Иерархическая модель
Иерархическая модель данных организует данные в виде древовидной структуры и является реализацией логических связей между данными типа родовидовых отношений или отношений "часть-целое". Примером простого иерархического представления может служить административная структура организации.
Деревом в информатике называют совокупность корневого элемента и множества подчиненных ему элементов, в которой отношения между элементами носят подчиненный вертикальный характер. Горизонтальные связи в такой системе отношений не допускаются.
Элементы описания данных в этой модели такие же, как и в сетевой: простое поле, группа, запись, групповое отношение и БД. Существенное ее отличие от сетевой модели данных касается средств организации связей, а именно, допускаются связи между объектами модели в виде древовидной структуры.
Особенностью такого представления данных является наличие нескольких подчиненных уровней. В иерархической модели имеется корневой узел или корень дерева. Он располагается на 1-м, самом высоком уровне и не имеет узлов-предшественников. Остальные узлы называются порожденными и связаны между собой следующим образом: каждый узел имеет исходный, находящийся на вышестоящем уровне. На следующем уровне каждый узел может иметь более одного узла-потомка или не иметь потомков вовсе. Узлы, не имеющие порожденных, называются листьями. В иерархии рассматривают уровни, на которых расположен тот или иной узел или совокупность узлов.
Между исходным узлом и порожденными узлами по условию модели существует связь "один-ко-многим" (или "многие-к-одному").
Иерархия должна удовлетворять следующим условиям:
Иерархия имеет исходный узел (корень), из которого строится дерево. Каждое дерево имеет только один корень.Узел имеет непустое множество атрибутов, которые описывают объект, моделируемый в данном узле.Порожденные узлы могут добавляться в дерево как в вертикальном, так и в горизонтальном направлении.Доступ к порожденным узлам возможен только через исходный узел, поэтому существует только один путь доступа к каждому узлу.Возможно существование нескольких экземпляров каждого узла каждого уровня.
При этом каждый экземпляр исходного узла начинает логическую запись.
К основным недостаткам иерархической модели можно отнести:
сложность отображения связи "многие-к-многим"усложнение операции включения новых объектов и удаления устаревших объектов непосредственно в базе данных (в особенности обновление и удаление связей);неоднозначность представления данных о предметной области.
Пример. Пусть требуется построить иерархическую модель о преподавателях, студентах и дисциплинах, которые преподаватели преподают, а студенты изучают.
Предположим, что каждый преподаватель может читать несколько дисциплин, а каждый студент также может изучать несколько дисциплин.
Один из возможных вариантов построения иерархической модели может быть таковым. Корневым узлом является студент (Номер студента, ФИО, Номер группы). Для каждого студента при данном представлении имеется экземпляр корневого узла. Преподаватель и дисциплина объединяются в один порожденный узел (Табельный номер преподавателя, ФИО, Ученое звание, Кафедра, Дисциплина, Дата экзамена, Оценка, Зачет).
При такой организации данных достаточно легко получать ответы на запросы типа "выдать информацию о сдаче экзаменов студентами по различным дисциплинам". Однако при ответе на вопрос, какие преподаватели принимают экзамены по ВТ, необходимо просмотреть все записи порожденных узлов для каждого корневого узла. Для этого вопроса более подходит модель, в которой корневым узлом является преподаватель (Табельный номер преподавателя, ФИО, ученое звание, кафедра), а порожденным является студент (номер студента, ФИО, номер группы, дисциплина, дата сдачи, оценка, зачет).
В первом варианте модели для каждого студента дублируется информация (в экземпляре порожденного узла) о преподавателях и дисциплине, а во втором - для каждого преподавателя о студентах. Отсюда возникают проблемы включения и удаления данных. Из принципа иерархии следует, что экземпляр порожденного узла не может существовать в отсутствие соответствующего ему экземпляра исходного узла.
Таким образом, невозможно без привлечения дополнительных способов включить в базу данных информацию о преподавателях, которые не принимают экзамены (для первого варианта схемы). Чтобы соблюсти принцип иерархии, нужно сформировать, например, пустой исходный узел и породить еще проблему интерпретации нуль-значений.
При удалении исходного узла автоматически удаляются экземпляры порожденных узлов. Так, для второго варианта представления модели удаления сведения о преподавателе (уволился) удаляются все сведения о студентах, у него обучавшихся, а следовательно, теряется информация, необходимая для оценки качества обучения студентов.
Первопричиной этих проблем является то обстоятельство, что иерархическая модель не поддерживает отношение M:N.
Основной единицей обработки здесь является запись, к которой применимы операции ЗАПОМНИТЬ, МОДИФИЦИРОВАТЬ, УДАЛИТЬ, ИЗВЛЕЧЬ, НАЙТИ. В операциях создания и уничтожения связей для этой модели нет необходимости потому, что все связи предопределены заранее древовидной структурой отношений. Операция "найти" сводится к одной из трех процедур обхода дерева.
При использовании иерархической модели актуальной является проблема отслеживания связей, хотя и в более простом варианте. К возможным недостаткам иерархической модели можно отнести вероятную асимметрию отношений между сущностями предметной области БД и неудобство в отображении горизонтальных связей, которые нужно выражать через вертикальные связи.
Информация и данные
Прежде чем перейти к обсуждению понятия информационной системы (ИС), попытаемся выяснить, что же понимается под словом информация. Ответить на этот вопрос и просто, и сложно: слово "информация" связано с широким кругом понятий, в том числе и определенных строго математически (информация по Шеннону, например).
Содержательная же сторона понятия "информация" очень многогранна и не имеет четких семантических границ. Однако всегда можно сказать, что можно с ней делать. Именно ответ на этот вопрос чаще всего и интересует как системных аналитиков и разработчиков (ИС), так и пользователей информации (ее основных потребителей).
С точки зрения как пользователей, так и разработчиков ИС, у информации есть одно важное свойство - она является единицей данных, подлежащих обработке. Обычно информация поступает потребителю именно в виде данных: таблиц, графиков, рисунков, фильмов, устных сообщений, которые фиксируют в себе информацию определенной структуры и типа. Таким образом, данные выступают как способ представления информации в определенной, фиксированной форме, пригодной для обработки, хранения и передачи. Хотя очень часто термины "информация" и "данные" выступают как синонимы (особенно в среде разработчиков ИС), следует помнить об этом их существенном отличии. Именно в данных информация обретает интерпретацию в конкретной ИС.
При упоминании о "форме" представления информации следует сказать и еще об одном, "человеческом" свойстве информации - ее восприятии различными категориями людей. Данные могут быть сгруппированы совместно в документ. Документ может иметь или не иметь определенную внутреннюю структуру. Данные могут быть отображены на экране дисплея компьютера. Документы могут иметь аудио- или видеоформу. Разрабатывая ИС, никогда не следует забывать, для кого они (системы) создаются и кто будет их использовать (воспринимать информацию в них). Форма представления информации в ИС определяет не только ее "дружелюбие", но также и категории пользователей. ИС создаются для конкретных групп пользователей, т.е. они, как правило, проблемно-ориентированны.
Информация как социальный ресурс
За три последних десятилетия стало общепризнанным, что информация является не менее важным ресурсом человеческого общества, чем сырье, энергия и пища. Можно утверждать, что практически в любом виде человеческой деятельности требуется удовлетворение информационных потребностей в той или иной степени. Так, например, собираясь на улицу, мы всегда хотим получить информацию о погоде. Большинство из нас в том или ином виде ежедневно получают различную информацию из газет, радио, телепередач, Интернета. Не говоря уже об источниках профессиональной информации.
Развитие систем связи и коммуникаций привело к усложнению и дифференциации информационных процессов в человеческом обществе. Способность накапливать информацию и обеспечивать эффективный доступ к ней становится определяющим фактором не только развития человеческого общества, но и поддержания его жизнеспособности. Быстрый рост объемов информации, закрепленной на внешних по отношению к человеку носителях, привел к появлению новых общественных институтов (библиотеки, архивы, пресса, вычислительные центры и т. д.) и специальных систем (службы научно-технической информации, справочные службы, глобальные информационные компьютерные сети).
Развитие средств вычислительной техники и информационных технологий открыло новые возможности и способы хранения, представления и поиска информации, в частности, создание вычислительных систем, "доступных по требованию" - т.е. вычислительные ресурсы становятся таким же доступным ресурсом для потребления человеком, как электроэнергия, природный газ, вода.
Таким образом, резко возрастают требования к качеству и надежности проектирования систем для работы с информацией, представляемой в электронном виде.
Информационная модель данных
На рис. 1.6 иллюстрируется общее содержание понятия модели данных, сложившееся к настоящему времени.

Рис. 1.6. Представление об информационной модели данных
Объектами информационной модели являются сущности реального мира из предметной области. Иногда их называют итемами, чтобы подчеркнуть их целостность. Свойства объектов (сущностей) называют атрибутами. Сущности вступают в связи друг с другом через свои атрибуты. Эти три компонента информационной модели представляют субъективные средства описания модели, которые после определенной формализации дают внешнюю схему данных БД ИС.
Информационные системы
Основной целью создания ИС является удовлетворение информационных потребностей пользователей путем предоставления необходимой им информации на основе хранимых данных. Потребность в информации как таковой не исчерпывает понятия информационных потребностей. Обычно в понятие информационных потребностей включают определенные требования к качеству информационного обслуживания и поведению системы в целом (производительность, актуальность и надежность данных, ориентация на пользователя и ряд других, о чем мы поговорим позже).
Определение 2. Под информационной системой понимается организационная совокупность технических и обеспечивающих средств, технологических процессов и кадров, реализующих функции сбора, обработки, хранения, поиска, выдачи и передачи информации.
Необходимость повышения производительности труда в сфере информационной деятельности приводит к тому, что в качестве внешних средств хранения и быстрого доступа к информации чаще всего используются средства вычислительной техники (цифровой и аналоговой) на основе компьютеров. Современные ИС - сложные комплексы аппаратных и программных средств, технологии и персонала, которые еще называют автоматизированными информационными системами. Структурно ИС включают в себя аппаратное (hardware), программное (software), коммуникационное (netware), промежуточного слоя (middleware), лингвистическое и организационно-технологическое обеспечение.
Аппаратное обеспечение ИС включает в себя широкий набор средств вычислительной техники, средства передачи данных, а также целый ряд специальных технических устройств (устройства графического отображения информации, аудио- и видеоустройства, средства речевого ввода и т.д.). Аппаратное обеспечение является основой любой ИС.
Коммуникационное (сетевое) обеспечение включает в себя комплекс аппаратных сетевых коммуникаций и программных средств поддержки коммуникаций в ИС. Оно имеет существенное значение при создании распределенных ИС и ИС на основе Интернета. При создании распределенных ИС огромную роль также играет программное обеспечение промежуточного слоя, состоящее из набора программных средств (служб и сервисов), которые управляют взаимодействием распределенных объектов в системе.
Программное обеспечение ИС обеспечивает реализацию функций ввода данных, их размещения на машиночитаемых носителях, модификации данных, доступ к данным, поддержку функционирования оборудования. Программное обеспечение можно разделить на системное (которое венчает процесс выбора аппаратно-программного решения, или платформы, как говорят в настоящее время) и пользовательское (которое применяется для решения задач удовлетворения потребностей пользователя в компьютерной среде, а именно, реализует бизнес-логику).
Лингвистическое обеспечение ИС предназначено для решения задач формализации смыслового содержания полнотекстовой и специальной информации для создания поискового образа данных (профиля). В классическом смысле обычно оно включает процедуры индексирования текстов, их классификацию и тематическую рубрикацию. Зачастую ИС, содержащие сложно-структурированную информацию, включают в себя тезаурусы терминов и понятий (средства поддержки метаданных). Сюда можно отнести и создание процессоров специализированных формальных языков конечных пользователей, например языков для манипулирования бухгалтерской информацией и т.д. Чаще всего работам по разработке лингвистического обеспечения не придается должного значения. Подобные упущения чаще всего ведут к неприятию пользователями самой системы и, как следствие, к ее закономерной гибели. Это относится в первую очередь к узко специализированным ИС.
По мере возрастания сложности и масштабов ИС важную роль начинает играть организационно-технологическое обеспечение, которое соединяет разнородные компоненты (аппаратуру, программы и персонал) в единую систему и обеспечивает процедуры ее управления и функционирования. Недооценка этой составляющей ИС чаще всего приводит к срыву сроков внедрения системы и вывода ее на производственные мощности.
На рис. 1.2 просуммированы в общих чертах функции ИС через ее основные структурные компоненты.

Рис. 1.2. Определение информационной системы
Итерационная процедура построения информационных систем
В чем состоит преимущество ориентации на автоматизацию основных бизнес-процессов при автоматизации организации или предприятия? Традиционно и повсеместно используемым подходом (особенно на начальных этапах развития информационной инфраструктуры организации) является применение так называемого позадачного метода решения задач автоматизации, направленного на решение достаточно простых и понятных руководству задач.
Например, учет заказов, выписка счетов, подготовка документов. Конъюнктурное преимущество такого метода очевидно: достаточно быстро может быть получен результат, существование модной ныне ИТ-службы оправдано, внутренние инвестиции быстро вернулись. В принципе, с точки зрения системного анализа это является порочной практикой. Однако он существует, поскольку позволяет, с одной стороны, вроде бы не отставать от жизни (наличие ИС в организации зачастую является одним из определяющих факторов ее конкурентоспособности), а с другой - экономить денежные средства на автоматизации. Вышеуказанный подход позволяет использовать служащих с невысокой квалификацией. Рано или поздно это становится тормозом в развитии информационной инфраструктуры организации.
Низкая отдача уже существующей ИС организации на текущем этапе ее эксплуатации также становится тормозящим фактором. Изменение направлений бизнеса организации и ряд других факторов приводят к вопросу пересмотра отношения к ИС в организации, т.е. к извечному вопросу - переделать или начать с начала. Начать сначала всегда выгодней. Можно применить уже хорошо отработанные в информатике методики проектирования "сверху-вниз" или "снизу-верх". Однако рано или поздно опять встанет вопрос о соответствии требованиям сегодняшнего дня.
Даже в тех случаях реализации ИС, которые одобряются системным анализом, не удается избежать переделки ИС, т.к. она, как органическая часть производственного процесса, должна следовать и отвечать стратегическому генеральному бизнес-плану развития организации. Такой план всегда должен быть, если организация собирается долго жить в своем секторе рынка.
Разработчики ИС фактически всегда находятся в методике "из-середины" (midlle of design). Есть некоторая основа (уже созданная или создаваемая), и вокруг нее следует развиваться в различных направлениях, не сильно ломая сложившиеся традиции. Таким образом, постулируется итерационный подход в разработке и создании информационных систем. И, как следует из вышесказанного, он определяется не желанием теоретиков ИС, а жизненной необходимостью.
Основным подходом в таких переделках (так же, как и при создании) ИС является концепция реинжиниринга, суть которого сводится к постоянному моделированию информационных процессов и данных организации и их отображения в существующей системе.
Что является основной особенностью технологии реализации итерационного подхода разработки и сопровождения ИС? Основная особенность реализации концепции разработки ИС, ориентированной на интегрированные процессы, - это наличие или отсутствие сборочного конвейера, поскольку необходимо собирать воедино многие технологические процессы обработки информации. При объединении технологических процессов обработки информации увеличивается скорость прохождения информации в системе, принятие решений на основе информационных потоков становится частью процесса обработки информации (и более состоятельной), уменьшается иерархия управленческих структур.
Следует также иметь в виду, что наличие в организации корпоративной ИС зачастую меняет представление пользователей о том, как информация должна циркулировать в организации, что является еще одним важным стимулом модернизации ИС. ИС - составляющая и несущая часть пирамиды обработки информации. Поэтому в процессе разработки и реализации ИС приходится перестраивать как бизнес-процессы, так и бизнес-правила и их взаимодействие, что и составляет основу реинжиниринга.
Для того чтобы ИС жила долго и ее эксплуатация приносила ощутимую выгоду, необходимо тщательно проектировать и ее архитектуру, и ее составные компоненты, в частности базы данных, о которых пойдет речь ниже.
Разработчики ИС фактически всегда находятся в методике "из-середины" (midlle of design). Есть некоторая основа (уже созданная или создаваемая), и вокруг нее следует развиваться в различных направлениях, не сильно ломая сложившиеся традиции. Таким образом, постулируется итерационный подход в разработке и создании информационных систем. И, как следует из вышесказанного, он определяется не желанием теоретиков ИС, а жизненной необходимостью.
Основным подходом в таких переделках (так же, как и при создании) ИС является концепция реинжиниринга, суть которого сводится к постоянному моделированию информационных процессов и данных организации и их отображения в существующей системе.
Что является основной особенностью технологии реализации итерационного подхода разработки и сопровождения ИС? Основная особенность реализации концепции разработки ИС, ориентированной на интегрированные процессы, - это наличие или отсутствие сборочного конвейера, поскольку необходимо собирать воедино многие технологические процессы обработки информации. При объединении технологических процессов обработки информации увеличивается скорость прохождения информации в системе, принятие решений на основе информационных потоков становится частью процесса обработки информации (и более состоятельной), уменьшается иерархия управленческих структур.
Следует также иметь в виду, что наличие в организации корпоративной ИС зачастую меняет представление пользователей о том, как информация должна циркулировать в организации, что является еще одним важным стимулом модернизации ИС. ИС - составляющая и несущая часть пирамиды обработки информации. Поэтому в процессе разработки и реализации ИС приходится перестраивать как бизнес-процессы, так и бизнес-правила и их взаимодействие, что и составляет основу реинжиниринга.
Для того чтобы ИС жила долго и ее эксплуатация приносила ощутимую выгоду, необходимо тщательно проектировать и ее архитектуру, и ее составные компоненты, в частности базы данных, о которых пойдет речь ниже.
Концепция баз данных
Подавляющее большинство компьютеров, которые используются для аппаратного обеспечения создателями ИС, являются компьютерами фон Неймана. Основная идея, положенная в основу создания компьютера фон Неймана, состоит в том, что компьютер представляет собой вычислительную машину с загружаемым в его память кодом - программами и данными. В процессе своей работы такая машина интерпретирует код и различает программы (исполняемый код) и данные (неисполняемый код).
Подавляющее большинство компьютеров, которые используются для аппаратного обеспечения создателями ИС, являются компьютерами фон Неймана. Основная идея, положенная в основу создания компьютера фон Неймана, состоит в том, что компьютер представляет собой вычислительную машину с загружаемым в его память кодом - программами и данными. В процессе своей работы такая машина интерпретирует код и различает программы (исполняемый код) и данные (неисполняемый код).
Идея повышения степени независимости обрабатывающих программ от способов хранения и содержания хранимых данных впервые была использована в концепции баз данных путем разделения логического и физического уровней хранения данных в 1964 году в исследованиях сотрудников фирмы IBM.
Что же принято понимать под базой данных? Базу данных в общем случае можно определить как унифицированную совокупность хранимых и воспроизводимых данных, используемых в рамках организации (Engles R.A., 1972 г.). Однако понятие базы данных не основывается в настоящее время на единой концепции, скорее это целое семейство связанных между собой понятий из области предметной области, программного и аппаратного обеспечения, анализа и моделирования данных и приложений. Мы дадим несколько определений базы данных.
Определение 3. База данных.
(По Дж. Мартину) База данных есть совокупность взаимосвязанных данных, совместно используемых несколькими приложениями и хранящимися с (минимальной) регулируемой избыточностью. Данные запоминаются таким образом, чтобы они, по мере возможности, не зависели от программ. Для обработки данных применяется общий управляющий метод доступа. Если базы данных не пересекаются по структуре, то говорят о системе баз данных.(Согласно материалам комитета КОДАСИЛ) База данных состоит из всех экземпляра записей, экземпляров наборов записей и областей, которые контролируются конкретной схемой. (Под схемой можно понимать карту всей логической структуры базы данных. Определение понятия схемы по КОДАСИЛ будет дано при обсуждении сетевой модели данных).
Для разработчика ИС существенным моментом при использовании концепции баз данных является то обстоятельство, что данные становятся определенным образом организованы, приобретают некую упорядоченность и внутреннюю структуру, а также то, что имеется некоторый набор унифицированных операций обработки данных и декларативных средств представления данных. К таким операциям следует отнести операции "Вставить" (Insert), "Добавить" (Add), "Удалить" (Delete) и ряд других. К декларативным средствам представления данных следует отнести языки определения данных. То есть использование данной концепции при создании ИС предполагает наличие языка определения данных и языка манипулирования данными, а также правил построения интерфейсов программ (приложений) с БД и пользователем.
Такое деление средств манипулирования данными и их представления является в определенной степени условным. Язык определения данных служит для описания логической структуры (схемы) БД, а в некоторых случаях и способов хранения и доступа к данным. Язык манипулирования данными предоставляет алгоритмические средства построения приложений для обработки сохраняемых в БД элементов данных.
Концепция трех схем
В рамках информационного моделирования существует несколько точек зрения (схем) на абстрагирование данных. С точки зрения пользователя (называемой внешней схемой), определение данных представляется в контексте языка предметной области. Структура данных и содержание меняется в зависимости от сферы деятельности и особенностей конкретного пользователя. С точки зрения компьютера (называемой внутренней схемой), данные определяются в терминах файловых структур для хранения и поиска. Структура данных в этом случае зависит от конкретной компьютерной технологии и от требований эффективности обработки данных.
При моделировании информации на основе разработки только внешней и внутренней схем по-прежнему остаются трудными для решения проблемы избыточности и противоречивости данных. Хотя СУБД значительно расширяет возможности совместного использования данных, все же ее применение не гарантирует непротиворечивости определения данных.
Исследовательская группа по СУБД ANSI/X3/SPARC пришла к выводу, что для создания идеальной среды управления данными необходимо определение их с третьей, промежуточной точки зрения (концепция трех схем ANSI/X3/SPARC). Эта точка зрения (называемая концептуальной схемой) сводится к единообразному определению данных в рамках предметной области, не ориентированному на какое-либо конкретное использование их и не зависящему от того, как данные физически обрабатываются на компьютере (рис. 1.7).

Рис. 1.7. Концепция трех схем
Основной целью концептуальной схемы является выработка непротиворечивой интерпретации определения взаимосвязей данных для их объединения, совместного использования и управления целостностью данных.
С другой стороны, любая информационная модель данных определяется средствами поддержки модели данных, реализуемыми СУБД.
Модели вычислений
Взгляд на использование компьютеров меняется в процессе их применения в различных сферах человеческого труда: большие вычислительные центры с мощными компьютерами, средние по мощности ЭВМ для автоматизации технологических процессов, персональные компьютеры, компьютеры, объединенные сетью коммуникаций. Неизменным остается требование пользователей к вычислительным ресурсам для удовлетворения потребностей в информации - время процессора (быстродействие), оперативная память, дисковое пространство и т.п. Проблема совместного использования ресурсов является одной из ключевых проблем решения любых прикладных задач на ЭВМ, в том числе и создания ИС. Решение этой проблемы приводит к разработке новых компьютерных технологий, которые являются сложным синтезом изменений в аппаратном и программном обеспечении. Основой таких модификаций как аппаратного, так и программного обеспечения являются модели вычислений.
Что принято понимать под моделью вычислений? Обычно под моделью вычислений подразумевают совокупность аппаратно-программных средств, схему их взаимодействия между собой и пользователями, т.е. постулируется ответ на вопросы, каким образом и какие вычислительные ресурсы используются в процессе выполнения вычислений. Поскольку понятие модели вычислений связано как и с аппаратным, так и с программным обеспечением, то нередко в качестве синонима слова модель используется слово архитектура. За всю историю развития вычислительной техники было предложено не так уж много моделей вычислений.
Централизованные вычисления:
модель вычислений с использованием централизованной хост-ЭВМ;модель с автономными персональными вычислениями;
Распределенные вычисления:
модель вычислений "файл-сервер";модель вычислений "клиент-сервер";модель "вычисление по требованию".
Исторически одной из первых моделей вычислений является модель с использованием централизованной хост-ЭВМ. В такой схеме вычислений пользователь получает доступ к вычислительным ресурсам ЭВМ через сеть неинтеллектуальных терминалов (т.е.
терминалов, не обладающих никакими вычислительными возможностями). Центральный компьютер полностью отвечает за взаимодействие с пользователем и управление данными в многопользовательской среде.
Преимуществом такой модели вычислений является их централизация. Централизованные системы позволяют совместно использовать вычислительные ресурсы (диски, принтеры, оперативную память) с высокой эффективностью, а также обеспечивать высокую надежность и актуальность хранимых данных.
Самым большим недостатком такой схемы вычислений является линейная зависимость вычислительной мощности центральной ЭВМ от числа пользователей и, как следствие, высокая стоимость аппаратуры и программного обеспечения. Несмотря на устойчивую тенденцию снижения стоимости оборудования, такие системы по-прежнему остаются одними из дорогостоящих (отношение "цена/производительность" остается достаточно высокой).
В 80-е годы прошлого века появились персональные компьютеры и рабочие станции. Независимые друг от друга, предоставляющие вычислительные возможности, которые сопоставимы с большими ЭВМ, доступные по цене широкому кругу потребителей (отношение "цена/производительность" в данном случае гораздо ниже, чем при использовании больших ЭВМ). Персональные компьютеры положили конец централизованному подходу в обработке данных и обозначили переход к распределенным вычислениям.
Преимуществом такой модели вычислений является их автономность в использовании вычислительных ресурсов, т.е. централизованное использование компьютера, но на рабочем месте и независимо от других таких же компьютеров. В данном случае можно подобрать персональный компьютер адекватно решаемому кругу задач.
Однако у независимых персональных вычислений есть и свои проблемы. Эти проблемы порождают распределенность данных (невозможность совместной работы с данными различных пользователей) по персональным компьютерам в случае, когда эти данные должны использоваться совместно в рамках одной организации. При этом выигрыш в отношении "цена/производительность" компенсируется потерями в производительности труда коллективов, работающих с распределенными таким образом данными.
Проблемы совместного использования данных, расположенных на персональных компьютерах, привели к разработке концепции локальной вычислительной сети, которая восстанавливает преимущества коллективных вычислений и сохраняет простоту использования персональных компьютеров. Наличие вычислительной сети компьютеров характерно для всех моделей распределенных вычислений.
Модель вычислений "файл-сервер" (или архитектура "файл-сервер") основывается на понятии сервера. Термин сервер имеет двойственный смысл. С одной стороны, сервер есть узел вычислительной сети (компьютер с сети), предназначенный для предоставления совместно используемых ресурсов и услуг, а с другой - программный компонент, предоставляющий общий функциональный сервис другим программным компонентам вычислительной сети.
Файловый сервер является обычно центральным узлом сети, на котором хранятся файлы коллективного пользования и который является также концентратором совместно используемых периферийных устройств (например, принтера или дискового накопителя большой емкости). Файловый сервер не принимает участия в обработке приложения. Он выполняет сетевой транспорт совместно используемых данных (часто пересылая файл целиком конечному пользователю).
Преимуществом такой модели является, несомненно, корпоративное использование территориально распределенных вычислительных ресурсов, имеющее одним из своих следствий создание глобальных вычислительных систем и новых технологий обмена информацией.
Однако у такой модели есть два крупных недостатка при разработке многопользовательских приложений. Интенсивный обмен данными (рост трафика сети) приводит к быстрому достижению ее пропускной способности и тем самым к снижению (из-за увеличения времени реакции приложения за счет времени ожидания) производительности многопользовательской системы.
Другая проблема - это обеспечение согласованности данных, т.е. одновременного разделения доступа к одним и тем же данным группой пользователей. Обычно файл блокируется для других пользователей, когда его начинает обрабатывать приложение.
В случае, когда часть файла реплицируется на конечный узел для обработки, снижается актуализация данных, что может быть неприемлемо для систем оперативной обработки информации.
Модель вычислений "клиент-сервер" явилась следующим шагом в развитии распределенных вычислений, объединив в себе преимущества коллективных вычислений в сети компьютеров с доступом к совместно используемым данным и высокие характеристики производительности вычислений с центральной ЭВМ. Основными понятиями данной модели являются сервер баз данных, клиентское приложение и сеть.
Основное назначение сервера баз данных - оптимальное управление разделяемыми ресурсами на уровне данных для множества клиентов. На этом уровне достаточно эффективно решаются задачи обеспечения согласованности данных, их актуальности, защиты и целостности.
Клиентское приложение является частью системы, которая обеспечивает интерфейс приложения с серверов баз данных. Логика приложения может быть полностью реализована на клиентской части системы, а обработку данных забирает на себя сервер баз данных.
Сеть и коммуникационное программное обеспечение являются средствами передачи данных. Реализация этой компоненты модели обеспечивает прозрачность сервера баз данных по отношению к клиенту.
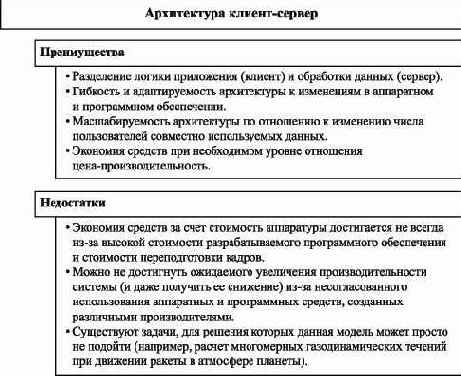
Рис. 1.10. Преимущества и недостатки модели вычислений "клиент-сервер"
Несмотря на то, что модель вычислений "клиент-сервер" является высокопроизводительной распределенной моделью вычислений, она, помимо очевидных преимуществ, имеет присущие ей недостатки (рис. 1.10). Кроме того, другие модели вычислений также продолжают развиваться, обеспечивая приемлемые значения отношения "цена-производительность".
Модель "вычисления по требованию" или GRID является в настоящее время одной из перспективных распределенных моделей вычислений. Суть ее состоит в использовании вычислительных ресурсов, расположенных в локальной или глобальной вычислительной сети, аналогично тому, как мы в быту используем электричество, совершенно не отдавая себе отчета в том, с какой электростанции оно поступает к нам в дом.
В этой модели вычислений заявленные в сети GRID вычислительные ресурсы (компьютеры или кластеры ЭВМ) предоставляют свои свободные вычислительные ресурсы согласно правилам обслуживания заданий в очереди. Таким образом, находясь в России, вы можете запустить свою задачу на компьютере в Австралии, совершенно об этом не зная.
В этой лекции мы рассмотрели ряд основных понятий и терминов, которые потребуются проектировщику реляционных баз данных в процессе решения им своих профессиональных задач. В последующих лекциях мы последовательно и детально рассмотрим основные профессиональные задачи проектировщика реляционных баз данных.
Литература: [1], [2], [10], [12], [21], [29], [34], [36], [40], [41], [47].
Общие принципы классификации СУБД
Очень часто СУБД классифицируются по типу модели данных, которую они поддерживают. Следовательно, различают СУБД сетевые, иерархические и реляционные. Однако в практике обработки данных СУБД характеризуются по их способности поддерживать определенный тип БД. В самом общем виде БД подразделяют на:
фактографические, которые хранят совокупность фактов интегрированных, возможно, из различных документов;документальные, которые ориентированы на хранение документов;документально-фактографические, которые обладают чертами и тех и других.
Так, СУБД CDS/ISIS в первую очередь ориентирована на поддержку работы с документом, который состоит из определенного числа рубрик, проиндексированных по тезаурусу ключевых слов. СУБД ADABAS хорошо подходит для организации фактографических БД, а СУБД ORACLE - для БД смешанного типа. Во избежание несуразностей с использованием определенной модели данных, БД, за редким исключением, целесообразно классифицировать по типу используемой модели в СУБД. Отметим, что классификация БД далеко не завершенная область исследований: попытки ввести новые типы БД продолжаются (активные, дедуктивные, нечеткие реляционные, графические БД и т.д.).
Во многих случаях для разработчиков ИС бывает важно деление СУБД (и БД) по характеру обработки: на централизованные и распределенные. При использовании распределенной обработки следует обратить внимание на характер обработки транзакций, т.к. последние оказывают существенное влияние на производительность системы. Под транзакцией в самом общем случае понимают единицу работы, требуемой пользователем от БД, независимо от характера обработки. Чаще всего в результате обработки транзакции реализуется запрос пользователя либо на выборку данных из БД, либо на обновление БД, либо на выполнение каких-то иных действий над БД. При этом предполагается, что выполнение запроса сопровождается выполнением комплекса внутрисистемных действий СУБД, направленных на поддержание целостности данных, разграничение доступа и т.п.
Существуют различные концептуальные подходы к обработке транзакций при распределенной обработке. Принципиальным здесь является не только вопрос как, но и где локализуется обработка транзакции: на файлах компьютера конечного пользователя или на выделенном в сети компьютере. От выбора той или иной концепции будет зависеть время отклика системы на запрос пользователя. Параметр "время отклика системы на запрос пользователя" очень часто выступает в качестве определяющего или желательного параметра разрабатываемой системы. Например, для распределенной системы бронирования авиабилетов для крупнейших мировых авиакомпаний этот параметр является существенным и закладывается в проектное решение как не превышающий 30-45 секунд.
Обзор основных моделей данных
Тремя основными типами моделей структурированных данных являются иерархическая, сетевая и реляционная. Первые две из них основаны на представлении информации об объектах в виде плоского графа.
Определение понятия информации
Теперь мы готовы дать следующее определение информации в применении к ИС.
Определение 1. Информация есть данные, которым придается некоторый смысл (интерпретация) в конкретной ситуации в рамках некоторой системы понятий. Информация представляется посредством кодирования данных и извлекается путем их декодирования и интерпретации.
В этом определении фиксируется три основных преобразования информации и данных в процессе их обработки в ИС: информация-данные, данные-данные, данные-информация.
Рассмотрим пример с классической ИС - библиотекой. Книга поступает в библиотеку. На нее заводятся библиографические карточки (выполняется преобразование информация-данные). Библиографические карточки размещаются в каталогах в соответствии с внутренними библиотечными процедурами систематизации (выполняется преобразование "данные-данные"). Читатели работают с каталогами библиографических карточек в поисках нужных им книг (выполняется преобразование данные-информация). Аналогичным образом можно рассмотреть процесс продажи товара через склад и многие другие сферы человеческой деятельности.
Заметим, что вопрос о преобразовании информация-информация, которое также имеет прямое отношение к ИС, не фигурирует явно в данном рассмотрении. Это преобразование имеет прямое отношение к производству новых знаний. Производство новых знаний относится к разработке систем искусственного интеллекта и не затрагивается непосредственно в данных лекциях.
На рис. 1.1 представлены две стороны определения понятия информации: функциональная и представительная. Первая в общих чертах определяет круг действий над информацией, а вторая - результат выполнения этих действий.

Рис. 1.1. Содержание термина "информация"
При разработке ИС важно отличать собственно генерацию информации и поддержку ее актуальности (соответствия текущему моменту) от процедур ее оформления для потребления пользователем.
Основные подходы к обработке информации в автоматизированных информационных системах
Одним из главных вопросов разработки программного обеспечения ИС (и программирования как самостоятельной дисциплины) является вопрос о соотнесении программ и данных, ибо решение этого вопроса, в конечном счете, определяет выбор алгоритмов обработки информации, аппаратных средств и технологической платформы. Фундаментальным принципом в решении вопроса о соотнесении программ и данных является концепция независимости прикладных программ от данных, и неважно, какая обработка данных предполагается: централизованная или распределенная. Суть этой концепции состоит не столько в отделении программ от данных, сколько в рассмотрении их как самостоятельных взаимодействующих объектов.
Одной из последних модификаций этого принципа является концепция независимости прикладных программ от данных вместе с процедурами их обработки (объектно-ориентированный подход в программировании), который позволяет решить ряд вопросов обработки данных, связанных с интерпретацией семантического смысла данных.
Торжество концепции независимости программ от данных привело к формированию в 1962 году концепции базы данных (БД) и созданию на ее основе метода баз данных для решения задач обработки информации. До середины 60-х годов прошлого века основной концепцией построения программного обеспечения являлась концепция файловой системы и так называемый позадачный метод. Такой подход по-прежнему остается доминирующим в разработке и функционировании несущих операционных платформ. В конце 80-х годов прошлого века была предложена концепция объектно-ориентированных баз данных и объектно-ориентированный подход разработки программ на основе обработки событий. На рис. 1.3 представлены основные черты для каждой из указанных выше концепций. На рис. 1.4 проведено сопоставление основных методов обработки данных.

Рис. 1.3. Основные концепции обработки информации

Рис. 1.4. Основные методы обработки информации
Основной смысл объектной технологии состоит в том, что программы рассматриваются как совокупность объектов. Объекту присущи следующие свойства:
Инкапсуляция. Объекты наделяются структурой и обладают определенным поведением (набором операций). Операции над объектами составляют его методы. Структура объекта скрыта от пользователя, который манипулирует с объектом через его операции. Объект рассматривается как абстракция реального мира. Для того чтобы объект выполнил некоторое действие, ему нужно послать сообщение. Объект взаимодействует с другими объектами через события.Наследование. Представляет собой механизм, позволяющий производить одни объекты из других, при этом свойства родительского объекта сохраняются у потомка.Полиморфизм. Различные объекты могут получать одинаковые сообщения, но реагировать на них по-разному, в соответствии с реализацией своих одноименных методов.
Основные типы моделей и их эквивалентность
Наличие в СУБД определенной, допустимой структуры данных приводит к понятию баз структурированных данных, то есть данные в таких БД должны быть представлены как совокупность взаимосвязанных элементов. Если допустить возможность порождения новых типов и динамический процесс установления связей (во время появления объекта в БД), то мы придем к понятию баз неструктурированных данных. Допустимы и промежуточные варианты, которые носят название БД с частично детерминированной схемой. Такое деление БД с точки зрения степени структурированности сохраняемых данных оказывается существенным моментом при выборе несущей СУБД для реализации ИС, поскольку конкретная СУБД обычно поддерживает определенную модель данных. С другой стороны, следует иметь в виду, что для каждого из приведенных типов БД используются соответствующие модели данных, т.е. существует некоторое множество моделей данных.
В настоящее время для баз структурированных данных различают три основных типа логических моделей данных в зависимости от характера поддерживаемых ими связей между элементами данных - сетевую, иерархическую и реляционную. Классифицирующими признаками в этих моделях являются: степень жесткости (фиксации) связи, математическое представление структуры модели и допустимые типы данных (см. таблицу 1.1). Допустимые типы данных будут обсуждаться далее при изучении реляционной модели.
| Сетевая | Полужесткие связи | Произвольный граф |
| Иерархическая | Жесткие связи | Древовидная структура |
| Реляционная | Изменчивые связи | Плоский файл |
Рис. 1.8 иллюстрирует особенности каждой модели данных. При сопоставлении моделей следует помнить, что все они теоретически эквивалентны. Эквивалентность моделей состоит в том, что они могут быть сведены одна к другой путем формальных преобразований. Подробное доказательство этого факта можно найти в классической монографии Дж. Мартина по БД. Суть доказательства состоит в отказе от принципа избыточности данных, то есть разрешается дублировать данные в узлах представления. Тогда преобразование одной модели в другую получается простым удвоением вершин соответствующего представления в цепочке моделей "сетевая-иерархическая-реляционная".
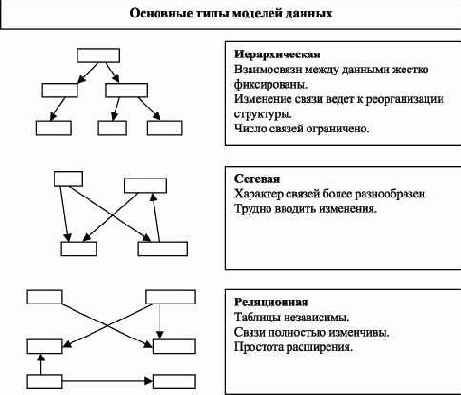
Рис. 1.8. Основные типы моделей данных
Понятие о модели данных
В предыдущих разделах все время подчеркивалась роль представления данных в решении задач обработки информации (принцип независимости программ от данных, концепция баз данных и т.д.). Представление информации с помощью данных требует унифицированного подхода к понятию данных как независимого объекта моделирования. Поэтому для разработчика ИС выбор соответствующей модели данных является одной из самых важных проблем. Выбор модели данных влечет за собой выбор средств анализа предметной области (ПО БД) как сферы реального мира, подлежащего изучению и обработке средствами ВТ, - об этом мы будем говорить в следующей лекции. В конечном счете такой выбор делает разработчика "заложником" той или иной информационной технологии создания информационных систем с базами данных.
Модель данных ограничивает возможность выбора СУБД, так как обычно отдельно взятая модель поддерживает определенную модель данных.Модель данных определяет и методы создания дружественного интерфейса пользователя за счет средств СУБД (особенности конкретной реализации модели (замкнутость на свою среду), иногда весьма существенные, ибо коммерческие интересы фирм - разработчиков СУБД вступают в противоречие с требованиями рынка информационных услуг).Модель данных требует приведения представлений пользователя о данных и результатах их обработки к определенному уровню понимания, что может повлечь за собой необходимость обучения пользователя методам и средствам работы с данными (необходимость использования моделей высокого уровня для описания семантики предметной области информационной системы, желательно возможностью использования средств реинжиниринга).
Таким образом, понятие модели данных является одним из фундаментальных понятий информатики, от которого во многом зависят механизмы реализации ИС как программно-аппаратного комплекса.
Что же такое модели данных? В самом общем случае модель данных - это логическое представление данных и совокупность операций над ними.
Определение 5. Модель данных (Data Model) есть логическая структура данных, которая представляет присущие этим данным свойства, не зависимые от аппаратного и программного обеспечения и не связанные с функционированием компьютера.
Можно рассмотреть несколько аспектов моделирования в обработке данных:
информационное моделирование: концептуальное моделирование (моделирование семантики предметной области);логическое моделирование данных;физическое моделирование: создание моделей доступа к данным;оптимизация физической организации данных в аппаратной среде.
Физическая модель определяется особенностями устройств хранения информации и связи. Поскольку мы в наших лекциях не занимаемся разработкой методов доступа и СУБД, то вопросы физического моделирования данных рассматриваться не будут.
Сетевая модель данных
Остановимся на понятии сетевой структуры, положенной в основу сетевой модели данных. Рассмотрим отношение между следующими объектами: Студенческий коллектив, Студенческая группа, Комната в общежитии и Студент. Взаимосвязь между этими объектами не является иерархической, так как порожденный элемент Студент имеет два исходных - Студенческая группа и Комната в общежитии. Такие отношения, когда порожденный элемент имеет более одного исходного, описываются в виде сетевой структуры. В такой структуре любой элемент может быть связан с любым другим элементом.
Как и в случае иерархической модели, сетевую структуру можно описать в терминах исходных и порождаемых узлов, а также представить ее таким образом, чтобы порожденные узлы располагались ниже исходных. При рассмотрении некоторых сетевых структур можно говорить об уровнях. Так, рассмотренная выше сетевая структура имеет три уровня.
Рассмотрим, как в сетевой модели будут представлены взаимосвязи между объектами. В нашем примере присутствуют два вида взаимосвязей: 1:M (Учебная группа - Студент) и M:1 (Студент - Комната в общежитии). Сетевые структуры, которые имеют такие связи между исходными и порожденными узлами, порожденными и исходными узлами, относят к простым сетевым структурам. Сложной сетевой структурой называют такую структуру, в которой присутствует хотя бы одна связь типа N:M. Примером такой связи является отношение Студент - Преподаватель. Такое разделение сетевых структур обусловлено технологическими сложностями реализации взаимосвязи N:M. Причем некоторые СУБД не обрабатывают сложных сетевых структур (СЕТОР, DNS, DBMS).
База данных с сетевой структурой состоит из нескольких областей. Каждая область состоит из записей, которые состоят из полей. Объединение записей в логическую структуру возможно не только по областям, но и с помощью наборов данных. По существу набор данных - это поименованное двухуровневое дерево, которое является основой для построения многоуровневых деревьев. Сама база данных состоит из некоторой совокупности наборов данных.
Набор данных - это экземпляр поименованной совокупности записей. Каждый тип набора представляет собой отношение между двумя или несколькими типами записей. Для каждого набора данных один тип записи может быть объявлен владельцем, а один или несколько типов других записей - членами набора. Набор данных, например, можно использовать для объединения записей о студентах одной группы. Тогда тип набора можно определить как состав группы с типом записи владельца. Например, Учебная группа с типом записей членов Студент: Учебная группа (запись-владельца) - Студент (совокупность записей о сту дентах в данной группе).
Набор данных имеет следующие свойства:
Набор данных есть поименованная совокупность связанных записей.В каждом экземпляре набора данных имеется только один экземпляр записи владельца.Экземпляр набора может содержать 0,1 или несколько записей-членов.Набор данных считается пустым, если ни один экземпляр записи-члена не связан с соответствующим экземпляром записи владельца.Экземпляр набора данных связан с записью владельца.Тип набора предполагает логическую взаимосвязь 1:M между владельцем и членом набора.Каждому типу набора данных присваивается имя, которое позволяет одной и той же паре типов объектов участвовать в нескольких взаимосвязях.
Необходимо различать тип и экземпляр набора. Предварительно поясним различие между понятиями "тип" и "экземпляр" записи. Например, Студент является типом записи, а строка, содержащая информацию о конкретном студенте, является экземпляром типа записи Студент. Аналогичное различие существует между типом и экземпляром набора данных. Например, тип набора Состав группы, а его экземпляр содержит один экземпляр типа записи владельца Учебная группа и N экземпляров типа записи-члена Студент. Определенный экземпляр типа записи-члена не может одновременно принадлежать более чем одному экземпляру типа записи-владельца. Уникальность владельца типа набора является обязательным элементом сетевой модели данных. С этой точки зрения иерархическая модель является частным случаем сетевой модели данных.
Концепция сетевой модели данных связана с именем Ч. Бахмана, известного специалиста в области обработки данных, который оказал определяющее влияние на создание проекта DBTG CODASYL (1971 год). Сетевая модель данных является моделью объектов-связей, где допускаются только бинарные связи типа "многие-к-одному", что позволяет использовать для представления данных простую модель ориентированных графов. В некоторых определениях сетевой модели допускаются связи типа "многие-ко-многим", но требование бинарности связи остается в силе.
Для сетевой модели не существует общепринятой терминологии. Далее используется сложившая к настоящему времени группа понятий и терминов, которые используются для описания элементов сетевой модели.
Для моделирования представления данных в сетевой модели используются следующие элементы данных:
простое поле (элемент данных, итем) - наименьшая единица структуры данных, имеет уникальное имя, размер и тип: (табельный номер служащего);множественное поле (агрегат данных, периодическая группа) - поименованная совокупность простых полей или агрегатов; (простой агрегат: Дата = (день, месяц, год)), (составной агрегат: Организация = (наименование, адрес = (почтовый_индекс, город, улица, дома_номер))), (повторяющаяся группа: зарплата (12) = (ФИО, оклад));запись (группа данных) - поименованный агрегат, который не входит в состав никакого другого агрегата и представляет сущность ПО БД (тип записи);групповое отношение (связь, набор) - иерархическое отношение между различными записями (графическое представление группового отношения в сетевой модели называется диаграммой Бахмана);БД - совокупность записей различного типа, объединенная системой групповых отношений различной направленности.
На рис. 1.9 приведен фрагмент описания схемы БД (описание статьи записи) на примере записи из БД "Кадры", предназначенной для автоматизации работы отдела кадров организации. Для описания записи используется язык описания данных СODASYL. Описание схемы БД в CODASYL состоит из четырех статей:
статья схемы: SCHEMA NAME IS Имя_схемы;статья областей: AREA NAME IS Имя_области (файла);статья записи: RECORD NAME IS Имя_записи - способ выборки;статья выбора: SET NAME IS Имя_набора; способ включения экземпляров записей (устанавливает групповые отношения в БД).

Рис. 1.9. Описание записис в сетевой модели данных
Элементы данных сетевой модели допускают обработку следующими операциями, множество которых составляет язык манипулирования данными:
ЗАПОМНИТЬ - заносит экземпляр записи в БД и включает его в существующее отношение;ПРИСОЕДИНИТЬ - связывает существующие записи в групповое отношение и определяет подчинение записей (родитель-потомок);ПЕРЕКЛЮЧИТЬ - связывает экземпляр подчиненной записи с другим экземпляром записи-родителя;МОДИФИЦИРОВАТЬ - изменяет значение полей в существующих записях БД, перед выполнением этой операции запись должна быть извлечена из БД;НАЙТИ - находит записи из БД согласно критерию поиска;УДАЛИТЬ - удаляет из БД ненужную запись;ОТДЕЛИТЬ - разрывает существующую связь между записями в групповом отношении;ПОЛУЧИТЬ - извлекает записи из БД.
В модели CODASYL существует набор дополнительных операций по обслуживанию БД, который здесь не рассматривается.
Очень часто к недостаткам сетевого подхода в БД относят как сложность самой модели данных, так и сложность освоения средств манипулирования данными в ней. Практически, при анализе ПО БД и программировании особенно тщательно приходится отлеживать цепочки связанных групповыми отношениями данных при операциях вставки, обновления и удаления. Однако действительный источник сложности сетевой модели данных состоит в диапазоне предоставляемых моделью конструкций для представления информации и набора операции для манипулирования этими конструкциями.
Системы управления базами данных
В ситуации применения концепции базы данных для создания ИС естественным образом возникает вопрос - а кто или что должно все это поддерживать? Таким образом, встает вопрос о Системе управления базой данных (СУБД). СУБД являются сложными программными системами, работающими на различных операционных платформах. Именно СУБД должна предоставить средства определения и манипулирования данными, сделав данные независимыми от прикладных программ, их использующих. В последнее время набирает обороты концепция машин баз данных, которая предполагает аппаратную реализацию некоторых процедур обработки данных.
Однако после признания концепции БД прошло почти четыре года, прежде чем в 1966 году была создана первая СУБД. На рис. 1.5 представлены основные функции СУБД.

Рис. 1.5. Основные функции СУБД
Определение 4. Системой управления базами данных (Data-base Management System) называется совокупность программных средств, необходимых для использования базы данных и предоставляющих разработчикам и пользователям множество различных представлений данных.
Бизнес-модель процессов (иерархия функций системы)
Бизнес-модель процессов предназначена для описания процессов и функций системы в предметной области базы данных. Бизнес-модель чаще всего документируется в соответствии с методологией (нотацией) IDEF0 и представляется в виде совокупности иерархически упорядоченных и взаимосвязанных диаграмм (IDEF0-диаграмм). Каждая диаграмма является единицей описания системы и расположена на отдельном листе. IDEF0-диаграммы включают в себя следующие диаграммы:
контекстная диаграмма;диаграмма декомпозиции;диаграмма дерева узлов;диаграмма "только для экспозиции".
Контекстная диаграмма является вершиной иерархической структуры диаграмм и представляет самое общее описание системы и ее взаимодействия с внешней средой.
Дальнейшее описание системы строится на основе последовательного разбиения функциональности системы на более детальные фрагменты. Диаграммы, которые описывают каждый из функциональных фрагментов системы, называются диаграммами декомпозиции.
Диаграмма дерева узлов показывает иерархическую структуру функций, не отображая взаимосвязи между ними.
Диаграммы "только для экспозиции" представляют, по сути, копии стандартных диаграмм, но не включаются в анализ синтаксиса модели. Они предназначены для демонстрации иных точек зрения на работы, для отображения деталей, которые не поддерживаются явно синтаксисом модели.
Основными элементами IDEF0-диаграмм являются работы, входные и выходные параметры, управление, механизмы и вызов.
Работы (Activity) обозначают процессы, функции или задачи, которые реализуются в течение определенного времени и имеют распознаваемые результаты. Работы изображаются в виде прямоугольников и именуются отглагольными существительными. Все диаграммы декомпозиции содержат родственные работы, имеющие общую родительскую работу.
Взаимодействие работ между собой и с внешними миром показано стрелками. Стрелки (Arrow) именуются существительными и могут обозначать на диаграмме вход, выход, управление, механизм и вызов.
Вход (Input) - это материалы или информация, которые используются или преобразуются работой для получения результата (выхода).
Стрелка входа рисуется как стрелка, входящая в левую грань работы.
Управление (Control) - правила, стратегии, процедуры или стандарты, которыми руководствуется работа. Каждая работа должна иметь хотя бы одну стрелку управления, которая рисуется как стрелка, входящая в верхнюю грань работы. Управление влияет на работу, но не преобразуется работой.
Выход (Output) - это материалы или информация, которые производятся работой. Каждая работа должна иметь хотя бы одну стрелку выхода, которая рисуется как стрелка, выходящая из правой грани работы.
Механизм - это ресурсы, которые выполняют работу (персонал, станки, устройства). Стрелка механизма рисуется как стрелка, входящая в нижнюю грань работы. Механизмы могут не изображаться.
Вызов (Call) - это специальная стрелка, указывающая на другую модель работы. Стрелка вызова рисуется как стрелка, исходящая из нижней грани работы. Стрелка вызова указывает, что некоторая работа выполняется за пределами моделируемой системы.
На рис. 2.9 - 2.11 приведены примеры контекстной диаграммы, диаграммы декомпозиции и диаграммы дерева узлов процесса изготовления изделия.
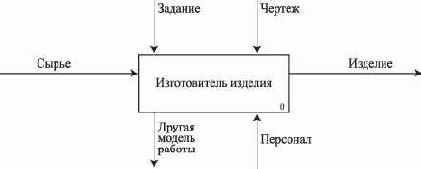
Рис. 2.9. Контекстная диаграмма процесса изготовления изделия
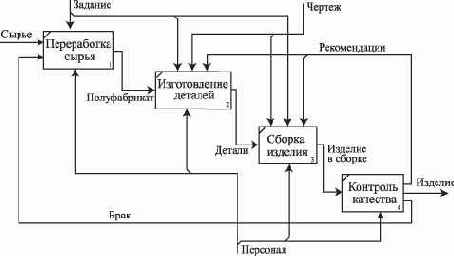
Рис. 2.10. Диаграмма декомпозиции процесса изготовления изделия
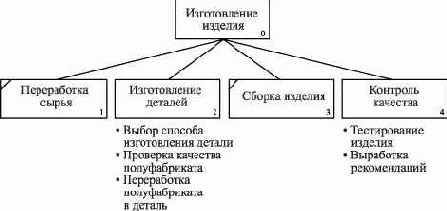
Рис. 2.11. Диаграмма дерева узлов процесса изготовления изделия
На диаграмме дерева узлов последний уровень декомпозиции показан в виде списка.
Стрелка входа рисуется как стрелка, входящая в левую грань работы.
Управление (Control) - правила, стратегии, процедуры или стандарты, которыми руководствуется работа. Каждая работа должна иметь хотя бы одну стрелку управления, которая рисуется как стрелка, входящая в верхнюю грань работы. Управление влияет на работу, но не преобразуется работой.
Выход (Output) - это материалы или информация, которые производятся работой. Каждая работа должна иметь хотя бы одну стрелку выхода, которая рисуется как стрелка, выходящая из правой грани работы.
Механизм - это ресурсы, которые выполняют работу (персонал, станки, устройства). Стрелка механизма рисуется как стрелка, входящая в нижнюю грань работы. Механизмы могут не изображаться.
Вызов (Call) - это специальная стрелка, указывающая на другую модель работы. Стрелка вызова рисуется как стрелка, исходящая из нижней грани работы. Стрелка вызова указывает, что некоторая работа выполняется за пределами моделируемой системы.
На рис. 2.9 - 2.11 приведены примеры контекстной диаграммы, диаграммы декомпозиции и диаграммы дерева узлов процесса изготовления изделия.
Рис. 2.9. Контекстная диаграмма процесса изготовления изделия
Рис. 2.10. Диаграмма декомпозиции процесса изготовления изделия
Рис. 2.11. Диаграмма дерева узлов процесса изготовления изделия
На диаграмме дерева узлов последний уровень декомпозиции показан в виде списка.
Диаграммы "сущность-связь"
Типичной формой документирования информационной модели предметной области являются диаграммы "сущность-связь" (ER-диаграммы). ER-диаграмма позволяет графически представить все элементы информационной модели согласно простым, интуитивно понятным, но строго определенным правилам - нотациям. Далее мы будем пользоваться условными обозначениями, принятыми в методологии информационного проектирования.
Построение ER-диаграмм, как правило, ведется с использованием CASE-средств. Выбор CASE-средств и способы работы с ними в настоящем курсе не обсуждаются.
Документирование доменов
Домены назначаются аналитиками и фиксируются в специальном документе - словаре данных (Data Dictionary). На стадиях разработки логической и физической моделей реляционной базы данных домены уточняются в сущностях на ER-диаграмме.
Проектировщик базы данных должен тщательным образом изучить домены каждого атрибута с точки зрения их реализуемости в СУБД, с участием аналитиков внести в них изменения, если условие реализуемости не выполняется. При этом проектировщик руководствуется следующим:
для реализации реляционной базы данных требуется использовать реляционную СУБД, например Oracle;в большинстве реляционных СУБД в качестве языка манипулирования и описания данных используется диалект SQL, поддерживающий определенные стандарты, например ANSI SQL-92.Пример. Изначально домен атрибута Photo (Фотография) сущности Person (Персона) был определен как Image (Рисунок). Проектировщик базы данных должен изменить значение домена на LONG RAW (СУБД Oracle) или BLOB (двоичный большой объект) (SQL-92).
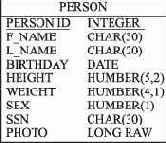
Рис. 2.5. Визуализация определения доменов атрибутов на ER-диаграмме при создании физической модели реляционной базы данных
Документирование отношений (связей)
Отношение (связь) сущностей на ER-диаграмме изображается линией, соединяющей эти сущности.
Степень связи изображается с помощью символа "птичья лапка"1, указывающего на то, что в связи участвует много (N) экземпляров сущности, и одинарной горизонтальной чертой, указывающей на то, что в связи участвует один экземпляр сущности.
Необязательный класс принадлежности сущности к связи изображается с помощью кружочка на линии отношения рядом с сущностью, обязательный класс принадлежности - с помощью вертикальной черты на линии отношения рядом с сущностью.
Отношение читается вдоль линии либо слева направо, либо справа налево. На рис. 2.6 представлено следующее отношение: каждая специальность по образованию должна быть зарегистрирована за определенным физическим лицом (персоной), физическое лицо может иметь одну или более специальностей по образованию.
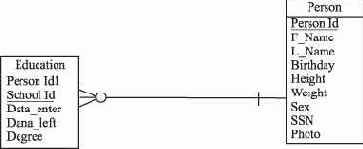
Рис. 2.6. Представление отношения между двумя сущностями на ER-диаграмме
Как правило, отношения на ER-диаграммах именуются с обеих сторон.
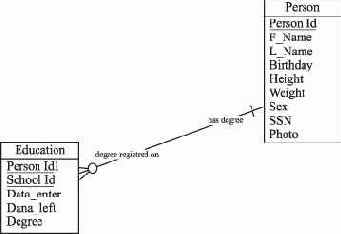
Рис. 2.7. Связанные сущности с названием сторон
Документирование супертипов и подтипов
Супертипы и подтипы, так же как и сущности, обозначаются на ER-диаграмме с помощью прямоугольников. Отношения между ними изображаются с помощью "вилки", имеющей в точке ветвления полукруг.
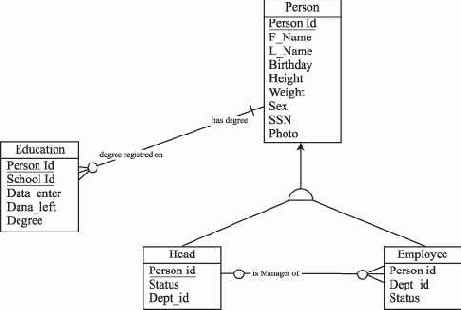
Рис. 2.8. Изображение супертипа Person с двумя подтипами Head и Employee
Супертип Person (Персона) содержит общие для своих подтипов Head (Руководитель) и Employee (Служащий) атрибуты. Подтипы содержат только атрибуты, характерные для выделенных категорий. Предложенная конструкция реализует отношение подчиненности в иерархии организации согласно ее штатному расписанию.
Изучив и проверив качество информационной модели данных предметной области, представленной в виде набора ER-диаграмм, проектировщик базы данных может приступать к созданию логической модели базы данных.
Документирование сущностей и атрибутов
Сущность на ER-диаграмме представляется прямоугольником с именем в верхней части. Будем использовать английские слова для именования элементов модели.

Рис. 2.3. Представление сущности Person (персонал) на ER-диаграмме

Рис. 2.4. Представление сущности Person с атрибутами и уникальным идентификатором сущности
В прямоугольнике перечисляются атрибуты сущности, при этом атрибуты, составляющие уникальный идентификатор сущности, подчеркиваются.
Информационная модель предметной области базы данных
Одним из ключевых моментов создания ИС с целью автоматизации информационных процессов организации является всестороннее изучение объектов автоматизации, их свойств, взаимоотношений между этими объектами и представление полученной информации в виде информационной модели данных.
Информационная модель данных предназначена для представления семантики предметной области в терминах субъективных средств описания - сущностей, атрибутов, идентификаторов сущностей, супертипов, подтипов и т.д.
Информационная модель предметной области базы данных содержит следующие основные конструкции:
диаграммы "сущность-связь" (Entity - Relationship Diagrams);определения сущностей;уникальные идентификаторы сущностей;определения атрибутов сущностей;отношения между сущностями;супертипы и подтипы.Внимание! Элементы информационной модели данных предметной области являются входными данными для решения задачи проектирования базы данных - создания логической модели данных.
Контроль качества результатов анализа предметной области
Предположим, что проектировщик баз данных получил от аналитиков набор материалов с результатами анализа предметной области базы данных. Задача проектировщика - произвести контроль качества предоставленных результатов анализа в целях обеспечения их полноты и достоверности.
Первое, что необходимо сделать, - составить перечень полученных документов и проверить, все ли необходимые документы присутствуют. Проектировщику должны быть представлены: (а) информационная модель предметной области базы данных; (б) совокупность частных моделей, которые относятся к функциональной модели предметной области базы данных; (в) общесистемные требования и решения. В то же время надо помнить, что не все конструкции могут оказаться нужными для решения задач проектирования. Так, например, диаграмма потоков данных непосредственно влияет на принятие решения о числе баз данных, подлежащих реализации в рамках системы. И если уже решено, что база данных будет одна, то принимать во внимание эту диаграмму не нужно. Также часто обходятся без диаграммы жизненных циклов сущностей и диаграммы состояний.
Далее проектировщик должен классифицировать представленные модели по типам и для каждой модели проверить выполнение присущих ей правил.
Существуют формальные и неформальные процедуры проверки результатов моделирования предметной области.
Формальные процедуры основываются на формализации общих знаний о моделях предметной области, в частности на: формальных механизмах, посредством которых представляются данные и процессы системы; формах документирования моделей - диаграммах; методологии графического представления диаграмм (нотациях). В таблице 2.1 приведен перечень моделей, используемых для моделирования данных на различных стадиях жизненного цикла создания ИС, типичные формы документирования моделей - диаграммы - и наиболее популярные методологии (нотации).
| Информационная модель предметной области | |||
| Анализ предметной области | Модели данных | Диаграммы "сущность-связь" (ERD) | CHEF, Martin, Bachman, IDEFXIX, Shlaer & Mellor, Merise, IEM |
| Диаграммы модели данных (DMD) | Martin, Bachman | ||
| Диаграммы структур данных (DSD) | Jackson | ||
| Диаграммы логических структур данных (LDS) | SSADM | ||
| Диаграммы UML | OOA&D | ||
| Функциональные модели предметной области | |||
| Модели процессов | Диаграммы модели бизнес-процессов (контекстная диаграмма, диаграмма декомпозиции, диаграмма дерева узлов | IDEF0, IDEF3 | |
| Диаграммы потоков данных | Yuordan/DeMarco, Gane & Sarson, SSADM | ||
| Графы преобразований | Ward & Mellor, Gane & Sarson, Hatley | ||
| Диаграммы UML | OOA&D | ||
| Модели состояний | Диаграммы состояний (STD) | Ward & Mellor, Hatley | |
| Диаграммы жизненного цикла (ELH) | SSADM | ||
| Диаграммы UML | OOA&D | ||
| Проектирование | Модели процессов проектирования | Структурные схемы (STC) | Youtdan/Constantine Page-Jones |
| Диаграммы UML | OOA&D | ||
| Реализация | Диаграммы UML | OOA&D | |
Как видно из таблицы, не существует единой модели, в рамках которой можно представить весь жизненный цикл системы. Так, стадия анализа предметной области системы представляется с помощью трех типов моделей:
модели данных, которые описывают внутренние, логические взаимоотношения между данными в системе;модели процессов, которые описывают процессы обработки или преобразования данных в системе;модели состояний, которые описывают поведение или отклики системы на события.
Несмотря на то, что каждая из диаграмм может быть представлена с помощью широкого спектра нотаций, все они в рамках определенной диаграммы имеют общие основные черты. Ниже приведены правила, которыми должен руководствоваться проектировщик в ходе формальной проверки правильности представленных моделей.
На диаграммах "сущность-связь" должны быть представлены сущности, связи, степени связи, классы принадлежности сущности, неопределенные связи, супертипы/подтипы сущности. При этом каждая сущность и отношение должны быть поименованы и занесены в словарь данных; каждая сущность может появиться на диаграмме только один раз; каждая сущность должна вступать в отношение (отсутствие "висящих" сущностей), и каждое отношение должно иметь сущности (отсутствие "висящих" отношений). Поэтому проектировщик базы данных должен проконтролировать, чтобы связь между сущностями осуществлялась через точно указанные атрибуты, которые, вероятнее всего, будут определять уникальный ключ связи.
Проектировщик базы данных должен проконтролировать, чтобы в информационной модели предметной области для каждого атрибута сущностей был определен домен. Следует понимать, что определение домена, даваемое аналитиками, носит самый общий характер (число, текст, дата, графика и т.д.), и будет далее уточнено при проектировании. На этом этапе важно, чтобы домен был определен.
На диаграммах модели бизнес-процессов должны быть представлены работы, вход, выход, управление и механизмы. При этом все элементы должны быть поименованы; все работы должны получаться путем функциональной декомпозиции некоторой более крупной работы; для каждой работы должно быть задано управление.
На диаграммах потока данных должны быть представлены внешние сущности (источники и потребители данных), процессы обработки данных, конкурирующие процессы, хранилища данных, потоки данных, указатели ветвления процессов. При этом все процессы должны быть пронумерованы: исходный (начальный) процесс должен иметь номер 0; процессы более низких уровней - 1.1, 1.2, и т.д.; 1.1.1, 1.1.2, и т.д.
На диаграммах жизненного цикла сущностей и диаграммах состояний должны быть представлены состояния, переходы и внешние переходы. При этом на диаграммах должно присутствовать начальное состояние, из которого получаются все остальные состояния. В конечное состояние можно попасть из любого состояния. Запрещается одновременно переход в два состояния; каждый переход имеет условие и действие, которые указываются рядом с переходом.
Таким образом, формальные процедуры проверки нацелены на проверку таких аспектов анализа, как: наличие у каждой сущности уникального идентификатора; наличие функции, создающей экземпляры сущности; наличие хотя бы одной функции, которая ссылается на сущность, и т.п. В основе формальной проверки лежат такие прагматичные соображения, как: зачем создавать сущность, если она никогда не используется или если к ней никогда не будет произведен доступ; зачем создавать сущность, которую нельзя однозначно идентифицировать и т.п.
Следует иметь в виду, что большинство современных CASE-средств, используемых при анализе предметной области и проектировании баз данных, содержат ряд возможностей по автоматизации описанных формальных процедур.
Формальные процедуры проверки качества моделей позволяют проектировщику базы данных убедиться в их "формальной" достоверности, но не позволяют оценить, насколько они адекватно отражают реальную ситуацию внешнего мира в рамках предметной области. Поэтому часто требуется прибегать к неформальным процедурам проверки результатов моделирования предметной области.
Неформальные процедуры заключаются в проведении личных бесед с аналитиками, постановщиками задач, конечными пользователями и руководителями всех автоматизируемых подразделений, проведении семинаров и совещаний всех участников проекта, а также в изучении материалов анализа предметной области.В ходе неформальных процедур могут быть выявлены существенные ошибки (например, потеря сущности предметной области), которые могут привести к пересмотру некоторых результатов проектирования и реализации баз данных, что в конечном счете может стать причиной срыва запланированных сроков выполнения проекта.1)
По окончании проверки качества моделей предметной области составляется список замечаний.
Все вопросы, возникшие в ходе проведения контроля качества результатов анализа предметной области, разрешаются проектировщиками совместно с аналитиками и руководителем ИТ-проекта. Результаты проверки доводятся до сведения руководителя проекта.
Литература: [1], [8], [9], [17], [22], [24], [25], [26], [27], [28], [30], [32], [33], [35], [44], [45], [46]
Как видно из таблицы, не существует единой модели, в рамках которой можно представить весь жизненный цикл системы. Так, стадия анализа предметной области системы представляется с помощью трех типов моделей:
модели данных, которые описывают внутренние, логические взаимоотношения между данными в системе;модели процессов, которые описывают процессы обработки или преобразования данных в системе;модели состояний, которые описывают поведение или отклики системы на события.
Несмотря на то, что каждая из диаграмм может быть представлена с помощью широкого спектра нотаций, все они в рамках определенной диаграммы имеют общие основные черты. Ниже приведены правила, которыми должен руководствоваться проектировщик в ходе формальной проверки правильности представленных моделей.
На диаграммах "сущность-связь" должны быть представлены сущности, связи, степени связи, классы принадлежности сущности, неопределенные связи, супертипы/подтипы сущности. При этом каждая сущность и отношение должны быть поименованы и занесены в словарь данных; каждая сущность может появиться на диаграмме только один раз; каждая сущность должна вступать в отношение (отсутствие "висящих" сущностей), и каждое отношение должно иметь сущности (отсутствие "висящих" отношений). Поэтому проектировщик базы данных должен проконтролировать, чтобы связь между сущностями осуществлялась через точно указанные атрибуты, которые, вероятнее всего, будут определять уникальный ключ связи.
Проектировщик базы данных должен проконтролировать, чтобы в информационной модели предметной области для каждого атрибута сущностей был определен домен. Следует понимать, что определение домена, даваемое аналитиками, носит самый общий характер (число, текст, дата, графика и т.д.), и будет далее уточнено при проектировании. На этом этапе важно, чтобы домен был определен.
На диаграммах модели бизнес-процессов должны быть представлены работы, вход, выход, управление и механизмы. При этом все элементы должны быть поименованы; все работы должны получаться путем функциональной декомпозиции некоторой более крупной работы; для каждой работы должно быть задано управление.
На диаграммах потока данных должны быть представлены внешние сущности (источники и потребители данных), процессы обработки данных, конкурирующие процессы, хранилища данных, потоки данных, указатели ветвления процессов. При этом все процессы должны быть пронумерованы: исходный (начальный) процесс должен иметь номер 0; процессы более низких уровней - 1.1, 1.2, и т.д.; 1.1.1, 1.1.2, и т.д.
На диаграммах жизненного цикла сущностей и диаграммах состояний должны быть представлены состояния, переходы и внешние переходы. При этом на диаграммах должно присутствовать начальное состояние, из которого получаются все остальные состояния. В конечное состояние можно попасть из любого состояния. Запрещается одновременно переход в два состояния; каждый переход имеет условие и действие, которые указываются рядом с переходом.
Таким образом, формальные процедуры проверки нацелены на проверку таких аспектов анализа, как: наличие у каждой сущности уникального идентификатора; наличие функции, создающей экземпляры сущности; наличие хотя бы одной функции, которая ссылается на сущность, и т.п. В основе формальной проверки лежат такие прагматичные соображения, как: зачем создавать сущность, если она никогда не используется или если к ней никогда не будет произведен доступ; зачем создавать сущность, которую нельзя однозначно идентифицировать и т.п.
Следует иметь в виду, что большинство современных CASE-средств, используемых при анализе предметной области и проектировании баз данных, содержат ряд возможностей по автоматизации описанных формальных процедур.
Формальные процедуры проверки качества моделей позволяют проектировщику базы данных убедиться в их "формальной" достоверности, но не позволяют оценить, насколько они адекватно отражают реальную ситуацию внешнего мира в рамках предметной области. Поэтому часто требуется прибегать к неформальным процедурам проверки результатов моделирования предметной области.
Неформальные процедуры заключаются в проведении личных бесед с аналитиками, постановщиками задач, конечными пользователями и руководителями всех автоматизируемых подразделений, проведении семинаров и совещаний всех участников проекта, а также в изучении материалов анализа предметной области.
В ходе неформальных процедур могут быть выявлены существенные ошибки (например, потеря сущности предметной области), которые могут привести к пересмотру некоторых результатов проектирования и реализации баз данных, что в конечном счете может стать причиной срыва запланированных сроков выполнения проекта.1)
По окончании проверки качества моделей предметной области составляется список замечаний.
Все вопросы, возникшие в ходе проведения контроля качества результатов анализа предметной области, разрешаются проектировщиками совместно с аналитиками и руководителем ИТ-проекта. Результаты проверки доводятся до сведения руководителя проекта.
Литература: [1], [8], [9], [17], [22], [24], [25], [26], [27], [28], [30], [32], [33], [35], [44], [45], [46]
 |
|
|
Согласно данным исследовательской организации Gartner Group, почти половина проектов реализации ИС с базами данными по тем или иным причинам оказывается неуспешной.
| © 2003-2007 INTUIT.ru. Все права защищены. |
Модель потока данных
Модель потока данных предназначена для описания процессов перемещения данных в предметной области базы данных. Модель потока данных представляется в виде диаграммы потока данных (Data Flow Diagram). Основными элементами диаграммы являются:
источники данных (Data Source);процессы обработки данных (Data Process);хранилища данных (Data store);потоки данных (Data Flow).
Источники данных показывают, кто использует или работает c данными. Процессы обработки данных показывают операции, производимые над данными. Хранилища данных показывают места хранения данных. Потоки данных показывают способ передачи данных между источниками и хранилищами данных. Для представления диаграмм потока данных обычно используются сетевые структуры, допускающие повторение сущностей; циклы не используются. Поток изображается слева направо. На диаграммах помечаются допустимые и недопустимые пути перемещения данных, но не показываются процессы управления потоком.
На рис. 2.12 приведен упрощенный вариант диаграммы потока данных для обработки заказа. Квадраты обозначают источники данных, окружности - процессы обработки данных, две параллельные черты - хранилище данных. Линии со стрелками показывают способ передачи данных из одной области в другую. Процессы можно подвергать функциональной декомпозиции, порождая тем самым иерархию диаграмм потока данных.
Рис. 2.12. Простая диаграмма потока данных для обработки заказа
На этом рисунке сущность Клиент (Client) продублирована: клиент делает заказ и получает его. На диаграмме показано два хранилища данных, два процесса и потоки данных между клиентом, процессами и хранилищами данных.
Диаграмма потока данных позволяет:
представить систему с точки зрения источников и потребителей данных;показать перемещение данных в процессе их обработки;показать внешние механизмы подачи данных;показать метод сбора данных.
Диаграмма потока данных предоставляет проектировщику баз данных информацию:
хранилищах данных, что позволит на последующих стадиях проектирования обоснованно определить число баз данных для информационной системы;принятых схемах преобразования информации в процессе ее обработки, что позволит в ходе проектирования приложений составить спецификацию приложений. Спецификации приложений вместе с диаграммами потоков данных передаются разработчикам приложений.
Модель жизненного цикла сущности
Модель жизненного цикла (ЖЦ) сущности предназначена для описания изменения состояний сущности и переходов между ними.
Модель ЖЦ сущности представляется в виде диаграммы ЖЦ сущности (Entity Lifecycle Diagram), на которой изображаются пути перехода сущности из некоторого начального состояния в конечное состояние и события, инициирующие изменения состояния сущности. Модель ЖЦ сущности может быть также представлена в виде текстового описания.
Для проектировщика баз данных особенно важны диаграммы ЖЦ тех сущностей, которые многократно меняют свое состояние. Обычно такая сущность имеет атрибут Status (Состояние), характеризующий состояние сущности в текущий момент времени; домен этого атрибута является некоторым множеством значений, задаваемым перечислением. Проектировщику баз данных на стадии создания физической модели базы данных потребуется знание диаграмм ЖЦ сущностей для того, чтобы прописать ограничения на реализацию атрибута Status (Состояние) в базе данных.
На рис. 2.13 приведен пример диаграммы жизненного цикла сущности Чек.
Рис. 2.13. Диаграмма жизненного цикла Чек
Набор спецификаций функций системы
Одной из задач проектирования базы данных является отображение функций системы, содержащихся в требованиях и бизнес-правилах, в набор спецификаций модулей приложений базы данных. При этом проектирование модулей осуществляется параллельно и в согласовании с проектированием базы данных. Поэтому важным дополнением к моделям процессов и состояний, необходимым для проектирования базы данных, является информация о функциональности системы.
Аналитики должны предоставить проектировщикам баз данных набор спецификаций функций системы, которые описывают функциональность системы в форме бизнес-категорий - четко сформулированных требований к системе, сгруппированных по направлениям деятельности организации. Иногда предоставляется список зависимостей между функциями и вызывающими их событиями.
Помимо информации об иерархии функций, содержащейся в бизнес-модели процессов области, проектировщику базы данных необходимо иметь текстовое описание каждой из функций системы. При этом оно должно содержать выделенные сущности, применяемые в каждой функции, и используемые атрибуты сущностей, а также однозначно интерпретироваться при прочтении.
Получив набор спецификаций и описание функций системы через атрибуты и сущности, проектировщик базы данных может приступать к разработке спецификаций модулей приложений базы данных.
Бизнес-правила представляют собой конкретные требования и условия для функций, задающие поведение данных. В практике проектирования бизнес-правила используются для поддержки целостности данных в базе данных.
Общесистемные требования и решения
Общесистемные требования и решения о реализуемости базы данных, как правило, формируются менеджером ИТ-проекта на основе анализа данных предметной области. Среди них наиболее важными для проектировщиков базы данных являются следующие требования и решения.
Требования по аппаратно-программной платформе: тип компьютеров (Intel, SUN, HP и т.д.);топология сети и протоколы передачи данных (NetBIOS, TCP/IP и т. д.);тип операционной системы (MS Windows, Unix, OpenVMS и т.д.);архитектура базы данных ("клиент-сервер", параллельная архитектура);СУБД, на которой будет реализована база данных (MS SQLServer, Oracle, DB2 и т.д.);язык программирования или средства разработки приложений (C++, Delphi, MS VB и т.д.);Требования по обеспечению безопасности и разграничению доступа к базе данных;Требования по надежности работы базы данных;Требования по активности работы с данными: требования, позволяющие оценить объем базы данных;требования, позволяющие оценить интенсивность потока транзакций в системе;требования, позволяющие оценить пропускную способность сети;требования по максимально возможному числу активных пользователей базы данных;требования по актуализации данных;требования по производительности системы;требования по гибкости базы данных, т.е. открытость к модификациям структуры и кода.
Большинство перечисленных требований идут транзитом на следующие этапы процесса проектирования. Проектировщику базы данных на стадии планирования проектирования базы данных необходимо убедиться, что эти требования присутствуют в исходной документации, и в случае, если какие-либо требования отсутствуют, запросить их.
Рассмотрим некоторые примеры возможного неверного принятия решения по выбору СУБД. Предположим, что принято решение о разработке некоторой базы данных на СУБД Oracle. Закуплено и установлено оборудование. Однако информация об объеме базы данных и его потенциальном росте на этапе анализа требований к базе данных отсутствовала. База данных спроектирована и создана, готовится план тестирования приложений базы данных. При составлении плана тестирования базы данных выясняется, что в базе данных будет размещено 1000 записей длиной 100 байт, а рост числа записей базы данных оценивается как 10 записей в год! Базой данных будут пользоваться 4 раза в год для получения 5 видов отчетов. На производство всех отчетов за период требуется один день. Таким образом, цикл простоя системы будет много больше, чем время ее активной работы. В этом случае ответ на вопрос "А зачем выбрана промышленная СУБД Oracle?" имеет вполне экономический смысл.
Имеет место и обратная ситуация. Выбрали СУБД SQLBase. А через два года эксплуатации вышли на объем базы данных в 10 млн записей - цифра, характерная для финансовых подсистем крупного предприятия. И база данных "захлебнулась"!
Проектировщики баз данных! Будьте внимательны! Требуйте предоставления полного набора необходимой для принятия проектных решений информации!
Отношения, связи
Сущности не существуют отдельно друг от друга. Между ними имеются реальные отношения (Relationship), и они должны быть отражены в информационной модели предметной области. При выделении отношений акцент делается на фиксацию связей и их характеристик. Отношение (связь) представляет собой соединение (взаимоотношение) между двумя или более сущностями. Каждая связь реализуется через значения атрибутов сущностей. Обычно связь обозначается глаголом. Каждая связь также должна иметь свой уникальный идентификатор связи.
Внимание! В реляционной базе данных отношения реализуются только через ограничение целостности по внешнему ключу. Поэтому проектировщик базы данных должен проконтролировать, чтобы связь между сущностями осуществлялась через точно указанные атрибуты, которые будут определять уникальный ключ связи. Выбор ключей сущностей - одно из важнейших проектных решений, которое предстоит сделать проектировщику при переходе от информационной модели предметной области к логической модели базы данных.
Связи характеризуются степенью связи и классом принадлежности сущности к связи. Степень (мощность) связи - это отношение числа сущностей, участвующих в образовании связи. Например, "один-к-одному", "один-ко-многим", "многие-ко-многим". На уровне информационной модели допускается неопределенная или неразрешенная связь. Класс принадлежности сущности - это характер участия сущности в связи. Различают обязательные и необязательные классы принадлежности сущности к связи. Обязательным является такой класс принадлежности, когда экземпляры сущности участвуют в установлении связи в обязательном порядке. В противном случае сущность принадлежит к необязательному классу принадлежности. Для необязательного класса принадлежности сущности степень связи может быть равна нулю, т.е. экземпляр сущности можно связать с 0, 1 или несколькими экземплярами другой сущности. Для обязательного класса принадлежности степень связи не может равняться нулю.
Отношения, связывающие сущность саму с собой, называются рефлексивными. Типичным примером рефлексивных отношений является определение структуры подчиненности в отношении "Сотрудники". Рефлексивные отношения чаще всего отражают иерархические отношения внутри структуры данных. Они порождают ряд проблем проектирования, о которых речь пойдет позже.
С точки зрения отношений различают слабые (weak) сущности. Слабые сущности - это сущности, которые не могут присутствовать в базе данных, пока не существует связанного с ней экземпляра другой сущности. Примером такой сущности является заказ, который не может существовать без клиента. Слабые сущности имеют обязательный класс принадлежности, и степень связи такой сущности не может равняться нулю. Связь "заказ-клиент" является обязательной.
Выявление слабых сущностей и связанных с ними обязательных отношений необходимо для обеспечения целостности и согласованности данных. Так, например, неизвестному клиенту невозможно приписать заказ.
Подтипы и супертипы
Иногда выделенная сущность несет в себе отношение включения или часть-целое. При этом существует некоторый атрибут, значения которого порождают разбиение множества экземпляров сущности на непересекающиеся подмножества - категории сущности. Категории сущности называются подтипами и выделяют в подчиненную в рамках отношения сущность, которая является категорией исходной сущности.
Иногда из исходной сущности выделяются общие для полученных категорий атрибуты, и таким образом выделяется сущность, которая становится супертипом. За выделенной сущностью-супертипом обычно оставляют наименование исходной сущности, хотя ее семантический смысл меняется.
Супертип с порожденными им подтипами является примером так называемой составной сущности. Составная сущность является логической конструкцией модели для представления набора сущностей и связей между ними как единого целого.
Пример. Сущность Автомобиль можно разбить на следующие подтипы: автомобили с приводом на два колеса, автомобили с приводом на четыре колеса, автомобили с переключаемым приводом.
Для проектировщика базы данных важно знать, что все экземпляры сущности-супертипа относятся только к одному из ее подтипов. Наличие в модели подтипов и супертипов усложняют проектирование и создают определенные трудности в реализации.
Поэтому важно на ранней стадии проектирования установить, является ли наличие супертипов в модели необходимым. Для этого можно предпринять следующие действия:
установить, много ли одинаковых свойств имеют различные подтипы. Следует помнить, что чем меньше подтипы похожи друг на друга, тем больше вероятность введения супертипа, или найти экземпляр сущности, который можно обоснованно включить в более чем один подтип. Поскольку это противоречит определению супертипа, то предлагаемое разбиение недопустимо.
Понятие функциональной модели предметной области базы данных
Вторым ключевым моментом создания ИС с целью автоматизации информационных процессов организации является анализ функционального взаимодействия объектов автоматизации. Результаты такого анализа многогранны. Аналитики представляют их в виде функциональной модели предметной области базы данных. Функциональная модель предметной области является собирательным понятием. Состав функциональной модели существенно зависит от контекста конкретного ИТ-проекта и может быть представлен посредством довольно широкого спектра документов в виде текстовой и графической информации. К рассмотрению таких документов проектировщик баз данных должен подходить с учетом следующих двух положений:
главное назначение ИС является базовым критерием оценки достаточности предоставляемой информации;функциональная модель предназначена для описания процессов обработки данных в рамках выделенной предметной области с различных точек зрения.
Описать процессы обработки информации всесторонне с помощью одной описательной модели сложно. В последнее время предпринимаются некоторые успешные попытки разработать унифицированную модель в рамках объектно-ориентированного анализа и проектирования (OOA&D) с помощью UML-конструкций. В настоящих лекциях мы основываемся только на результатах структурного анализа предметной области как наиболее прагматичном подходе для проектирования классических реляционных баз данных. Использование объектно-ориентированного подхода к проектированию баз данных - это предмет отдельного курса лекций.
Определим функциональную модель предметной области базы данных как совокупность некоторых моделей, предназначенных для описания процессов обработки информации. Будем называть эти модели конструкциями функциональной модели. Ниже приведен перечень основных конструкций функциональной модели, необходимые для выполнения проектирования реляционных баз данных.
Модели процессов: бизнес-модель процессов (иерархия функций системы);модель потока данных.Модели состояний: модель жизненного цикла сущности;набор спецификаций функций системы (требования);описание функций системы через сущности и атрибуты;бизнес-правила, которые реализуют функции.Внимание! Элементы информационной модели предметной области являются входными данными для задачи создания логической модели данных. Элементы функциональной модели предметной области являются входными данными для задачи проектирования приложений базы данных и, частично, для задачи создания физической модели базы данных.
Понятие предметной области
Основным назначением информационных систем является оперативное обеспечение пользователя информацией о внешнем мире путем реализации вопросно-ответного отношения. Вопросно-ответные отношения, получая интерпретацию во внешнем мире (мире вне информационной системы), позволяют выделить для информационной системы определенный его фрагмент - предметную область, - который будет воплощен в автоматизированной информационной системе. Информация о внешнем мире представляется в информационной системе (ИС) в форме данных. Это ограничивает возможности смысловой интерпретации информации и конкретизирует семантику ее представления в ИС. Совокупность этих выделенных для ИС данных, связей между ними и операций над ними образует информационную и функциональную модели предметной области, описывающие ее состояние с определенной точностью.
Важно понимать, что информационная и функциональная модели предметной области создаются на этапе анализа требований к базе данных и не содержат предположений о технологии реализации базы данных. Они строятся независимо от выбираемой модели данных (сетевой, иерархической, реляционной, объектно-ориентированной, многомерной и т.д.), поддерживаемой СУБД, модели вычислений, программно-аппаратной платформы для базы данных. Информационная и функциональная модели предметной области являются входными данными для процесса проектирования базы данных. Поэтому проектировщик должен уметь правильно интерпретировать их в ходе решения своих проектных задач.
Понятие предметной области базы данных является одним из базовых понятий информатики и не имеет точного определения. Его использование в контексте ИС предполагает существование устойчивой во времени соотнесенности между именами, понятиями и определенными реалиями внешнего мира, не зависящей от самой ИС и ее круга пользователей. Таким образом, введение в рассмотрение понятия предметной области базы данных ограничивает и делает обозримым пространство информационного поиска в ИС и позволяет выполнять запросы за конечное время.
Совокупность реалий (объектов) внешнего мира - объектов, о которых можно задавать вопросы, - образует объектное ядро предметной области, которое имеет онтологический статус. Нельзя получить в ИС ответ на вопрос о том, что ей неизвестно. Термин объект является первичным, неопределяемым понятием. Синонимами термина "объект" являются "реалия, сущность, вещь". Однако термин сущность понимается нами несколько уже, как компонент модели предметной области, т.е. как уже выделенный на концептуальном уровне объект для базы данных. Таким образом, выделяемые в предметной области объекты превращаются аналитиками (а не проектировщиками базы данных) в сущности. Сущность предметной области является результатом абстрагирования реального объекта путем выделения и фиксации набора его свойств. Сущность является результатом абстрагирования реального объекта, т.е. в нашем контексте имеет гносеологический статус. Хотя далее в контексте сущность н ередко отождествляется с объектом.
На рис. 2.1 представлен один из подходов к классификации объектов предметной области.
Рис. 2.1. Классификации объектов предметной области
Примерами сущностей (с точки зрения ИС) или объектов (с точки зрения внешнего мира) являются отдельный студент, группа студентов, аудитория, время занятий, слова, числа, символы. Обычно считается, что быть объектом - это значит быть дискретным и различимым. Примеры "не-объектов" - это мир, время, смысл, хотя и такие категории могут сохраняться в базе данных.
С объектами связано две проблемы: идентификация и адекватное описание. Для идентификации используют имя. При этом предполагается, что происходит отказ от его смысла, который присущ естественному языку. Используется только указательная функция имени. Имя - это прямой способ идентификации объекта. К косвенным способам идентификации объекта относят определение объекта через его свойства (характеристики или признаки).
Объекты взаимодействуют между собой через свои свойства, что порождает ситуации.
Ситуации - это взаимосвязи, выражающие взаимоотношения между объектами. Ситуации в предметной области описываются посредством высказываний о предметной области с использованием исчисления высказываний и исчисления предикатов, т.е. формальной, математической логики. Например, высказывание "Программист и менеджер есть служащие компании" описывает отношение включения. Таким образом, вся информация об объектах и сущностях предметной области описывается с помощью утверждений на естественном языке.
Методы математической логики позволяют формализовать эти утверждения и представить их в виде, пригодном для анализа.
Пример. Рассмотрим высказывание: Студент Иванов А.А, родился в 1982 году. Оно выражает следующие свойства объекта "Иванов А.А.":
в явном виде - год рождения;в неявном - принадлежность к студентам.
Первое свойство устанавливает связь между объектами "Иванов А.А." и "Год рождения", а второе - между объектами "Иванов А.А." и "Множество студентов". Формализация этого высказывания представляется как результат присваивания значений переменным, входящим в предикаты:
РОДИЛСЯ (Иванов А.А., 1982)
ЯВЛЯЕТСЯ СТУДЕНТОМ (Иванов А.А.)
Отметим, что в семантике естественных языков ситуация и взаимосвязь считаются почти синонимами. Ситуация содержит высказывание об объектах предметной области, которому можно приписать некоторую оценку истинности и представить в виде предиката после введения переменных. Таким образом, совокупность высказываний о предметной области можно трактовать как определение информационного пространства для базы данных.
На рис. 2.2 представлен один из подходов к классификации ситуаций в рамках предметной области.
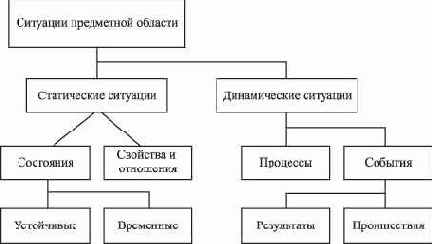
Рис. 2.2. Классификация ситуаций предметной области
Различают статические и динамические ситуации. Примерами статических ситуаций являются такие ситуации, как иметь цвет, иметь возраст. Примерами динамических ситуаций являются такие ситуации, как создать утюг, выпечь хлеб.
Обратите внимание на то, что ситуация также может представлять собой объект (см. рис. 2.1) и обладать свойствами. С другой стороны, приведенная классификация рассматривает свойства как специальный случай ситуаций. Подобная коллизия порождает неоднозначность при моделировании предметной области базы данных. Поставим вопрос - что есть цвет автомобиля? Объект, свойство, ситуация? К обсуждению этого вопроса мы вернемся специально в следующей лекции.
Приведенная классификация вводит в предметную область два важных аспекта - пространство и время, причем время и как момент, и как интервал. Предметная область существует в пространстве и во времени, т.е. ей присущи, как и реальному миру, временные и пространственные отношения и связи. Следует отличать реальное время внешнего мира и его отражение в базе данных и в источниках информации. В базе данных взаимосвязи, зависящие от времени, фиксируются только после их регистрации в базе данных. Таким образом, предметная область в каждый конкретный момент времени представляет собой выделенную совокупность определенных объектов и ситуаций, называемую состоянием предметной области (или снимком).
Введем определение предметной области.
Определение. Предметная область - это целенаправленная первичная трансформация картины внешнего мира в некоторую умозрительную картину, определенная часть которой фиксируется в ИС в качестве алгоритмической модели фрагмента действительности.
Понятие предметной области было введено в начале 80-х годов прошлого века, когда учеными в области ИС была осознана необходимость использовать семантические модели для представления информации в компьютерных системах. Так же как требования к компьютерной системе формируются средствами естественного языка, так и информация в компьютерных системах представляется средствами особого языка с определенной семантикой. Такой подход впервые был представлен П. Ченом в 1976 году.
Сущности, атрибуты и идентификаторы (ключи) сущности, домены атрибутов
Предметом информационной модели является абстрагирование объектов или явлений реального мира в рамках предметной области, в результате которого выявляются сущности (entity) предметной области. Как правило, они обозначаются именем существительным естественного языка.
Сущность описывается с помощью данных, именуемых свойствами или атрибутами (attributes) сущности. Как правило, атрибуты являются определениями в высказывании о сущности и обозначаются именами существительными естественного языка. Сущности вступают в связи друг с другом через свои атрибуты. Каждая группа атрибутов, описывающих одно реальное проявление сущности, представляет собой экземпляр (instance) сущности. Иными словами, экземпляры сущности - это реализации сущности, отличающиеся друг от друга и допускающие однозначную идентификацию.
Внимание! При представлении сущности в базе данных хранятся только ее атрибуты.
Одним из основных компьютерных способов распознавания сущностей в базе данных является присвоение сущностям идентификаторов (Entity identifier). Часто идентификатор сущности называют ключом. Задача выбора идентификатора сущности является семантически субъективной задачей. Поскольку сущность определяется набором своих атрибутов, то для каждой сущности целесообразно выделить такое подмножество атрибутов, которое однозначно идентифицирует данную сущность.
Некоторые сущности имеют естественные идентификаторы. Например, естественным идентификатором счета-фактуры является его номер. Идентификаторы сущности могут быть составными - составленными из нескольких атрибутов и атомарными - составленными из одного атрибута сущности.
Идентификация сущностей проводится аналитиками. Однако чаще всего их решение не является окончательным! Задача проектировщика баз данных - обеспечить при сохранении экземпляров сущности в базе данных наличие у каждого ее нового экземпляра уникального идентификатора. Уникальный идентификатор сущности - это атрибут сущности, позволяющий отличать одну сущность от другой. Если сущность имеет несколько уникальных идентификаторов, так называемых возможных ключей, то проектировщик должен выбрать первичный ключ сущности.
Различают однозначные и многозначные атрибуты. Однозначными являются атрибуты, которые в пределах конкретного экземпляра сущности имеют только одно значение. В противном случае они считаются многозначными.
Важным моментом изучения информационной модели проектировщиком является выделение многозначных атрибутов сущности. Это связано с тем, что реляционная модель базы данных не поддерживает многозначных атрибутов, и они должны быть разрешены на последующих стадиях проектирования.
Каждый атрибут сущности имеет домен (domain). Домен - это выражение, определяющее значения, разрешенные для данного атрибута. Иными словами, домен - это область значений атрибута. Проектировщик базы данных должен проконтролировать, чтобы в информационной модели предметной области для каждого атрибута сущностей был определен домен.
На уровне информационного моделирования данных назначение домена атрибуту носит общий характер. Например, атрибут текстовый, числовой, бинарный, дата или "не определен". В последнем случае аналитик должен дать описание домена. На последующих стадиях тип домена конкретизируется, смысл понятия домена в логической и физической моделях базы данных уже, чем его может понимать аналитик. Это связано с тем, что в рамках физической модели базы данных домен реализуется посредством механизма ограничения домена, СУБД не понимает неопределенных доменов.
Бизнес-модель этапа проектирования
Решая профессиональную задачу создания физической модели данных - учет влияния транзакций, - проектировщик базы данных стремиться создать такую физическую модель данных, которая, по его мнению, давала бы наибольшую производительность обработки запросов базы данных. На практике, особенно при создании и разработке новых баз данных, такая задача вряд ли может быть решена полностью. Ясно, что для ее решения необходимо иметь список всех запросов к базе данных, их частоте и объеме выборок по каждому, что в принципе невозможно. Поэтому проектировщики базы данных на основе анализа исходной документации и опросов потенциальных пользователей пытаются систематизировать транзакции к базе данных, оценить кардинальность таблиц в целом и отдельных колонок в частности. На основе таких оценок проектировщик базы данных пытается определить критические транзакции и настроить структуры таблиц, задействованных в таких транзакциях, на достижение, с его точки зрения, максимальной производительности. При этом он выдвигает гипотезы о применимости того или иного способа повышения производительности обработки запросов и умозрительно проверяет их. Далее он принимает решение о применении наиболее подходящего, с его точки зрения, способа увеличения производительности запросов.
Следует понимать, что задача обеспечения высокой производительности базы данных - это задача, которую постоянно решает администратор базы данных в процессе ее эксплуатации. На этом этапе проектирования базы данных проектировщик, по мере возможности, готовит успешное решение этой задачи. Эта этап является очень ответственным в физическом проектировании базы данных, поэтому следует соблюдать при решении этой задачи разумный прагматизм и документировать свои решения. Должно действовать эмпирическое правило: если проектировщик базы данных не имеет достаточно данных для надежного решения задачи повышения производительности базы данных, то решение этой задачи должно быть передано администратору базы данных.
На этом этапе проектирования физической модели реляционной базы данных проектировщик базы данных:
исходя из требований к характеру обработки данных, определяет тип приложения базы данных; по имеющимся требованиям и описаниям выполняет систематизацию и описание по возможности всех транзакций к базе данных;отталкиваясь от исходной документации, определяет возможные размеры таблиц, а если это невозможно, делает предположения об их возможном размере;исходя из фактических размеров таблиц и требований к производительности выполнения транзакций, определяет критические транзакции;для каждой критической транзакции необходимо оценить кардинальность каждой колонки, задействованной в транзакции и, по возможности, кардинальность выборки;далее, рассматривая в первую очередь критические транзакции и таблицы, которые в них участвуют, проектировщик базы данных принимает субъективные решения по изменению структуры таблиц внутренней схемы базы данных, исходя из тех механизмов, которые ему предоставляет конкретная СУБД;по завершении изменения структур таблиц проектировщик базы данных документирует эти изменения, приводя обоснование своих решений для администратора базы данных.
В результате проектировщик базы данных создает физическую модель базы данных, которая учитывает характер обработки данных в базе данных, выраженный через учет влияния транзакций.
Перейдем теперь к построению бизнес-модели этапа проектирования физической модели реляционной базы данных: учет влияния транзакций. Из сказанного в предыдущих разделах настоящей лекции понятен следующий алгоритм действий:
Определение основного типа приложения базы данных Документирование и описание транзакций Определение критических транзакций Для каждой критической транзакции: Определение таблиц транзакции Определение способа повышения производительности Денормализация таблицы? Разбиение таблицы? Секционирование таблицы? Кластеризация таблицы? Построение дополнительных индексов? Изменение структуры внутренней схемы базы данных Документирование изменений Для каждой таблицы базы данных Выбор индексов Определение транзакций таблицы Определение кардинальности таблиц Определение кардинальности колонок Определение индексов Изменение внутренней схемы
На рис. 3.9 ниже представлена модель бизнес- процессов стадии проектирования физической модели базы данных с учетом влияния транзакций. На рис. рис. 3.10 - декомпозиция работы по индексированию базовой таблицы.
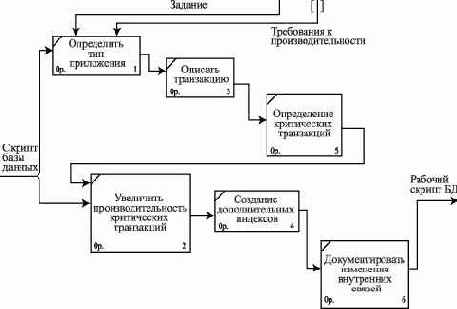
Рис. 3.9. Декомпозиция этапа проектирования - создание первой итерации физической модели базы данных: внутренняя схема
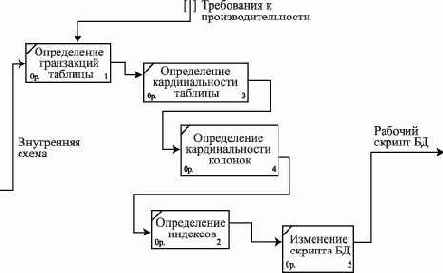
Рис. 3.10. Декомпозиция работы по индексированию базовой таблицы
Следует еще раз отметить субъективный характер принятия решений проектировщиком базы данных из-за отсутствия во многих случаях точных сведений о характере выполнения транзакций в системе. Большинство решений принимается на основе эвристических правил и личного опыта проектировщика. Метод работы проектировщика базы данных сводится к изменению структуры объектов базы данных на основе перебора возможных способов повышения производительности, их сопоставления и обоснованного выбора подходящего решения.
На этом мы заканчиваем рассмотрение задач проектировщика базы данных по созданию физической модели реляционной базы данных с учетом влияния транзакций. Главная цель этого этапа - видоизменить последовательность команд SQL для создания объектов хранения данных с учетом влияния транзакций на производительность базы данных.
Бизнес-модель этапа проектирования - создание физической модели реляционной базы данных
В данном разделе рассмотрим организационную сторону решения профессиональной задачи проектировщика баз данных - задачу создания физической модели реляционной базы данных. Основная цель решения этой задачи: преобразовать логическую модель реляционной базы данных в последовательность команд SQL для создания объектов реляционной базы данных. Таким образом, проектировщик базы данных отображает отношения логической модели реляционной базы данных (сущности предметной области, представленные в нормализованной форме на ER-диаграммах) в таблицы и индексы реляционной базы данных.
Эта задача включает выполнение ряда обязательных последовательных процедур.
Создание базовых таблиц. Они представляют основные блоки хранения данных и выводятся из сущностей логической модели данных. При создании каждой таблицы проектировщик должен рассмотреть и учесть ряд факторов: определить список колонок в таблице. Колонки выводятся из атрибутов сущности логической модели данных;определить типы данных для каждой колонки. Типы данных колонок либо заданы спецификацией домена атрибута логической модели, либо определяются проектировщиком самостоятельно;определить имя таблицы. Оно может быть выведено из имени сущности логической модели базы данных или задано проектировщиком самостоятельно. Желательно в этот момент определить собственника таблицы - пользователя, который будет иметь все права доступа на таблицу, а также потенциальных пользователей таблицы;определить ряд параметров, связанных с характером хранения таблицы в физической базе данных;определить ограничения на значения колонок, исходя из ряда бизнес-правил.Создание связывающих таблиц, необходимых для разрешения отношения "многие-ко-многим", если они имеют место в логической модели базы данных. В рамках ER-диаграмм это отношение может быть уже разрешено. Тогда речь пойдет только о его реализации в командах SQL.Принять решение о способе поддержки ссылочной целостности в базе данных. Если будет решено поддерживать ссылочную целостность на уровне команд SQL, то специфицировать ограничения ссылочной целостности.
В данном разделе рассмотрим организационную сторону решения профессиональной задачи проектировщика баз данных - задачу создания физической модели реляционной базы данных. Основная цель решения этой задачи: преобразовать логическую модель реляционной базы данных в последовательность команд SQL для создания объектов реляционной базы данных. Таким образом, проектировщик базы данных отображает отношения логической модели реляционной базы данных (сущности предметной области, представленные в нормализованной форме на ER-диаграммах) в таблицы и индексы реляционной базы данных.
Эта задача включает выполнение ряда обязательных последовательных процедур.
Создание базовых таблиц. Они представляют основные блоки хранения данных и выводятся из сущностей логической модели данных. При создании каждой таблицы проектировщик должен рассмотреть и учесть ряд факторов: определить список колонок в таблице. Колонки выводятся из атрибутов сущности логической модели данных;определить типы данных для каждой колонки. Типы данных колонок либо заданы спецификацией домена атрибута логической модели, либо определяются проектировщиком самостоятельно;определить имя таблицы. Оно может быть выведено из имени сущности логической модели базы данных или задано проектировщиком самостоятельно. Желательно в этот момент определить собственника таблицы - пользователя, который будет иметь все права доступа на таблицу, а также потенциальных пользователей таблицы;определить ряд параметров, связанных с характером хранения таблицы в физической базе данных;определить ограничения на значения колонок, исходя из ряда бизнес-правил.Создание связывающих таблиц, необходимых для разрешения отношения "многие-ко-многим", если они имеют место в логической модели базы данных. В рамках ER-диаграмм это отношение может быть уже разрешено. Тогда речь пойдет только о его реализации в командах SQL.Принять решение о способе поддержки ссылочной целостности в базе данных. Если будет решено поддерживать ссылочную целостность на уровне команд SQL, то специфицировать ограничения ссылочной целостности.
Бизнес-модель процесса проектирования
Продолжим функциональную декомпозицию процесса проектирования реляционной базы данных в рамках его второго этапа - создания логической модели базы данных.
Основной целью этапа создания логической модели базы данных является преобразование информационной модели предметной области базы данных в логическую модель реляционной базы данных. Создание логической модели базы данных предполагает решение следующих основных задач и выполнения операций в рамках таких задач:
нормализация сущностей предметной области: получить список атрибутов сущности;определить функциональные зависимости (ФЗ) в сущности;определить детерминанты сущности;определить возможные ключи отношения, в частности, рассмотрев уникальный идентификатор сущности.выполнить нормализацию сущности (преобразовать сущность в отношение);для полученного отношения назначить первичные ключи;сформировать список кандидатов на внешние ключи, если необходимо;сформировать бизнес-правила поддержки целостности сущности, если необходимо;нормализация отношений логической модели базы данных:определить степень связи сущностей;определить класс принадлежности сущности к связи; нормализовать отношение (разрешить связи);назначить первичные ключи связывающих отношений, исходя из уникального идентификатора связи и процедуры миграции ключей при нормализации;определить атрибуты связывающих отношений, если необходимо;сформировать бизнес-правила поддержки целостности связей;проверка правильности логической модели реляционной базы данных: проверка отношений на соответствие нормальной форме Бойса-Кодда;проверка отношений на свойства соединения без потерь и сохранения функциональных зависимостей;предотвращение потери данных путем миграции первичных ключей отношения и назначения внешних ключей;проверка на отсутствие незамкнутых связей;проверка на отсутствие одиночных отношений;формулировка части исходных данных для решения задачи управления ссылочной целостностью;документирование логической модели реляционной базы данных;принятие решения о реализуемости построенной логической модели реляционной базы данных;принятие решения о разработке физической модели реляционной базы данных.
Результатом проектирования логической модели базы данных является нормализованная схема отношений базы данных. Отметим, что в ходе выполнения этапа создания логической модели базы данных могут быть созданы новые объекты базы данных, не предусмотренные в информационной модели предметной области, например связывающая сущность при нормализации отношения со степенью связи "многие-ко-многим". Иногда на этом этапе принимается решение о выборочной денормализации отношений.
На рис. 3.4-рис. 3.6 представлены бизнес-модели процессов создания логической модели базы данных, нормализации сущности предметной области и нормализации отношений логической модели базы данных соответственно.
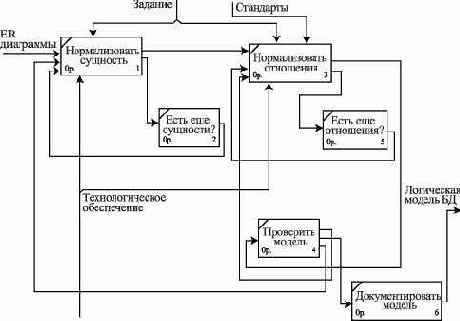
Рис. 3.4. Бизнес-модель процесса создания логической модели базы данных
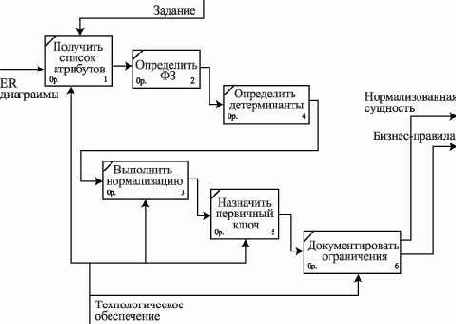
Рис. 3.5. Бизнес-модель процесса нормализации сущности
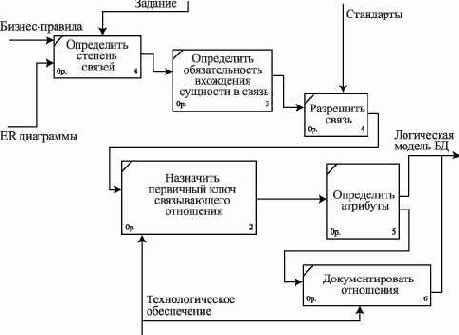
Рис. 3.6. Бизнес-модель процесса нормализации отношения
Представленные задачи составляют минимально необходимый набор задач, позволяющих спроектировать логическую модель базы данных, и могут рассматриваться как один из возможных способов организации работ в этой области.
Бизнес-модель процесса проектирования базы данных: сбор и анализ входных данных
Перейдем ко второму уровню функциональной декомпозиции процесса проектирования базы данных в рамках его первого этапа - сбор и анализ входных данных. На рис. 3.3 представлена диаграмма декомпозиции процесса проектирования базы данных второго уровня, отражающая основные задачи этапа сбора и анализа входных данных.
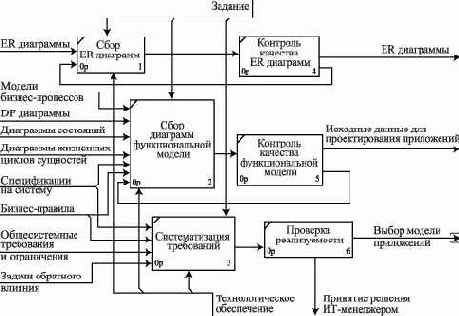
Рис. 3.3. Диаграмма декомпозициии процесса проектирования базы данных: второй уровень. Сбор и анализ входных данных
Такими задачами являются:
сбор документации с результатами анализа предметной области базы данных в виде диаграмм, спецификаций и требований;контроль качества результатов анализа предметной области базы данных;систематизация требований и спецификаций заказчика к базе данных;подготовка плана проектирования базы данных.
В ходе контроля качества основными моментами деятельности являются контроль ER-диаграмм и контроль диаграмм функциональной модели предметной области. На основании ER-диаграмм создается логическая модель реляционной базы данных; на основании диаграмм функциональной модели разрабатывается серверный код и проектируются модули приложений базы данных.
Систематизация требований заказчика к базе данных проводится с целью их адекватного распределения по этапам проектирования базы данных. Важным результатом систематизации является вывод о достаточности требований и реализуемости базы данных. Заказчик должен точно знать, что он получит и чего не получит в результате создания базы данных! Особенно важно указать, чего он не получит. Анализ требований на реализуемость базы данных в рамках конкретного ИТ-проекта служит основой для принятия решения менеджером проекта о возможности реализации проекта в целом.
Создав бизнес-модель проектирования базы данных, вы, фактически, составили план проектирования базы данных. Позициями рабочего плана являются работы бизнес-модели процесса проектирования базы данных, которые дополняются сведениями об ответственных исполнителях и сроках исполнения. Каждый уровень декомпозиции процесса уточняет этот план.
Настоящая бизнес-модель процесса проектирования базы данных представляет собой достаточно простой типичный пример бизнес-модели проектирования. В общем случае содержание бизнес-модели проектирования зависит от многих факторов: личности менеджера и состава команды проекта, объема проекта, проектных рисков и т.д.
В конце каждого модуля курса мы будем рассматривать диаграмму декомпозиции следующего этапа проектирования базы данных. Таким образом, к концу изучения курса у вас будет построена достаточно полная бизнес-модель процесса проектирования реляционной базы данных.
Что такое проектирование базы данных
Значительная часть проектов в области информационных технологий (далее ИТ-проектов) направлена на разработку и создание информационных систем, в рамках которых осуществляется обработка данных различной сложности. Целью таких проектов является разработка и создание информационной системы с базами данных. Практически во всех таких проектах решается задача проектирования баз данных определенного типа. Решение задачи проектирования повышает вероятность того, что разрабатываемая информационная система (далее - система) будет удовлетворять заданным функциональным и информационным требованиям с учетом заданных ограничений.
Примеры функциональных требований: выдача отчетов по продажам по регионам; выдача отчетов по продажам по кварталам; автоматический расчет скидок на товары при увеличении объема закупаемой партии и т.п.
Примеры ограничений: максимальное время, отпущенное на проект; количество денежных средств, которое можно на него потратить. Следует также учитывать технологические средства, доступные при реализации проекта, например требование реализации базы данных в архитектуре "файл-сервер".
В эксплуатации база данных и ее окружение должны удовлетворять набору требований по ряду укрупненных (интегрированных) параметров, таких как:
функциональность и адаптируемость;производительность обработки транзакций;пропускная способность;время реакции;безопасность.
Это далеко не полный перечень параметров, по которым выставляются требования к базам данных, однако он содержит параметры, требования по которым выставляются наиболее часто.
Такие параметры иногда находятся в противоречии друг к другу. Так, высокие требования по функциональности на данном конкретном оборудовании могут вступать в конфликт с высокими требованиями по производительности. Например, отчеты могут генерироваться в течение нескольких часов и снизить в это время реакции пользователей, работающих с системой в диалоговом режиме.
Параметры, выражающие требования к базе данных, могут ранжироваться посредством присвоения приоритетов.
Присвоение высшего приоритета требованию создать структуру данных для достижения системой максимально возможной производительности может привести к тому, что при проектировании базы данных требование обеспечить удобство работы определенной категории пользователей будет рассматриваться через призму производительности. Например, в системе бронирования авиабилетов в транснациональной авиакомпании время отклика на запрос не должно превышать 15-30 секунд. Поэтому, если это требование не будет удовлетворяться, то потребуется "разгрузить" приложение оператора.
Таким образом, процесс проектирования базы данных заключается в достижении компромиссов между функциональными, информационными, аппаратными, архитектурными и технологическими требованиями к базе данных и строится на информированном принятии решений по структуре базы данных.
Введем определение проектирования баз данных.
Определение 1. Проектирование базы данных - это поиск способов удовлетворения функциональных требований средствами имеющейся компьютерной технологии с учетом заданных ограничений.
Как правило, ИТ-проекты по созданию базы данных включают в себя следующие этапы: определение стратегии построения системы, анализ требований к базе данных, проектирование базы данных, реализация базы, тестирование и внедрение базы данных. Этап проектирования базы данных считается одним из самых сложных "размытых" этапов создания базы данных, который не имеет явно выраженного начала и окончания. По сравнению с анализом требований к базе данных или разработкой приложений, проектирование базы данных, по мнению многих ведущих специалистов, является плохо структурированной задачей. Если все этапы создания базы данных перекрываются друг с другом в своей последовательности, то этап проектирования перекрывается со всеми остальными этапами. Проектирование начинается с момента принятия стратегических решений и продолжается на этапах реализации и тестирования.
Процесс проектирования базы данных охватывает несколько основных сфер.
Проектирование объектов базы данных (таблицы, представления, индексы, триггеры, хранимые процедуры, функции, пакеты) для представления данных предметной области в базе данных.Проектирование интерфейса взаимодействия с базой данных (формы, отчеты и т.д.), т.е. проектирование приложений, которые будут сопровождать данные в базе данных и реализовывать вопросно-ответные отношения на этих данных.Проектирование баз данных под конкретную вычислительную среду или информационную технологию (архитектура "клиент-сервер", параллельные архитектуры, распределенная вычислительная среда).Проектирование баз данных под назначение системы (интеллектуальный анализ данных, OLAP, OLTP и т.д.).
Отметим, что приложения работы с базой данных проектируются одновременно с физической схемой базы данных, а не отдельно! Зачастую вычислительная среда задается в качестве входных условий проектирования, но иногда проектирование следует проводить с учетом возможного перехода в будущем на другую аппаратную платформу или технологию.
Внимание! Базы данных всегда проектируются под конкретное назначение системы.
Техника проектирования баз данных может измениться в целом и в деталях в зависимости от назначения системы. Например, следует различать проектирование систем складирования данных и проектирование так называемых OLTP-систем, ориентируемых на оперативную обработку транзакций. В данном учебном курсе рассматривается проектирование баз данных в основном для OLTP-систем. Именно на таких системах исторически сложилась техника проектирования баз данных.
Известно, что база данных:
имеет свою внутреннюю архитектуру;имеет свое собственное лингвистическое содержание;действует в рамках некоторой внешней среды;имеет свои средства взаимодействия с внешней средой;функционирует на конкретной программно-аппаратной платформе;поддерживается в рамках определенных организационно-технологических мероприятий.
Таким образом, база данных является сложным многокомпонентным объектом, объединяющим аппаратное обеспечение, программное обеспечение, информацию в виде данных и персонал.Основной задачей проектировщика базы данных является обоснованный выбор такой ее структуры, которая обеспечит согласованное взаимодействие всех ее компонентов согласно заданным функциональным требованиям в рамках заданных ограничений.
В данном курсе мы не рассматриваем вопросы анализа предметной области. Эта задача предшествует проектированию базы данных, и решают ее аналитики. Однако проектировщик баз данных должен знать результаты выполнения этой задачи и уметь правильно интерпретировать их в ходе проектирования. Результаты анализа предметной области базы данных, а именно модели данных предметной области на семантическом уровне, являются исходными данными для решения задач проектирования базы данных. Поэтому проектировщик должен знать концепции, лежащие в основе моделирования данных предметной области, и конструкции, образующие совокупность этих моделей.
Краткое рассмотрение задач создания серверного кода и подготовки скрипта
Профессиональная задача проектирования баз данных - разработка серверного кода базы данных - возникает, как правило, в многопользовательской вычислительной среде.
В многопользовательских системах пользователи совместно используют вычислительные ресурсы, в частности ресурсы дисковой памяти и оперативной памяти процессора. Вычислительные ресурсы могут быть сконцентрированы в одном месте (централизованные вычисления) или быть рассредоточенными в различных узлах, объединенных в компьютерную сеть (распределенные вычисления). СУБД в любом случае призвана координировать и осуществлять доступ пользователей к базам данных и их объектам.
Большинство современных СУБД поддерживают концепцию клиент-серверной технологии для распределенных вычислений. Это означает, что существуют концентраторы вычислений (называемые серверами), на которых выполняется наибольший объем вычислений с данными (серверы баз данных), и машины пользователей (клиенты), на которых выполняются приложения пользователей.
Приложения формируют запросы в форме команд SQL к базам данных, отправляют их серверам баз данных, получают запрашиваемые данные и обрабатывают их.
В клиент-серверной вычислительной среде приложение может взаимодействовать с сервером баз данных по другой схеме: когда приложение отправляет запрос, этот запрос обрабатывается на сервере, а приложению возвращается готовый результат.
Работа приложения по второй схеме основывается на использовании так называемого серверного кода (server-side code) - любого кода, выполняемого компьютером, на котором установлена СУБД. Ядро СУБД выполняет этот код в базе данных и возвращает приложению только результат. Например, это может быть несколько колонок строки или вычисленное значение.
Использование серверного кода может значительно сократить объем сетевого трафика и тем самым увеличить производительность базы данных в целом. Однако СУБД должна иметь встроенные средства для распознавания и обработки такого кода. Многие фирмы - производители промышленных СУБД, в том числе и Oracle, предлагают процедурные расширения SQL, с помощью которых можно выполнять построчную обработку данных, использовать циклы, сложные вычисления и операции управления данными.
PL/ SQL является таким расширением SQL в СУБД Oracle 9i. Он позволяет создавать серверный код в виде объектов реляционной базы данных, таких, как хранимые процедуры, функции, пакеты и триггеры. Проектировщик реляционной базы данных, который использует для создания базы данных СУБД Oracle, имеет возможность рассмотреть создания таких объектов с целью сокращения сетевого трафика или принять решение о переносе определенного объема обработки на сервер, особенно в тех случаях, когда эта обработка выполняется очень интенсивно. Например, несколько строк разных таблиц проверяются перед вставкой новой строки.
Таким образом, разработка серверного кода сводится к решению следующих подзадач:
принятие решения и создание хранимых процедур;принятие решения и создание функций;принятие решения и создание пакетов;принятие решения и создание триггеров.
Задача проектирования базы данных - подготовка инсталляционного скрипта для создания базы данных - в определенной степени завершающая для самостоятельной работы проектировщика базы данных. Такой скрипт - это один из главных результатов его работы.
Проектировщик базы данных, выполнив предыдущие задачи, фактически выполнил свою основную работу над созданием скрипта для базы данных. Если работа по проектированию базы данных закончена, зачем проектировщику еще что-то делать, кроме того как проанализировать и проверить проделанную работу, отредактировать окончательный вариант скрипта и создать физическую базу данных? Принято считать, что задача создания базы данных, так же как и управление базой данных, является задачей администратора базы данных. Значит, можно задокументировать проделанную работу и передать ее администратору базы данных.
Однако процесс проектирования физической модели базы данных не закончен. Из нашего рассмотрения выпали следующие вопросы:
требования по обеспечению потенциальных пользователей к базе данных и ее объектам, так называемые требования безопасности базы данных;требования к размещению и хранению объектов базы данных на физических носителях в рамках операционной системы, т.е.
Типовая бизнес-модель процесса проектирования базы данных
Процесс проектирования базы данных может быть представлен в виде модели бизнес-процессов. Обычно проектировщики не создают бизнес-модель процесса проектирования базы данных. А напрасно! Бизнес-модель процесса проектирования позволяет:
отобразить субъективное мнение проектировщика баз данных на процесс проектирования конкретной базы данных;учесть особенности ИТ-проекта, в рамках которого проектируется база данных;достаточно быстро составить план проектирования конкретной базы данных;просчитать длительность проектных работ (создать временную модель проектирования).
Рассмотрим типовую бизнес-модель процесса проектирования базы данных. На рис. 3.1 приведена контекстная диаграмма процесса проектирования базы данных.
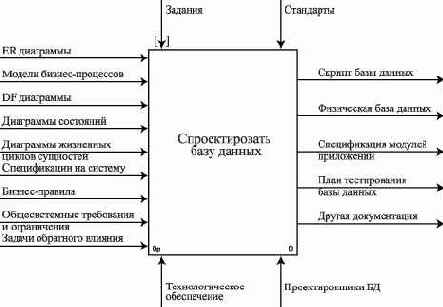
Рис. 3.1. Контекстная диаграмма процесса проектирования базы данных
Как видно из рисунка, на вход процесса проектирования базы данных подаются:
информационная модель предметной области базы данных: диаграммы "сущность-связь" (ER-диаграммы);функциональная модель предметной области базы данных: бизнес-модель процессов, диаграммы потока данных (DF-диаграммы), диаграммы состояний, - диаграммы жизненных циклов сущностей, спецификации на системы (требования), бизнес-правила;общесистемные требования и ограничения;задачи обратного влияния.
Могут быть представлены и другие документы.
Примечание. Под задачами обратного влияния здесь понимается совокупность проблем, которые возникают в процессе разработки приложений базы данных, ее тестирования, опытной и промышленной эксплуатации и приводят к модификации физической модели базы данных. Примером такой задачи является настройка операторов SELECT с целью увеличения производительности выборки.
На выходе процесса проектирования базы данных формируются следующие результаты:
физическая модель базы данных, которая может быть преобразована в скрипт для создания базы данных;физическая база данных;спецификация модулей приложений базы данных;план тестирования базы данных.
По требованию может быть разработана и другая документация.
Продолжим функциональную декомпозицию процесса проектирования базы данных. На рис. 3.2 приведена диаграмма декомпозиции процесса проектирования базы данных первого уровня, отражающая основные наиболее крупные профессиональные задачи (этапы) проектирования базы данных.
Внимание! В настоящем курсе рассматривается минимально необходимый, с точки зрения автора, набор задач, позволяющий спроектировать реляционную базу данных.
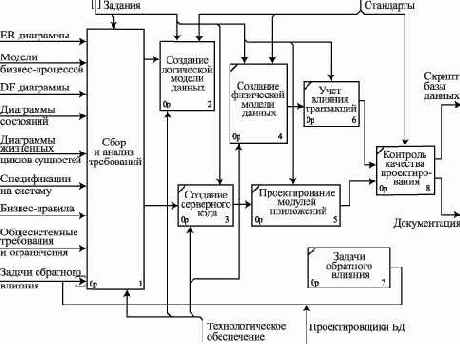
Рис. 3.2. Диаграмма декомпозиция процесса проектирования базы данных: первый уровень
Такими задачами (этапами) являются:
сбор и анализ входных данных;создание логической модели базы данных;создание физической модели базы данных: внутренняя схема;создание физической модели базы данных: учет влияния транзакций;создание серверного кода;проектирование модулей приложений базы данных;контроль качества проектирования базы данных;задачи обратного влияния.
Сбор и анализ входных данных - это начальный этап проектирования, на котором осуществляется сбор и контроль качества результатов анализа предметной области базы данных, готовится план проектирования базы данных.
Создание логической модели базы данных - это этап, на котором на основании информационной модели предметной области базы данных создается логическая структура базы данных, независимая от ее реализации.
Создание физической модели базы данных: внутренняя схема - это этап, на котором на основании логической модели базы данных создается физическая структура базы данных, зависимая от ее реализации. На этом этапе выполняется преобразование отношений логической модели реляционной базы данных в команды создания объектов физической базы данных, в результате чего создается так называемая внутренняя схема базы данных. Дополнительно может быть создана так называемая внешняя схема базы данных, которая отражает точку зрения пользователей на данные в базе данных. Полученный скрипт может быть применен для создания физической базы данных.
Создание физической модели базы данных: учет влияния транзакций - это этап, на котором анализируются возможные транзакции системы, выполняется, в случае необходимости, денормализация отношений для обеспечения более высокой производительности базы данных.
Продолжим функциональную декомпозицию процесса проектирования базы данных. На рис. 3.2 приведена диаграмма декомпозиции процесса проектирования базы данных первого уровня, отражающая основные наиболее крупные профессиональные задачи (этапы) проектирования базы данных.
Внимание! В настоящем курсе рассматривается минимально необходимый, с точки зрения автора, набор задач, позволяющий спроектировать реляционную базу данных.
Рис. 3.2. Диаграмма декомпозиция процесса проектирования базы данных: первый уровень
Такими задачами (этапами) являются:
сбор и анализ входных данных;создание логической модели базы данных;создание физической модели базы данных: внутренняя схема;создание физической модели базы данных: учет влияния транзакций;создание серверного кода;проектирование модулей приложений базы данных;контроль качества проектирования базы данных;задачи обратного влияния.
Сбор и анализ входных данных - это начальный этап проектирования, на котором осуществляется сбор и контроль качества результатов анализа предметной области базы данных, готовится план проектирования базы данных.
Создание логической модели базы данных - это этап, на котором на основании информационной модели предметной области базы данных создается логическая структура базы данных, независимая от ее реализации.
Создание физической модели базы данных: внутренняя схема - это этап, на котором на основании логической модели базы данных создается физическая структура базы данных, зависимая от ее реализации. На этом этапе выполняется преобразование отношений логической модели реляционной базы данных в команды создания объектов физической базы данных, в результате чего создается так называемая внутренняя схема базы данных. Дополнительно может быть создана так называемая внешняя схема базы данных, которая отражает точку зрения пользователей на данные в базе данных. Полученный скрипт может быть применен для создания физической базы данных.
Создание физической модели базы данных: учет влияния транзакций - это этап, на котором анализируются возможные транзакции системы, выполняется, в случае необходимости, денормализация отношений для обеспечения более высокой производительности базы данных.
Настоящий курс лекций построен таким
Настоящий курс лекций построен таким образом, чтобы материал этой лекции изучался дважды: первый раз с целью установочного характера, чтобы была понятна логика следующих лекций; второй раз - после последней лекции с целью ответа на вопросы и задачи теста.