБД относится к многокритериальной задаче выбора и в настоящем курсе не рассматривается. Следует помнить о том, что СУБД обычно поддерживает только одну модель данных: реляционную, иерархическую, сетевую, многомерную, объектно-ориентированную, объектно-реляционную. Исключение составляют небольшое число СУБД. Например, ADABAS, Software AG (сетевая и реляционная модели), или Oracle 9i, Oracle Inc. (реляционная и объектно-реляционная модели). Обычно при выборе СУБД при всех прочих равных возможностях стараются создать базу данных на СУБД, претендующей на промышленный стандарт.
Иерархия объектов реляционной базы данных прописана в стандартах по SQL, в частности, в стандарте SQL-92, на который мы будем ориентироваться при изложении материала настоящей лекции. Этот стандарт поддерживается практически всеми современными СУБД, вплоть до настольных. Иерархия объектов реляционной базы данных показана на рисунке ниже.
На самом нижнем уровне находятся наименьшие объекты, с которыми работает реляционная база данных, - столбцы (колонки) и строки. Они, в свою очередь, группируются в таблицы и представления.
Замечание. В контексте лекции атрибуты, колонки, столбцы и поля считаются синонимами. То же относится и к терминам "строка", "запись" и "кортеж".
Таблицы и представления, которые представляют физическое отражение логической структуры базы данных, собираются в схему. Несколько схем собираются в каталоги, которые затем могут быть сгруппированы в кластеры. Следует отметить, что ни одна из групп объектов стандарта SQL-92 не связана со структурами физического хранения информации в памяти компьютеров.

Рис. 8.1. Иерархия объектов реляционной базы данных, соответствующая стандарту SQL-92
Помимо указанных на рисунке объектов, в реляционной базе данных могут быть созданы индексы, триггеры, события, хранимые команды, хранимые процедуры и ряд других. Теперь перейдем к определению объектов реляционной базы данных.
Использование агрегатных функций в запросах
Агрегатные функции в SQL позволяют выбирать обобщающую информацию из группы строк и проводить систематизацию данных. Список агрегатных функций приведен в таблице 8.7. Агрегатные функции почти во всех реализациях SQL носят одинаковые имена. Различие в наименование для Oracle дано через косую черту.
| AVG(X) = AVG(ALL X) AVG(DISTINCT X) | Вычисляет среднее значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты |
| COUNT(*) COUNT(X) = COUNT(ALL X) COUNT(DISTINCT X) | Вычисляет числа итемов. При указании * всегда возвращается число строк в таблице. Указание DISTINCT подавляет дуюликаты |
| MAX(X) = MAX(ALL X) MAX (DISTINCT X) | Вычисляет максимальное значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты |
| MIN(X) = MIN(ALL X) MIN (DISTINCT X) | Вычисляет минимальное значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты |
| SUM(X) = SUM(ALL X) SUM (DISTINCT X) | Вычисляет сумму значение аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты |
| STDDEV([DISTINCT|ALL]X) | Вычисляет стандартное отклонение на множестве значений аргумента, который может быть выражением любого типа. Нуль-значения игнорируются, ключевое слово DISTINCT подавляет дубликаты |
| VARIANCE([DISTINCT|ALL]) | Вычисляет квадрат дисперсии |
Использование функций агрегирования позволяет вам находить суммарные значения колонок и разброс данных в колонке. Так, после выполнения запроса
SELECT SUM(SAL) FROM EMPLOYEE;
вы узнаете итоговую сумму зарплаты по организации, а из запроса
SELECT AVG(SAL), STDDEV(SAL) FROM EMPLOYEE;
- среднюю зарплату по организации и ее разброс (дисперсию).
Однако наиболее часто требуется подобная итоговая информация не для таблицы в целом, а для определенных наборов (групп) строк таблицы.
Для того чтобы группировать строки таблицы по какому-либо признаку, в команде SELECT существует специальное предложение GROUP BY, которое задает колонку (или колонки) для проведения группировки. Это предложение группирует строки таблицы по значениям колонок группировки с последующим подавлением дублирующих значений в колонках группировки, т.е. позволяет определять подмножество значений некоторой колонки в терминах другой колонки и применять к полученным подмножествам функции агрегирования.
Предположим, что вы хотите найти минимальные и максимальные оклады служащих в подразделениях, тогда вы можете написать
SELECT DEPNO, MIN(SAL), MAX(SAL) FROM EMPLOYEE GROUP BY DEPNO;
Предложение GROUP BY должно следовать после предложения WHERE, если последнее присутствует в команде SELECT. Каждая строка результирующей таблицы относится к одной группе строк. Число групп определяется числом различных значений в колонке группировки (в данном случае DEPNO). Агрегатные функции применяются к каждой группе как к отдельному множеству.
Агрегатные функции можно использовать при соединении таблиц. Допустим, что вам нужно знать, сколько служащих работает на каждой должности в каждом подразделении, какова сумма зарплаты на подразделение и средняя зарплата. Тогда вам нужен запрос
SELECT DNAME, JOB, SUM(SAL), COUNT(*), AVG(SAL) FROM EMPLOYEE, DEPARTAMENT WHERE EMPLOYEE.DEPNO=DEPARTAMENT.DEPNO GROUP BY DNAME, JOB;
Функции SUM( ), COUNT( ), AVG( ) вычисляют суммы, число строк в группе и среднее значение в группе строк.
В SQL можно задавать условия поиска для группы строк. Для этого в команде SELECT существует предложение HAVING, которое должно следовать за предложением GROUP BY. HAVING задает условие поиска для группы строк.
Допустим, что вам необходимо получить ответ на тот же вопрос, что и в предыдущем примере, но при этом каждая группа должна состоять не менее чем из двух сотрудников.
SELECT DNAME, JOB, SUM(SAL), AVG(SAL) FROM EMPLOYEE, DEPARTAMENT WHERE EMPLOYEE.DEPNO=DEPARTAMENT.DEPNO GROUP BY DNAME, JOB HAVING COUNT(*)>=2;
Условие поиска в предложении HAVING исключает из результирующей таблицы группы, содержащие менее двух работников.
Таким образом, вы познакомились с различными вариантами использования команды SQL SELECT.
Константы, выражения, системные переменные
Константы обычно специфицируют единственное значение и, в соответствии с типом представляемых данных, могут быть строковыми, числовыми и представлять дату/время. Строковые константы должны быть заключены в одинарные кавычки.
В SQL существует ряд предопределенных системных переменных, которые можно использовать в выражениях вместо имен колонок и констант. К таким переменным относятся следующие:
NULL - для представления неопределенных значений;ROWID - (в SQLBase) внутренний системный номер строки в таблице;USER - имя пользователя, активного в данный момент;SYSDATETIME - системное текущее время и дата;SYSDATE - системная текущая дата;SYSTIME - системное текущее время;SYSTIMEZONE - временной пояс, установленный в системе.
Выражением в SQL является итем или комбинация итемов с допустимыми для них операциями, которая дает единственное значение. В качестве итемов могут выступать имена колонок, константы, связанные переменные, результаты вычислений функций, системные переменные и другие выражения. При этом если один из итемов имеет нуль-значение, то результат выражения также имеет нуль-значение.
В этом разделе вы узнали, какие вcтроенные типы данных предоставляются проектировщику баз данных в диалектах SQL доменов в физической модели реляционной базы данных. Заметим, что наиболее распространены три из них - varchar2, number и date. Наличие такого небольшого набора типов данных может показаться недостатком, однако это не так. В Oracle типы, определенные в других СУБД и диалектах SQL, можно создать, используя определенный пользователем тип данных. Например, тип money - это тип number с двумя десятичными разрядами, а тип positive integer - тип number без десятичных разрядов и с ограничением на ввод отрицательных значений. По крайней мере, при таком положении дел вам не приходится беспокоиться об ограничениях на внутреннюю память, решая, как хранить вещественное число - с использованием типа float или типа double.
Самое главное при выборе типов данных - обеспечение непротиворечивости. Если вы определите номер шасси автомобиля в одной таблице как number(11), а в другой таблице - как varchar(15), то, когда дело дойдет до соединения этих таблиц, неприятности вам обеспечены. Напишите-ка SQL-предложение для сравнения 918273645 и "918-27-36/4/5". Да так, чтобы оно эффективно работало в предложении, выполняющем соединение!
Описание основных операторов SQL
SQL состоит из набора команд манипулирования данными в реляционной базе данных, которые позволяют создавать объекты реляционной базы данных, модифицировать данные в таблицах (вставлять, удалять, исправлять), изменять схемы отношений базы данных, выполнять вычисления над данными, делать выборки из базы данных, поддерживать безопасность и целостность данных.
Весь набор команд SQL можно разбить на следующие группы:
команды определения данных (DDL - Data Defininion Language);команды манипулирования данными (DML - Data Manipulation Language);команды выборки данных (DQL - Data Query Language);команды управления транзакциями;команды управления данными.
При выполнении каждая команда SQL проходит четыре фазы обработки:
фаза синтаксического разбора, которая включает проверку синтаксиса команды, проверку имен таблиц и колонок в базе данных, а также подготовку исходных данных для оптимизатора;фаза оптимизации, которая включает подстановку действительных имен таблиц и колонок базы данных в представление, идентификацию возможных вариантов выполнения команды, определение стоимости выполнения каждого варианта, выбор наилучшего варианта на основе внутренней статистики;фаза генерации исполняемого кода, которая включает построение выполняемого кода команды;фаза выполнения команды, которая включает выполнение кода команды.
В настоящее время оптимизатор является составной частью любой промышленной реализации SQL. Работа оптимизатора основана на сборе статистики о выполняемых командах и выполнении эквивалентных алгебраических преобразований с отношениями базы данных. Такая статистика сохраняется в системном каталоге базы данных. Системный каталог является словарем данных для каждой базы данных и содержит информацию о таблицах, представлениях, индексах, колонках, пользователях и их привилегиях доступа. Каждая база данных имеет свой системный каталог, который представляет совокупность предопределенных таблиц базы данных.
Таблица 8.1 содержит список команд SQL в соответствии с принятым стандартом, за исключением некоторых практически не используемых в диалектах команд.
Жирным шрифтом выделены команды диалекта SQL СУБД Oracle.
| Команды определения данных объектов | |
| ALTER TABLE | Изменяет описание таблицы (схему отношения) |
| CREATE EVENT | Создает событие таймера в базе данных |
| CREATE INDEX | Создает индекс для таблицы |
| CREATE SEQUENCE | Создает последовательность |
| CREATE TABLE | Определяет таблицу |
| CREATE TABLESPACE | Создает табличное пространство |
| CREATE TRIGGER | Создает триггер в базе данных |
| CREATE VIEW | Определяет представление на таблицах |
| DROP INDEX | Физически удаляет индекс из баз данных |
| DROP SEQUENCE | Удаляет последовательность |
| DROP TABLE | Физически удаляет таблицу из базы данных |
| DROP TABLESPACE | Удаляет табличное пространство |
| DROP VIEW | Удаляет представление |
| Команды манипулирвания данными | |
| DELETE | Удаляет одну или более строк из таблицы базы данных |
| INSERT | Вставляет одну или более строк в таблицу баззы данных |
| UPDATE | Обновляет значения колонок в таблице базыы данных |
| Команды выборки данных | |
| SELECT | Выполняет запрос на выборку данных из таблиц и представлений |
| UNION | Объединяет в одной выборке результаты выполнения двух или более команд SELECT |
| Команды управления транзакциями | |
| COMMIT | Завершает транзакцию и физически актуалищирует состояние базы данных |
| ROLLBACK | Завершает транзакцию и возвращает текущее состояние базы данных на момент последней завершенной транзакции и контрольной точки |
| SAVEPOINT | Назначает контрольную точку внутри транзакции |
| Команды управления данными | |
| ALTER DATABASE | Изменяет группы хранения или журналы транзакций |
| ALTER DBAREA | Изменяет размер областей хранения базы данных |
| ALTER PASSWORD | Изменяет пароль для доступа к базе данных |
| ALTER STOGROUP | Изменяет состав областей хранения в группе хранения |
| CHECK DATABASE | Проверяет целостность базы данных |
| CHECK INDEX | Проверяет целостность индекса |
| CHECK TABLE | Проверяет целостность таблицы и индекса |
| CREATE DATABASE | Физически создает базу данных |
| CREATE DBAREA | Создает область хранения базы данных |
| CREATE STOGROUP | Создает группу хранения |
| CREATE SYSNONYM | Создает синоним для таблицы или представления |
| DEINSTALL DATABASE | Делает базу данныхх недоступной пользователям вфычислительной сети |
| DROP DATABASE | Физически удаляет базы данных |
| DROP DBAREA | Физически удаляет область хранения данных |
| DROP STOGROUP | Удаляет группу хранения |
| GRANT | Определяет привелеги пользователей и разграничение доступа к базе данных |
| INSTALL DATABASE | Делает базу данных доступной пользователям вычислительной сети |
| LOCK DATABASE | Блокирует текущую активную базу данных |
| REVOKE | Отменяет привелегии пользователей и разграничения доступа к базе данных |
| SET DEFAULT STOGROUP | Определяет группу хранения по умолчанию |
| UNLOCK DATABASE | Деблокирует текущую активную базу данных |
| UPDATE STATISTIK | Обновляет статистику для базы данных |
| Другие команды | |
| COMMENT ON | Размещает в системном каталоге комментарии к описанию объектов БД |
| CREATE SYNONYM | Определяет в системном каталоге альтернативные имена для таблиц и представлений БД |
| DROP SYNONYM | Удаляет из системного каталого альтернативные именя для таблиц и представлений БД |
| LABEL | Изменяет метки системных описаний |
| ROWCOUNT | Вычисляет число строк в таблице БД |
Набор команд SQL, перечисленный в таблице, не является полным. Этот список приведен, чтобы вы составили впечатление о возможностях SQL в целом. Для получения полного списка команд следует обратиться к соответствующему руководству для конкретной СУБД. Следует помнить, что SQL является единственным средством общения всех категорий пользователей с реляционными базами данных.
Основные объекты реляционной базы данных
Кластеры, каталоги и схемы не являются обязательными элементами стандарта и, следовательно, программной среды реляционных баз данных.
Под кластером понимается группа каталогов, к которым можно обращаться через одно соединение с сервером базы данных (программная компонента СУБД).
На практике процедура создания каталога определяется реализацией СУБД на конкретной операционной платформе. Под каталогом понимается группа схем. На практике каталог часто ассоциируется с физической базой данных как набором физических файлов операционной системы, которые идентифицируются ее именем.
Для проектировщика базы данных схема - это общее логическое представление отношений законченной базы данных. С точки зрения SQL, схема - это контейнер для таблиц, представлений и других структурных элементов реляционной базы данных. Принцип размещения элементов базы данных в каждой схеме полностью определяется проектировщиком базы данных.
Для создания таблиц и представлений наличие схемы не обязательно. Если у вас планируется инсталляция только одной логической базы данных, то ясно, что можно обойтись и без схемы. Но если планируется, что одна и та же СУБД будет использоваться для поддержки нескольких баз данных, то надлежащая организация объектов баз данных в схемы может значительно облегчить сопровождение этих баз данных. На практике схема часто ассоциируется с объектами определенного пользователя физической базы данных.
Далее объекты реляционной базы данных будут вводиться в контексте реляционной СУБД Oracle 9i. Такой подход принят потому, что проектирование физической модели реляционной базы данных выполняется для конкретной среды ее реализации.
В Oracle 9i термин схема (Schema) используется для описания всех объектов базы данных, которые созданы некоторым пользователем. Для каждого нового пользователя автоматически создается новая схема.
К числу основных объектов реляционных баз данных относятся таблица, представление и пользователь.
Таблица (Table) является базовой структурой реляционной базы данных.
Она представляет собой единицу хранения данных - отношение. Таблица идентифицируется в базе данных своим уникальным именем, которое включает в себя идентификацию пользователя. Таблица может быть пустой или состоять из набора строк.
Представление (View) - это поименованная динамически поддерживаемая СУБД выборка из одной или нескольких таблиц базы данных. Оператор выборки ограничивает видимые пользователем данные. Обычно СУБД гарантирует актуальность представления - его формирование производится каждый раз, когда представление используется. Иногда представления называют виртуальными таблицами.
Пользователь (User) - это объект, обладающий возможностью создавать или использовать другие объекты базы данных и запрашивать выполнение функций СУБД, таких как организация сеанса работы, изменение состояние базы данных и т. д.
Для упрощения идентификации и именования объектов в базе данных поддерживается такие объекты, как синоним, последовательность и определенные пользователем типы данных.
Синоним (Synonym) - это альтернативное имя объекта (псевдоним) реляционной базы данных, которое позволяет иметь доступ к данному объекту. Синоним может быть общим и частным. Общий синоним позволяет всем пользователям базы данных обращаться к соответствующему объекту по его псевдониму. Синоним позволяет скрыть от конечных пользователей полную квалификацию объекта в базе данных.
Последовательность (Sequence) - это объект базы данных, который позволяет генерировать последовательность уникальных чисел (номеров) в условиях многопользовательского асинхронного доступа. Обычно элементы последовательности используются для уникальной нумерации элементов таблиц (строк) в операциях модификации данных.
Определенные пользователем типы данных (User-defined data types) представляют собой определенные пользователем типы атрибутов (домены), которые отличаются от поддерживаемых (встроенных) СУБД типов. Они определяются на основе встроенных типов. Определенные пользователем типы данных образуют ту часть среды СУБД, которая организована в соответствии с объектно-ориентированной парадигмой.
Для обеспечения эффективного доступа к данным в реляционных СУБД поддерживаются ряд других объектов: индекс, табличная область, кластер, секция.
Индекс (Index) - это объект базы данных, создаваемый для повышения производительности выборки данных и контроля уникальности первичного ключа (если он задан для таблицы). Полностью индексные таблицы (index-organized tables) исполняют роль таблицы и индекса одновременно.
Табличное пространство или область (Tablespace) - это именованная часть базы данных, используемая для распределения памяти для таблиц и индексов. В Oracle 9i - это логическое имя физических файлов операционной системы. Все объекты базы данных, в которых хранятся данные, соответствуют некоторым табличным пространствам. Большинство объектов базы данных, в которых данные не хранятся, находятся в словаре данных, расположенном в табличном пространстве SYSTEM.
Кластер (Cluster) - это объект, задающий способ совместного хранения данных в нескольких или одной таблице. Одним из критериев использования кластера является наличие общих ключевых полей в нескольких таблицах, которые используются в одной и той же команде SQL. Обычно кластеризованные столбцы или таблицы хранятся в базе данных в виде таблиц хэширования (т.е. специальным образом).
Секция (Partition) - это объект базы данных, который позволяет представить объект с данными в виде совокупности подобъектов, отнесенных к различным табличным пространствам. Таким образом, секционирование позволяет распределять очень большие таблицы на нескольких жестких дисках.
Для обработки данных специальным образом или для реализации поддержки ссылочной целостности базы данных используются объекты: хранимая процедура, функция, команда, триггер, таймер и пакет (Oracle). С помощью этих объектов базы данных можно выполнять так называемую построчную обработку (record processing) данных. С точки зрения приложений баз данных построчная обработка - это последовательная выборка данных по одной строке, ее обработка и переход к обработке следующей строки.
Данные объекты реляционной базы данных представляют собой программы, т.е. исполняемый код. Этого код обычно называют серверным кодом (server-side code), поскольку он выполняется компьютером, на котором установлено ядро реляционной СУБД. Планирование и разработка такого кода является одной из задач проектировщика реляционной базы данных.
Хранимая процедура (Stored procedure) - это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных (например, SQLWindows или PL/SQL).
Функция (Function) - это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных, который при выполнении возвращает значение - результат вычислений.
Команда (Command) - это поименованный оператор SQL, который заранее откомпилирован и сохраняется в базе данных. Скорость обработки команды выше, чем у соответствующего ему оператора SQL, т.к. при этом не выполняются фазы синтаксического разбора и компиляции.
Триггер (Trigger) - это объект базы данных, который представляет собой специальную хранимую процедуру. Эта процедура запускается автоматически, когда происходит связанное с триггером событие (например, до вставки строки в таблицу).
Таймер (Timer) отличается от триггера тем, что запускающим событием для хранимой процедуры является событие таймера.
Пакет (Package) - это объект базы данных, который состоит из поименованного структурированного набора переменных, процедур и функций.
В распределенных реляционных СУБД имеются специальные объекты: снимок и связь базы данных.
Снимок (Snapshop) - локальная копия таблицы удаленной базы данных, которая используется для тиражирования (репликации) таблицы или результата запроса. Снимки могут быть модифицируемыми или предназначенными только для чтения.
Связь базы данных (Database Link) или связь с удаленной базой данных - это объект базы данных, который позволяет обратиться к объектам удаленной базы данных.Имя связи базы данных, грубо говоря, можно представить как ссылку на параметры доступа к удаленной базы данных.
Для эффективного управления разграничением доступа к данным в Oracle поддерживает объект роль.
Роль (Role) - объект базы данных, представляющий собой поименованную совокупность привилегий, которые могут назначаться пользователям, категориям пользователей или другим ролям.
Правила определения имен
Как и в любом языке, имена используются для идентификации элементов и объектов языка. В этом отношении имя есть идентификатор объекта SQL. Имена бывают длинными (до 18 символов) и короткими (до 8 символов). Также различают обыкновенный идентификатор, который начинается с буквы или символов #, @, $ и состоит из букв, цифр и символа _, и идентификатор в апострофах (Delimited Identifier), который состоит из произвольных символов, заключенных в двойные кавычки.
Объекты SQL именуются в соответствии со своей иерархией, и могут иметь квалифицируемые имена, когда имя объекта квалифицируется именем охватывающего объекта, присоединенного к имени вложенного объекта через точку. По стандарту SQL охватывающим является имя схемы, которое есть практически во всех реализациях реляционных СУБД, в том числе и в Oracle. Нижеследующие объекты SQL должны иметь уникальное имя.
Имя пользователя (Authorization ID), для идентификации которого используется короткий идентификатор, обозначающий пользователя базы данных.Колонки таблицы или представления базы данных, для идентификации которых используется, возможно, квалифицируемый длинный идентификатор. Имя колонки квалифицируется посредством либо имени таблицы, либо имени представления, либо алиасным (корреляционным) именем таблицы, назначенным в команде SQL.База данных, для идентификации которой используется короткий идентификатор, обозначающий базу данных. Имя базы данных может начинаться только с буквы и состоять из букв и цифр.Индексы таблиц, для идентификации которых используются, возможно, квалифицируемый длинный идентификатор. Имя индекса квалифицируется именем пользователя, который выдает команду, использующую данный индекс.Пароль авторизации доступа, для идентификации которого используется короткий идентификатор.Внутренние (связанные с командой SQL) переменные (Bind Variable), для идентификации которых используются обыкновенные идентификаторы или цифры с предшествующим им двоеточием.Команды SQL, для идентификации которых используются длинные идентификаторы.
Имя команды определяется пользователем.Синонимы таблиц и представлений, для идентификации которых используются длинные идентификаторы. Синонимы сохраняются в системном каталоге и используются в качестве альтернативных имен таблиц и представлений.Таблицы базы данных, для идентификации которых используются, возможно, квалифицируемые длинные идентификаторы. В качестве квалификаторов применяются имена пользователей.Представления (виртуальные таблицы) базы данных, для идентификации которых используются, возможно, квалифицируемые длинные идентификаторы. В качестве квалификаторов применяются имена пользователей.События таймера, для идентификации которых используются, возможно, квалифицируемые длинные идентификаторы. В качестве квалификаторов применяются имена пользователей. Хранимые процедуры, для идентификации которых используются, возможно, квалифицируемые длинные идентификаторы. В качестве квалификаторов применяются имена пользователей.Триггеры, для идентификации которых используются, возможно, квалифицируемые длинные идентификаторы. В качестве квалификаторов применяются имена пользователей.
Таким образом, способ именования и идентификации объектов реляционной базы данных задается отчасти их иерархией и подчиняется следующим общим правилам:
имена столбцов должны быть уникальны в таблице;имена таблиц должны быть уникальны в схеме;имена схем должны быть уникальны в каталоге (базе данных);для доступа к объекту базы данных используется квалификация имени;для идентификаторов объектов используются буквы, цифры и символы подчеркивания.
Для предметной области базы данных
Для предметной области базы данных для иллюстративных примеров можно выделить следующие основные классы объектов: подразделения (схема структурной организации фирмы), сотрудники (штатное расписание) и подчиненные им объекты (дети, родственники, например), проекты, выполняемые данной организацией.
Сотрудник как объект определяется карточкой личного учета, которая имеет весьма сложную внутреннюю структуру и которую целесообразно как теоретически, так и практически представлять совокупностью объектов, связанных в целое через ее номер (чаще всего искусственно придуманный табельный номер служащего). Аналогично, подразделение как объект определяется структурой организации и его функциями в ней. Проекты (другими словами, работы) являются объектами, которые отражают состояние деятельности организации в получении прибыли. Логическая схема базы данных приведена на рис. 8.2. Для простоты изложения большая часть атрибутов и объектов опущено - пример преследует иллюстрированные и учебные цели и не претендует на полноту представления данных.

Рис. 8.2. Логическая структура учебной базы данных
Определение таблиц данных приведено ниже. Таблица DEPARTAMENT содержит информацию о подразделениях организации, таблица EMPLOYEE - о служащих данной организации, таблица PROJECT - информацию о проектах, выполняемых в организации.
| Номер подразделения | DEPNO (PK) | Integer |
| Наименование | DNAME | char(20) |
| Размещение | LOC | char(20) |
| Руководитель | MANAGER | char(25) |
| Телефон | PHONE | CHAR(15) |
| Номер личной карточки |
| Номер личной карточки | EMPNO (PK) | Integer |
| Фамилия | ENAME | char(25) |
| Имя | LNAME | char(20) |
| Страховка | SSECNO | char(10) |
| Номер подразделения | DEPNO | Integer |
| Должность | JOB | char(25) |
| Возраст | AGE | Integer |
| Стаж | HIREDATE | Data |
| Доплаты | COMM | dec(9,2) |
| Зарплата | SAL | dec(9,2) |
| Штрафы | FINE | dec(9,2 |
| Шифр проекта | PROJNO | char(8) |
| Наименование | PNAME | char(25) |
| Стоимость | BUDGET | Number(9,2) |
Специальные функции
SQL обеспечивает набор специальных функций для преобразований значений колонок. Список таких функций приведен в таблице 8.5.
| DECODE(E,S1,R1,S2,R2,…,[def]) | Если E соответствует Si, то возвращается Ri, в противном случае - def или NULL, если умолчание не задано |
| TO_NUMBER(S) | Возвращает результат преобразования строки S в аргумент типа NUMBER |
| TO_CHAR(X[,F]) | Возвращает результат преобразования строки S в аргумент типа DATE согласно заданному формату даты F |
| TO_DATE(S[,F]) | Возвращает результат преобразования значения параметра S символьного типа в тип DATE |
В таблице EMPLOYEE для каждого служащего можно ввести признак пола - добавить колонку SEX типа CHAR(1) (0 - мужской, 1 - женский). Допустим, что вам нужен список служащих, в котором требуется разделение их по признаку пола с указанием его в числовом формате; тогда можно задать такую команду:
SELECT ENAME, LNAME, AGE, 'Пол:', TO_NUMBER(SEX) FROM EMPLOYEE ORDER BY 5;
В качестве примера использования функции DECODE приведем запрос, вычисляющий список служащих с указанием их руководителя. Если руководитель неизвестен, то выводится по умолчанию "не имеет".
SELECT ENAME, DECODE(DEPNO, 10, 'Дрягин', 20,'Жиляева', 30,' Коротков', 'не имеет') FROM EMPLOYEE ORDER BY ENAME;
Предположим, что руководитель организации имеет неопределенное значение колонки DEPNO и, следовательно, для него будет работать умолчание, предусмотренное в DECODE.
SQL и его история
Единственным средством общения и администраторов баз данных, и проектировщиков, и разработчиков, и пользователей с реляционной базой данных является структурированный язык запрос SQL (Structured Query Language). SQL есть полнофункциональный язык манипулирования данными в реляционных базах данных. В настоящее время он является общепризнанным, стандартным интерфейсом для реляционных баз данных, таких как Oracle, Informix, Sybase, DB/2, MS SQL Server и ряда других (стандарты ANSI и ISO). SQL - непроцедурный язык, который предназначен для обработки множеств, состоящих из строк и колонок таблиц реляционной базы данных. Хотя существуют его расширения, допускающие процедурную обработку. Проектировщики баз данных используют SQL для создания всех физических объектов реляционной базы данных.
Теоретические основы SQL были заложены в известной статье [Кодд], положившей начало развитию теории реляционных БД. Первая практическая реализации была выполнена в исследовательских лабораториях фирмы IBM Chamberlin D.D. и Royce R.F. Промышленное применение SQL было впервые реализовано в СУБД Ingres. Одной из первых промышленных реляционных СУБД является Oracle. По сути дела, реляционная СУБД - это программное обеспечение, которое управляет работой реляционной базы данных.
Первый международный стандарт языка SQL был принят в 1989 г. (SQL-89). В конце 1992 г. был принят новый международный стандарт SQL-92. В настоящее время большинство производителей реляционных СУБД используют его в качестве базового. Однако работы по стандартизации языка SQL далеки от завершения и уже разработан проект стандарта SQL-99, который вводит в обиход языка понятие объекта и разрешает на него ссылаться в операторах SQL. В исходном варианте SQL не было команд управления потоком данных, они появились в недавно принятом стандарте ISO/IEC 9075-5: 1996 дополнительной части SQL.
Каждой конкретной СУБД соответствует своя собственная реализация SQL, в целом поддерживающая определенный стандарт, но имеющая свои особенности. Эти реализации называются диалектами. Так, стандарт ISO/IEC 9075-5 предусматривает объекты, называемые постоянно хранимыми модулями или PSM-модулями (Persistent Stored Modules). В СУБД Oracle расширение PL/SQL является аналогом указанного выше расширения стандарта 1.
В настоящей лекции мы не
В настоящей лекции мы не определяем подробно основные объекты реляционной базы данных - базы данных, таблицы, индексы, представления, хранимые команды/процедуры, триггеры, события таймера. Это будет сделано в следующих лекциях. Данная лекция концентрирует ваше внимание на тех возможностях, которые предоставляет SQL по обработке данных.
Для иллюстрации применения команд SQL будет использована простая база данных о сотрудниках организации, ее структуре и работах, которые выполняют сотрудники, предметная область и структура которой описана в приложении 1 к лекции.